深度强化学习cs294 Lecture5: Policy Gradients Introduction
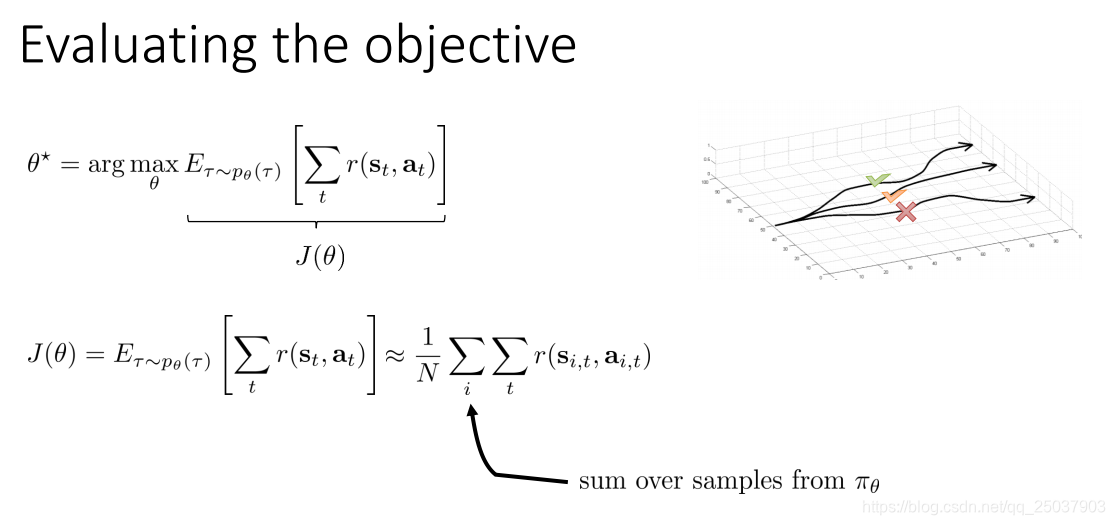
首先回顾强化学习的目标。强化学习问题可以看成一个建立在马尔科夫决策过程之上的序列决策问题,其中要调整的部分是采取动作的策略函数,现在很多都使用神经网络来得到。强化学习的目标就是找到一个策略,能够最大化一个序列反馈和的期望值。

而对于序列反馈期望值的计算可以分为两种情况,一种是有限步数的情况,一种是无限步数的情况。这两种情况实际上是一样的,不过写为期望的形式略有不同。无限步长的情况也可以根据一个最终的稳定分布写为类似的形式。今天我们只关注有限步长的形式,在后面讲到actor-critic算法时会讲到有限步延伸到无限步。实际上有限步长里最优的策略是个时变函数,当然我们这里不考虑时变这一点,依然当做是一个与时间无关的函数。

因为序列的概率分布实际上无法得到,因此我们一般都是用采样的方式来近似得到期望的结果。
1. The policy gradient algorithm
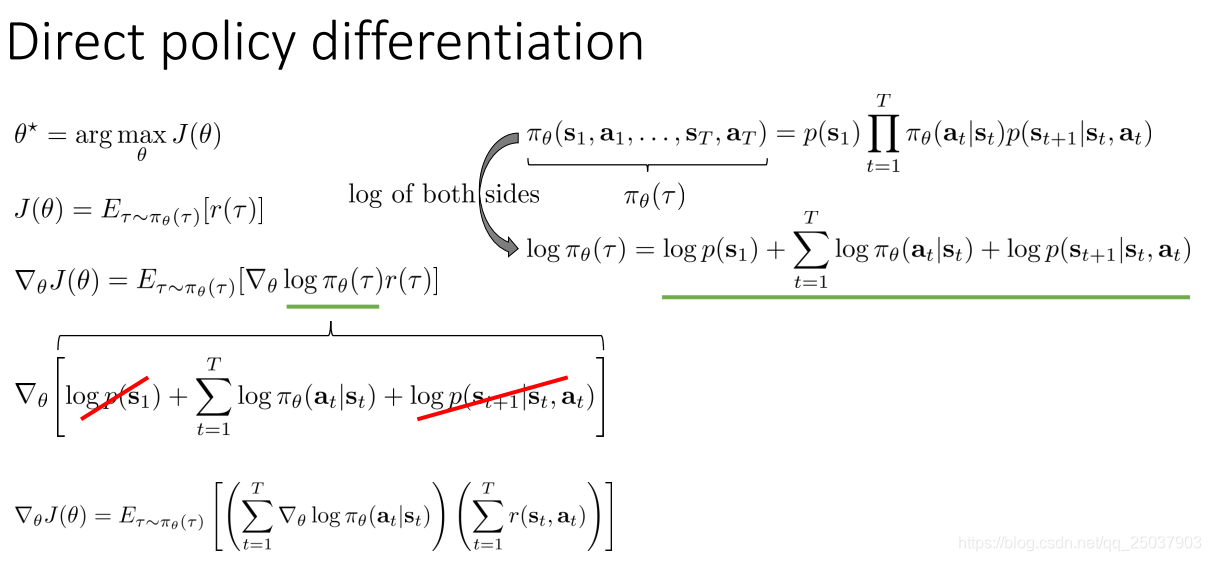
我们知道了强化学习的目标是求得最大化期望反馈和的策略参数,因此有一种比较直接的方式就是对目标函数进行直接梯度上升法求解。
如图所示,其中对策略求导的部分用对数求导的等式可以让梯度也写为一个期望的形式:

