机器学习基石 作业二
- 计算一下本来预测对与预测错时加上噪音导致的错误率然后相加即可。

- 选择一个
的值让
的系数为0。

- 根据VC bound 公式带入计算即可,N=46000的时候error最接近0.05。下面的代码可以计算不同的N与目标error之间的差距。
def compute(N,err):
delta = 0.05
dvc = 10
res = np.sqrt(8/N*np.log(4*pow(2*N,dvc)/delta))
return res-err

- 编程计算这几个不等式的上限。感觉不是很有意思。将N=10000和N=5的时候分别带入看哪个最小即可。有两个隐函数需要使用sympy.solve来当做等式解方程。代码如下:
dvc = 50
delta = 0.05
N = 5
def origiVC():
return np.sqrt(8/N*np.log(4*pow(2*N,dvc)/delta))
def rpVC():
r1 = np.sqrt(2*np.log(2.0*N*pow(N,dvc))/N)
r2 = np.sqrt(2/N*np.log(1/delta))
return r1+r2+1/N
def pvVC():
epsilon = sympy.symbols('epsilon')
r1 = sympy.solve(epsilon-sympy.sqrt(1/N*sympy.log(6*((2*N)**dvc)/delta)),epsilon)
return r1
def dVC():
epsilon = sympy.symbols('epsilon')
r1 = sympy.solve(epsilon-sympy.sqrt(0.5/N*(4*epsilon*(1+epsilon) + np.log(4)+dvc*sympy.log(N**2.0)-np.log(delta))),epsilon)
return r1
def vVC():
return np.sqrt(16/N*(np.log(2)+dvc*np.log(N*1.0)-np.log(np.sqrt(delta))))
if __name__ == '__main__':
print(origiVC())
print(rpVC())
print(pvVC())
print(dVC())
print(vVC())

- 做错了。看到个别人的一个解释。
https://blog.csdn.net/zyghs/article/details/78762070 这个老哥的博客里有这题稍微详细的解释。还是找规律写出通式,高中数学真重要.jpg


- 根据公式,VC维是3
- 还是将N=1开始慢慢找,发现N=3时能shatter的也是7种。因此得到答案。这相当于是一个二维的positive interval的题目。可以看ppt上关于Positive interval的假设,N个点,可以选择N+1个位置作为interval的起点或终点。每次的interval需要一个终点一个起点,也就是
,或者起点终点都在最边上,这两种是一种情况,都分为全负因此再加一。

- 跟视频里讲的一样,d维感知机。答案是d+1。

- 这个题目主要是理解题目意思比较费劲。s是一个d维向量的集合,而且每个d维向量对应一个+1或一个-1。因此无论N多大,能够将样例最多分类为
种结果,也就是VC维是
。

- 三角波调节上下平移取绝对值之后的正负号。好像对于所有N都能够将其完全shatter。因此事无穷大。

- 选项1:可以无限递归至N=1,显然不对。 选项2:是个常数不对。选项3:应该是个[
]之间的数,所以可以。选项4:指数是
,不能保证是上界。

- 其它选项都没有疑问。第二个选项确实不太懂。不过第五题引用的博客里那个老哥说可能是因为这个函数是跳跃式地增长的。而一个growth函数应该是连续增长的(只要VC维不是0),应该是排列组合的一个性质。我觉得老哥说得对。

- 交集的部分可能是空,最好的情况也就是等于VC维最小的一个假设集合。不是很好解释,自行体会。
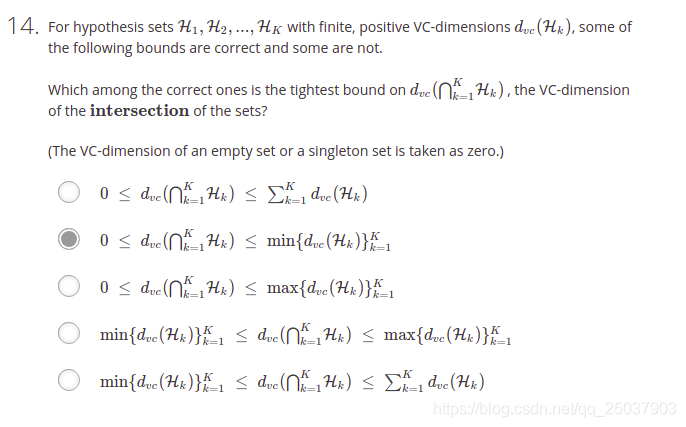
- 这个并集的下界很好理解,最小也是所有假设集合里VC维最大的那个的值。而稍微难以解释。如果每一个假设集合都没有交集,因此显然他们的并集的vc维上界需要将所有的vc维都加起来,但是这样还不够。因为并集了以后不同的假设集合之间的组合也会带来一些新的“自由度”。所以应该还有一项。至于为啥是K-1不是非常明确。

