机器学习基石 Lecture5: Training versus Testing
Recap and Preview
到上一课为止,讲到了机器学习整体的流程。在假设函数空间
大小是有限的而且样本
数量
足够大时,对于任何的算法
,得到的结果
的样本内的错误率等于样本外的错误率(PAC)。
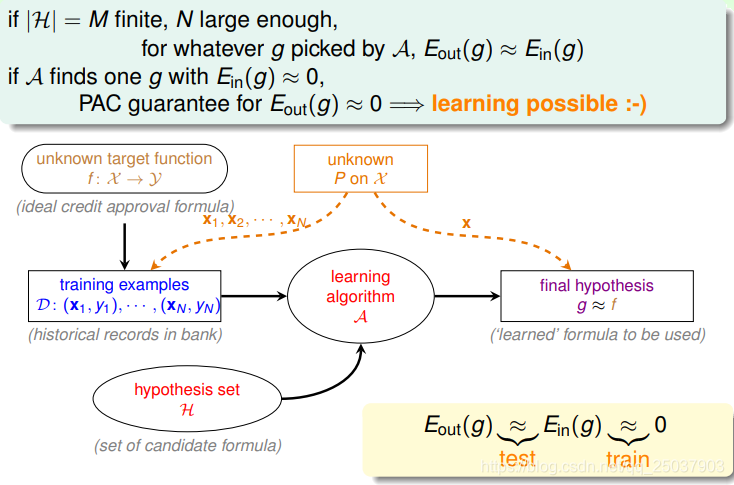
在整个的过程中有两个核心问题:1.是否能够保证样本内错误率
足够接近样本外错误率
? 2.是否能够使得
足够小?在这里吗假设空间
的大小
起到了很大的作用。如下图所示:

造成
无穷大时问题无法解决的原因在于Hoeffding Inequality在计算时的一步放缩,如果我们能够在那个不等式中将
替换成一个有限大小的值那么问题就得到了解决。

Effective Number of Lines
不等式中的
是在计算数据集
是一个比较坏(也就是样本内外错误率相差过大)的概率的联合上限时引入的,是一个非常宽松的放缩。

这个不等式右边是将每一个假设遇到的“坏”数据集的概率直接相加得到的。但是实际上,对于比较接近的假设函数,遇到"坏“数据集的概率分布是有很大的重合而不是完全分开的,如下图:

为了充分利用不同假设对应概率的重叠,可以选择将不同的假设函数进行分类。
Effective Number of Hypotheses
考虑PLA算法中线的类别。
- 当样本只有1个点时,假设函数有2类,但是有无数条。分别是将这个点划分为正或负。
- 当样本有2个点,假设函数有4类。
- 样本有3个点,可能有8类。但是如果三个点共线,那就只有6类。
- 而对应4个点时,分割线最多也只有14类。
因此对于有
个点的数据集来说,最多也只有
种线的划分。把线的类别数量定义为有效数量(effective number of lines, effective(N))。也就是可以在上面的Hoeffding Inequality的推导的右侧使用这个数字替代
:

那么只要这个数字远远小于
那么我们的目的就达到了。
现在定义一个假设函数将所有数据集分类的结果叫做一个dichotomy。如下图所示:

那么一个dichotomy对应的就是一类的假设函数,在PLA算法里就是同一类的分割线或分隔面。于是假设空间对应的dichotomies的大小
就是上面的有效线的数量,也就可以用来替代不等式中的
。
因为dichotomies的大小依赖于数据集
,因此定义一个增长函数(growth Function)
来去掉这个依赖性:

下面举几个例子说明这个函数:
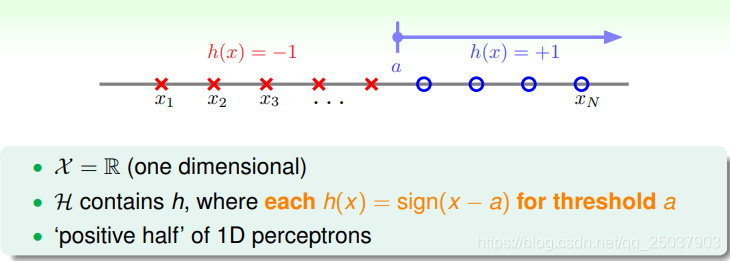
在Positive Rays的问题里,
。远小于
。
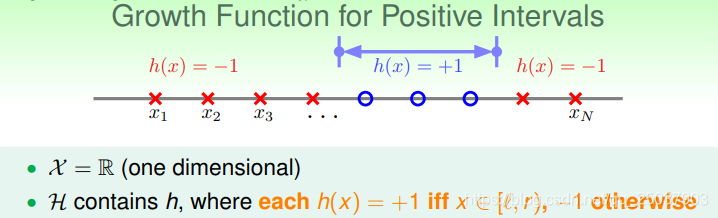
在一个范围函数作为分隔的问题里,
。远小于
。
在一个二维平面里,如果把一个凸集合的范围内的点作为正例,那么这个假设空间对应的
。

总结下来这几种情况为:

如果使用这个增长函数替代不等式中的
,那么如果它是多项式的,就满足条件,如果是指数级的,就会没有意义。
Break Point
我们还记得在二维感知机的情况下,当
时最大的类别也一定小于16,也就是
。我们把第一个不等于
的点叫做这个假设空间的Break Point。

总结以下几种情况,似乎可以看到第一个Break Point点与Growth Function的增长速度的关系,以后的课程里进行进一步的证明。