因为公式里一直用的是序列
的概率,而序列
的概率实际上是一堆乘积的形式。写开之后求log变为和的形式,再求导去掉部分无关项:
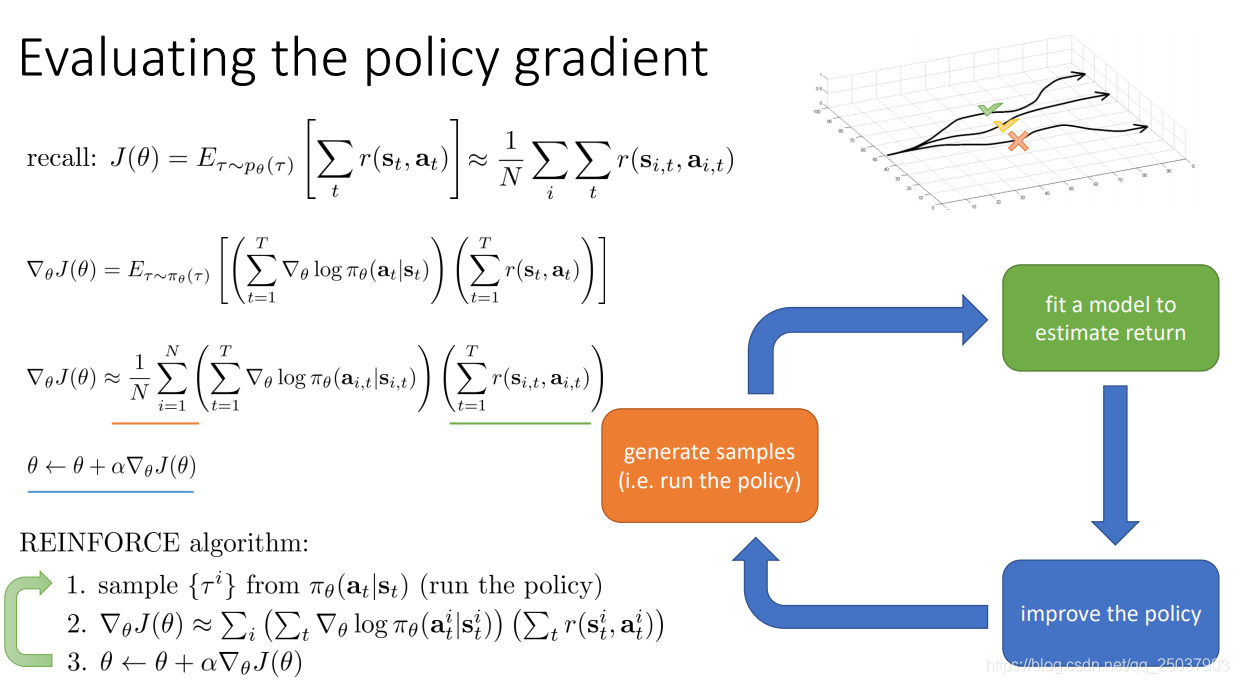
期望值括号里的部分已经可以得到,但是期望依然无法求解。不过还是很简单地使用采样逼近期望值即可,于是直接进行policy gradient的算法就得到了,这个算法也叫作REINFORCE算法:
2. What does the policy gradient do?
来进一步的观察这个策略梯度的算法。用之前模仿学习里面讲到的例子,我们发现与直接进行最大似然的方法相比,策略梯度法的梯度仅仅是相当于对每一项使用了对应序列反馈值和来进行加权:
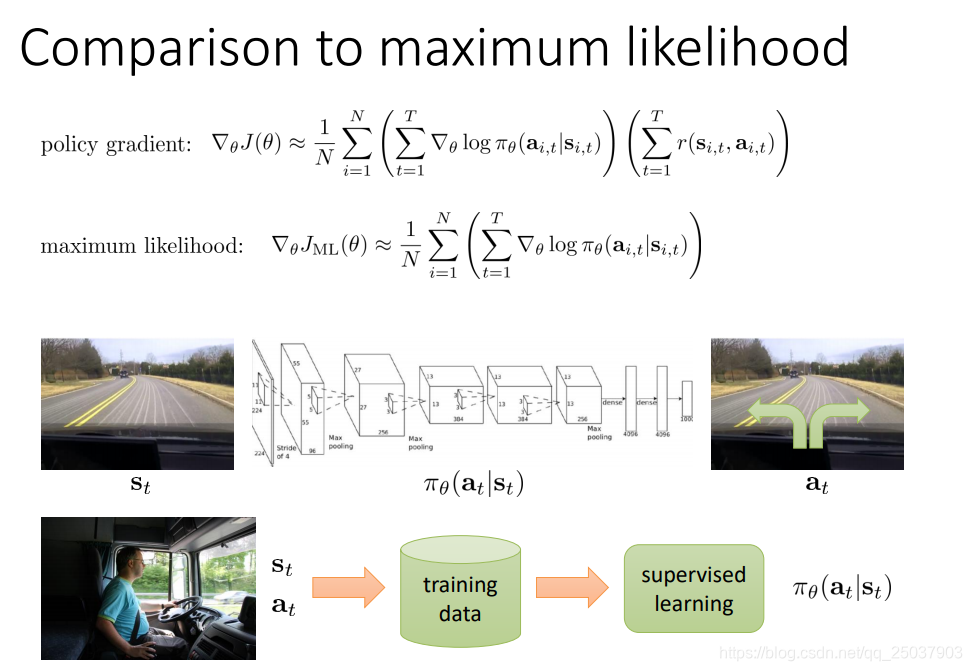
这个算法相当于对于表现的比较好也就是反馈和比较大的例子,选择增大其出现的可能性,而表现得比较差的就减小其可能性。与最大似然的方法相比区别在于对每个样本是区别对待的。这个概念也就是trial and error的想法。