- 将s是正号以及负号,
大于0还是小于0的情况进行组合一下,简单计算得出结果。后面几题需要理解算法流程进而实现。

17-18 结果分别是0.15 0.25。需要理解算法的具体实现。这个算法主要是选择正负号s和分隔点 。而分隔点可以直接根据每一个数据点 的位置进行选择。比如题目里有20个数据,那么将这20个数据排序好,之后将每一个点的坐标作为 来比较 选出最优结果。代码如下:
import numpy as np
import random
def genData(N,noise):
x = []
y = []
for i in range(N):
x1 = random.uniform(-1,1)
prob = random.uniform(0,1)
if prob < noise:
y1 = -sign(x1,True)
else:
y1 = sign(x1,True)
x.append(x1)
y.append(y1)
return np.array(x),np.array(y)
def errorRate(x,y,s,theta,h):
errorNum = 0
for i in range(len(x)):
if y[i] != h(x[i],s,theta):
errorNum += 1
return errorNum/len(x)
def hFunc(x,s,theta):
if s:
return sign(x-theta,s)
else:
return -sign(x-theta,s)
def sign(v,s):
if v == 0:
return s
elif v < 0:
return -1
else:
return 1
def trainDecisionStump(N,noise):
x,y = genData(N,noise) #N=20,noise=0.2
E_in = 1
best_s = True
best_theta = 0
thetas = np.sort(x) #排序x用来作为备选的theta
ss = [True,False] #先遍历s是正的时候
for theta in thetas:
for s in ss:
E = errorRate(x,y,s,theta,hFunc)
if E < E_in:
E_in = E
best_s = s
best_theta = theta
index, = np.where(thetas == best_theta)
if index[0] == 0:
best_theta = (-1+best_theta)/2
else:
best_theta = (thetas[index[0]-1]+best_theta)/2
E_out = computeEout(best_s,best_theta)
return E_in,E_out
def computeEout(s,theta):
if s:
return 0.5+0.3*(np.abs(theta)-1)
else:
return 0.5-0.3*(np.abs(theta)-1)
def main():
iteration = 5000
N = 20
noise = 0.2
err_in_sum = 0
err_out_sum = 0
for i in range(iteration):
err_in, err_out = trainDecisionStump(N,noise)
err_in_sum += err_in
err_out_sum += err_out
if i%100 == 99:
print("iteration: ",i+1)
print("total errorRate in sample is",err_in_sum/iteration)
print("total errorRate out of sample is",err_out_sum/iteration)
if __name__ == '__main__':
main()
19-20 多维形式的算法。需要理解多维算法的流程。每一维度上都选择一个最好的函数。而最终在这些不同维度最好的函数里面选择一个最好的,并且以这个作为最终的多维函数。也就是说最终只选择某个维度作为分类维度,其它维度都舍弃掉了。最终结果是0.25,0.35。代码如下:
import numpy as np
import random
import requests
def getData(url):
content = requests.get(url).content
content = content.decode('utf-8')
x = []
y = []
content = content.split('\n')
for line in content[:-1]:
data = line.split(' ')
y.append(int(data[-1]))
x1 = data[1:-1]
for i in range(len(x1)):
x1[i] = float(x1[i])
x.append(x1)
x = np.array(x)
y = np.array(y)
return x,y
def errorRate(x,y,s,theta,h,dimension):
errorNum = 0
for i in range(len(x)):
if y[i] != h(x[i][dimension],s,theta):
errorNum += 1
return errorNum/len(x)
def hFunc(x,s,theta):
if s:
return sign(x-theta,s)
else:
return -sign(x-theta,s)
def sign(v,s):
if v == 0:
return s
elif v < 0:
return -1
else:
return 1
def trainDecisionStump(x,y):
dimensions = len(x[0])
E_in = 1
best_s = True
best_theta = 0
best_dim = 0
for dim in range(dimensions):
thetas = np.sort(x[:,dim]) #排序x用来作为备选的theta
ss = [True,False] #先遍历s是正的时候
for theta in thetas:
for s in ss:
E = errorRate(x,y,s,theta,hFunc,dim)
if E < E_in:
E_in = E
best_s = s
best_theta = theta
best_dim = dim
return best_s,best_theta,best_dim,E_in
def main():
trainUrl = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw2_train.dat'
testUrl = 'https://www.csie.ntu.edu.tw/~htlin/mooc/datasets/mlfound_math/hw2_test.dat'
trainX,trainY = getData(trainUrl)
testX,testY = getData(testUrl)
s,theta,dim,err_in = trainDecisionStump(trainX,trainY)
err_out = errorRate(testX,testY,s,theta,hFunc,dim)
print("total errorRate in sample is",err_in)
print("total errorRate out of sample is",err_out)
if __name__ == '__main__':
main()