版权声明:成都软件测试交流群,339614248,欢迎你的加入 https://blog.csdn.net/louishu_hu/article/details/83342704
既然要介绍该算法,我们就简单介绍一下欧式距离
这个应该是我们初中就学过的了,2点之间的距离就是它的多维空间里面每个维度的坐标的差的平方之和,再开方
公式就是
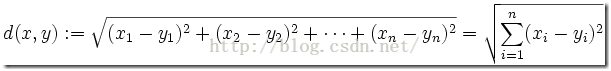
OK,我们现在按照分类的基本原则,把所有的样本集都放进我们的坐标系里面来,有多少特征,我们就建立几维的空间坐标系。
这里的几维就对应上面的x1,x2....xn以及y1,y2......yn所确定的点
然后通过计算直线距离,来进行距离排序。
我们要进行分类的训练样本越接近那个特征,或者说那些特征的权重比较之下的新特征,那么我们就可以把它分类到那个类别下。
这里的K,就对应已经明确类别的哪些空间元素了。
OK,那我们来讨论一下K的大小,你是希望比较的越多呢来显示更精确,还是比较的不那么多,最快得到类别
打个比方吧,把人类放进浩瀚的宇宙,你怎么确定你身边的这个生物就是人呢?
宇宙中有那么多的元素,你需要把所有的元素都拿来比较吗?
我的天,那你要玩到什么时候,宇宙级的计算机也要认怂了。。
所以我们需要缩小范围,不能无穷尽的去放大K。。。。。。。。。。。。
我们就一般情况下,和你公司周围几个人比较就ok了,一般默认几个人呢?20!20就足够了。
所以我们默认就是K=20.。。。。。。。。。。当然也要视情况而言,你要先对你的数据有个了解。
看看有没有非洲人,欧洲人,变性人出现的可能,没有,那就好办了,一群中国人。。。那就随便晒20个附近的阿猫阿狗和某些人进来比较就欧拉
先去下numpy函数库啦,不下也可以,反正你牛逼!
下期就直接用代码演示下相关算法如何实现的