大家好,我是Mac Jiang,今天和大家分享Coursera-NTU-機器學習基石(Machine Learning Foundations)-作业三 Q6-10的C++实现。虽然有很多大神已经在很多博客中给出了Phython的实现,但是给出C++实现的文章明显较少,这里为大家提供一条C++实现的思路!我的代码虽然能够得到正确答案,但是其中可能有某些思想或者细节是错误的,如果各位博友发现,请及时留言纠正,谢谢!再次声明,博主提供实现代码的原因不是为了让各位通过测试,而是为学习有困难的同学提供一条解决思路,希望我的文章对您的学习有一些帮助!
本文出处:http://blog.csdn.net/a1015553840/article/details/51084922
1第十三题

(1)题意:给定的target fuction的表达式如上图所示,他是用一个圆圈做二元分类。我们的工作是在X=[-1,1]x[-1,1]上随机产生1000个点,利用f(x1,x2)计算它的值,然后在基础上添加10%的噪声(二元分类的噪声就是把10%的样本的y值取相反数)。如果不做feacher transform 直接利用数据做线性回归,利用得到的参数做线性分类器,问此事得到的Ein是多少。运行1000次取平均值。
(2)分析:首先要随机产生训练样本并添加噪声,对于C++如何随机产生随机样本和噪声我们以前的代码中就已经说过了,这里不再重复。
其次,我们要利用训练样本计算线性回归。
最后,我们用得到的线性回归参数w作为二元分类器的参数,计算sign(w*x)得到预测值,计算他与y的0/1错误,得到错误率EiN
提示:由于线性回归需要用到求pseudo-inverse的操作,这里要求逆矩阵,这里要是自己写逆矩阵的算法比较复杂,可以直接调用已经写好的C++库。比较常用的C++库有eigen,cuda等等,本人用的是eigen。如果你嫌复杂,可以直接使用Matlab实现本题,操作会简单的多。
对于eigen的用法有很多前人已经写过,比较好的链接有:http://blog.csdn.net/augusdi/article/details/12907341.其实我们用到的只是其中的一些很基础的操作,最重要的是求逆矩阵和求广义逆矩阵的操作,大家不妨看看。
对于第13题的代码和第14题的很像,只要把第14题的featureTransform操作去掉就可以了,所以这里不再附上。
(3)答案:0.5
2.第十四题

(1)题意:在第13题,直接利用逻辑回归做分类是很不理想的,错误率为50%,没有实际意义。但是我们可以先进行特征转换,正确率就会高很多。特征转化的操作也很简单,上课老师都说过,这里就不再累述。
(2)分析:具体的代码实现如下。其中,(Xtest,ytest)是第15题才需要进行的操作,为了简洁都写在一起了。
#include "stdafx.h"
#include<iostream>
#include<Eigen/Eigen>//C++下的一个常用的矩阵运算库
using namespace Eigen;
using namespace std;
#define X1min -1 //定义第一维度的最大最小值
#define X1max 1
#define X2min -1//定义第二维度的最大最小值
#define X2max 1
#define N 1000//定义样本数
int sign(double x){
if(x <= 0)return -1;
else return 1;
}
void getRandData(Matrix<double,N,3> &X,Matrix<double,N,1> &y){ //在(X1min,X1max)x(X2min,X2max)区间初始化点
for(int i = 0; i < N; i++){
X(i,0) = 1.0;
X(i,1) = double(X1max - X1min) * rand()/RAND_MAX - (X1max - X1min)/2.0;
X(i,2) = double(X2max - X2min) * rand()/RAND_MAX - (X2max - X2min)/2.0;
y(i,0) = sign(X(i,1)*X(i,1) + X(i,2)*X(i,2) - 0.6);
}
}
void getNoise(Matrix<double,N,3> &X,Matrix<double,N,1> &y){//加入噪声
for(int i =0; i < N; i++)
if(rand()/RAND_MAX < 0.1)
y(i,0) = - y(i,0);
}
void transform(Matrix<double,N,3> &X,Matrix<double,N,6> &Z){//将X空间转换为Z空间
for(int i = 0; i < N; i++){
Z(i,0) = 1;
Z(i,1) = X(i,1);
Z(i,2) = X(i,2);
Z(i,3) = X(i,1) * X(i,2);
Z(i,4) = X(i,1) * X(i,1);
Z(i,5) = X(i,2) * X(i,2);
}
}
void linearRegression(Matrix<double,N,6> &Z,Matrix<double,N,1> &y,Matrix<double,6,1> &weight){//逻辑回归计算,得参数weight
weight = (Z.transpose() *Z).inverse() * Z.transpose() * y;
}
double calcuE(Matrix<double,N,6> &Z,Matrix<double,N,1> &y,Matrix<double,6,1> &weight){//计算E_in
double E_in = 0.0;
Matrix<double,N,1> temp = Z * weight;
for(int i = 0; i < N; i++)
if((double)sign(temp(i,0)) != y(i,0))
E_in++;
return double(E_in/N);
}
void main(){
int seed[1000];//种子
double total_Ein = 0.0;
double total_Eout = 0.0;
Matrix<double,N,3> X;//X组成的矩阵
Matrix<double,N,3> Xtest;//测试样本
Matrix<double,N,6> Z;//Z组成矩阵
Matrix<double,N,6> Ztest;//测试样本
Matrix<double,N,1> y;//y组成的向量
Matrix<double,N,1> ytest;//测试样本
Matrix<double,6,1> weight;//参数weight
Matrix<double,6,1> totalWeight;
totalWeight<<0,0,0,0,0,0;
for(int i = 0; i < N; i++)//进行1000次,每次需要1个种子,所以先利用rand初始化种子
seed[i] = rand();
for(int k =0; k < N; k++){
srand(seed[k]);//每次取一个种子进行试验
getRandData(X,y);//得到随机样本
getNoise(X,y);//添加噪声
getRandData(Xtest,ytest);
getNoise(Xtest,ytest);
transform(X,Z);
transform(Xtest,Ztest);
linearRegression(Z,y,weight);//线性回归计算参数weight
total_Ein += calcuE(Z,y,weight);//计算每次E_in错误和
total_Eout += calcuE(Ztest,ytest,weight);
totalWeight += weight;
cout<<"k="<<k<<",Ein = "<<calcuE(Z,y,weight)<<",Eout = "<<calcuE(Ztest,ytest,weight)<<endl;
}
cout<<"Average E_in:"<<total_Ein / 1000.0<<endl;
cout<<"Average E_out:"<<total_Eout / 1000.0<<endl;
cout<<totalWeight/1000;
}(3)答案:最后一项。其实用脑子想想就知道是最后一个,应为f(x1,x2)=sign(x1^2+x2^2-0.6)是一个圆,那么得到的肯定也差不多是个圆。加上噪声可以与原来的圆稍微偏离一些,但不会太过分。
15.第十五题

(1)题意:在14题得到的最优w的基础上,我们利用产生训练样本的方法一样产生1000个测试样本,计算误差。重复1000次求平均
(2)实现:已经在14题给出
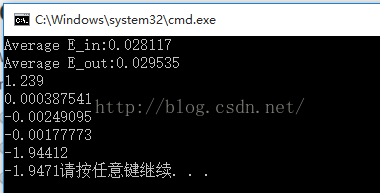
Average E_in:训练样本平均误差
Average E_out:测试样本平均误差
最下面的六行数据是第14题的w的六个参数
(3)答案:0.1
本文出处:http://blog.csdn.net/a1015553840/article/details/51084922