而对于部分可观察的POMDP来说,这个算法也可以直接应用。因为这个算法在推导的过程中,并没有使用MDP里状态动作对的马尔科夫性质。

但是这个算法有个缺点,那就是它的算法计算梯度的时候,方差特别大。可以用一个示意图来简单描述。
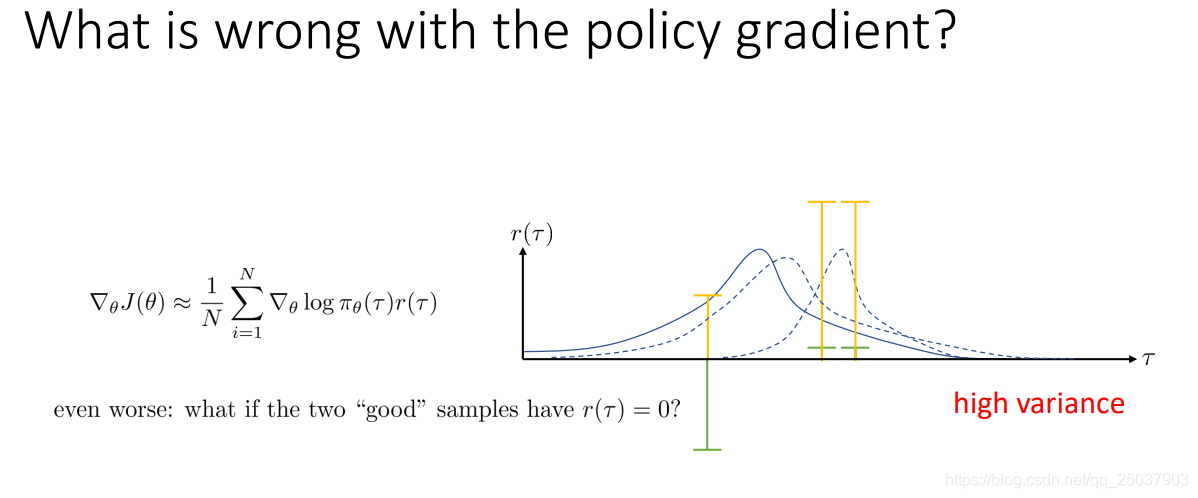
假设序列分布作为横轴,反馈值之和作为纵轴。如果有三个采样点如绿色横线表示,有两个表现为正,一个为负,那么下一次的梯度更新后的分布就会网右边两个靠近,远离左边的例子。但是如果对每个序列的反馈和同时加一个常数,就会变成黄色的表示,那么这三个点更新后的概率分布都会变大。对于极端的例子比如把右边两个例子的反馈减为0,那么更新后的分布就不会关注这两个例子。显然这是不对的,因为实际上的策略不应该被反馈的绝对值影响,而只关注它们的相对值。
在解决这个问题之前先回顾一下刚刚讲过的内容:
3. Basic variance reduction: causality
直接使用策略梯度算法REINFORCE会导致更新梯度的时候方差太大,因此需要考虑减小方差的方法。首先想到的一个方法就是利用因果律。
因果律讲的是,时间t+1时发生的事情不会影响到t和t之前发生的。这个规律应用在目标函数梯度的计算时候也可以用上。那就是对于时间t时候对应的策略,与t之前得到的反馈值是无关的。因此在计算反馈值的时候不需要从
开始计算,而是从
开始计算。这个值刚好是后面要讲的
值。

