机器学习基石 作业一
1-5 省略
- 测试N和N+L分别为奇偶的情况。选择两个都是向下取整的。
- 因为 中对应的N个例子的结果都和 一样,因此只有定义域里剩下的L个x对应的结果会有变化,每个都有两种情况,因此选择 。
- 选择此项。
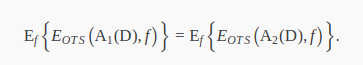
因为两个算法的结果都只对应了一种可能的真实 ,也就是说假设有N种可能的 ,每个算法的结果都有N-1个对应的错误情况,且每种情况概率相等。因此对 求的错误率期望相等。这也是No Free Lunch的一种表现,没有一种算法的结果一定比另一个好。 - 从筐子里抓小球,每种小球出现概率0.5,抓10个刚好各有5个的概率。选0.24。
- 和上题类似,0.39。
- 抓10个小球,只有1个或0个目标种类的概率。
- 带入公式即可。 。结果是
- 橘色1和绿色1概率均为0.5,结果是1/32。
- 四种筛子ABCD。1全为橘色筛子只能选BC两种,2选AC,3选BC,4选AD,5选BD,6选AD。也就是每次的筛子里只有小于两种筛子,且筛子为AC,AD,BC,BD四种组合时才可以。对应概率为 ,其中5个筛子里只有一种筛子的情况各多算了一次,即结果为 。
import numpy as np
import requests
import pandas as pd
def getData(url):
content = requests.get(url).content
content = content.decode('utf-8')
x = []
y = []
content = content.split('\n')
for line in content[:-1]:
xs,ys = line.split('\t')
y.append(int(ys))
x1 = xs.split(' ')
for i in range(4):
x1[i] = float(x1[i])
x.append([1]+x1)
x = np.array(x)
y = np.array(y)
return x,y
def oneIteration(x,y,w,iteration):
update_num = 0
for i in range(len(x)):
mul = np.dot(w,x[i])
if mul > 0:
res = 1
else:
res = -1
if res != y[i]:
w += y[i]*x[i]
update_num += 1
print("update",update_num,"times in",iteration,"iteration")
return update_num
def PLA():
url = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_15_train.dat'
x,y = getData(url)
w = np.array([0,0,0,0,0],dtype=float)
iteration = 1
while(oneIteration(x,y,w,iteration) != 0):
iteration += 1
print("update finished!")
if __name__ == '__main__':
PLA()
import numpy as np
import requests
import pandas as pd
import random
def getData(url):
content = requests.get(url).content
content = content.decode('utf-8')
x = []
y = []
content = content.split('\n')
for line in content[:-1]:
xs,ys = line.split('\t')
y.append(int(ys))
x1 = xs.split(' ')
for i in range(4):
x1[i] = float(x1[i])
x.append([1]+x1)
x = np.array(x)
y = np.array(y)
return x,y
def oneRandomIteration(x,y,w,iteration):
update_num = 0
indexs = list(range(len(x)))
random.shuffle(indexs)
for i in indexs:
mul = np.dot(w,x[i])
if mul > 0:
res = 1
else:
res = -1
if res != y[i]:
w += 0.5*y[i]*x[i]
update_num += 1
print("update",update_num,"times in",iteration,"iteration")
return update_num
def PLA():
url = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_15_train.dat'
x,y = getData(url)
all_update_sum = 0
for t in range(2000):
w = np.array([0,0,0,0,0],dtype=float)
iteration = 1
update_sum = 0
update_num = oneRandomIteration(x,y,w,iteration)
while(update_num != 0):
update_sum += update_num
iteration += 1
update_num = oneRandomIteration(x,y,w,iteration)
all_update_sum += update_sum
print("time:",t,"update finished!")
print("average update number is",all_update_sum/2000)
if __name__ == '__main__':
PLA()
这里我实现的时候有个卡壳的地方造成了死循环。就是实现pocket PLA的时候,寻找错误样本使用的是一直在更新的系数 而不是当前最好系数 。
而且 是一直在更新的,只不过是当它错误率更低的时候存为新的 而已。我实现时错误理解了算法,以为是在 的基础上只进行一次更新之后就和 继续比较,这是不对的, 一直在更新。
import numpy as np
import requests
import pandas as pd
import random
def getData(url):
content = requests.get(url).content
content = content.decode('utf-8')
x = []
y = []
content = content.split('\n')
for line in content[:-1]:
xs,ys = line.split('\t')
y.append(int(ys))
x1 = xs.split(' ')
for i in range(4):
x1[i] = float(x1[i])
x.append([1]+x1)
x = np.array(x)
y = np.array(y)
return x,y
def pocketIteration(x,y,w,times):
update_num = 0
indexs = list(range(len(x)))
w1 = w
while times > 0:
random.shuffle(indexs)
for i in indexs:
res = sign(w1,x[i])
if res != y[i]:
w1 = w1 + y[i]*x[i]
times -= 1
error1 = verification(x,y,w1)
error0 = verification(x,y,w)
if error0 > error1:
w = w1
if times == 0:
break
print("remain",times,"times update!")
if times == 0:
break
return w
def verification(x,y,w):
len_of_x = len(x)
error_num = 0
for i in range(len_of_x):
res = sign(w,x[i])
if res != y[i]:
error_num += 1
#print("error rate:",error_num)
return error_num/len_of_x
def sign(w,x):
mul = np.dot(w,x)
if mul > 0:
return 1
else:
return -1
def PLA():
train_url = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_train.dat'
test_url = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw1_18_test.dat'
train_x,train_y = getData(train_url)
test_x,test_y = getData(test_url)
error_rate_sum = 0
for t in range(2000):
w = np.array([0,0,0,0,0],dtype=float)
w = pocketIteration(train_x,train_y,w,100)
error_rate_sum += verification(test_x,test_y,w)
print("time:",t,"update finished!")
print("average error rate is",error_rate_sum/2000)
if __name__ == '__main__':
PLA()