使用这种简单的方式最终减小了目标函数梯度的大小,因此就减小了对应的方差。
4. Basic variance reduction: baseline
还有一种减小方差的方式是,在计算每个序列反馈和的时候减掉序列和的期望值。当然期望值使用的是采样平均替代。这样做相当于是增大了表现得比平均更好的序列的概率,而抑制了表现得比平均更差的序列发生的概率。

当然这里存在一个问题,就是在计算梯度的时候随意加入一个值是否合理。回忆一下目标函数梯度的计算,加了个常数b相当于是加了如下一项:
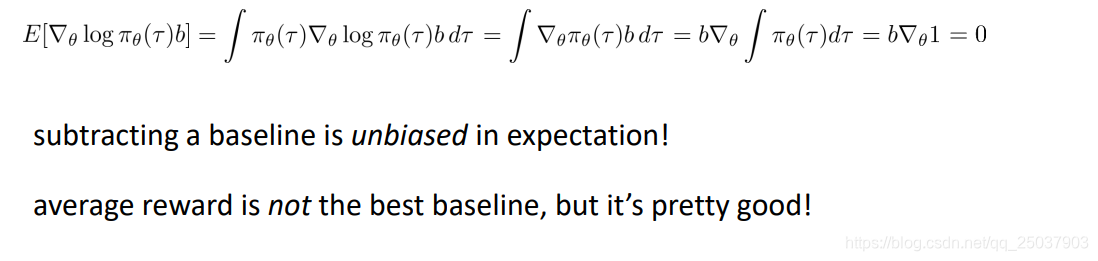
可以看出推导的结果是0,也就是说采样计算加入常数b之后的估计依然是原来的无偏估计,没有问题。
不过加入这个序列期望和的平均值并不是一个最优的方式,当然表现得已经是足够好了。现在来计算一下最优的解是啥:

可以看到最后的结果相当于是序列对应的概率的log求梯度之后的平方加权的反馈和的加权期望。计算起来稍微复杂了一些,带来的增益没那么大,因此我们一般还是会选择直接使用期望和的平均值。
总结一下减少方差的方法:
5. Off-policy learning & importance sampling
策略梯度法是一个on-policy的方法。这意味着每一次策略的更新都需要抛弃之前所有的采样。因此非常耗时费力:

有一种方式能够让更新后的策略计算目标函数时候依然能够使用以往的采样序列,这个方法就叫做importance sampling算法。其实像很简单,如图绿框所示,起始就是加一项概率比的系数,使最终结果变为另一个分布的期望:

用在强化学习里,我们发现序列
在当前策略下发生的概率无法计算。但是还好我们只需要两个序列概率的比值,因此可以消掉无法知道的转移概率与初始概率。
这样我们也能够写出使用了importance sampling方法的目标函数的梯度:

于是我们发现,之前使用的on-policy形式的方法只不过是这里的一个
的特例,相等时只要把其中的概率比写为1即可。
但是我们又得到了一个新的问题,那就是importance sampling加入的概率比是个连乘项,很容易变得太大或太小。因此还需要进一步的处理。

可以把对应的概率比连乘的项写为两个部分。前一个部分的概率表示的是从初始状态开始转移到当前状态的概率之比。这发生在时间t之前,因此不会受到修改参数的影响。后面一部分的概率连乘可以直接忽略,这节课后面的部分会讲这样做会得到policy iteration的结果。
忽略了后面的部分之后结果太大或太小的情况就缓解了很多,但是那里依然有一个指数项。于是继续考虑写为另外的形式。因为需要对状态动作对的联合概率求期望,可以写为先对状态求期望,然后对动作求。但是我们并不知道
,因此直接忽略掉这一项的结果。后面会解释这样做的合理性。

6. Policy gradient in practice
下面讲一点实际的应用。如何在深度学习包里计算这个对应的目标函数的梯度。直接进行每一个序列每个时间点进行梯度计算然后相加是不行的。无法并行加速。

可以来观察一下最大似然情况下是如何进行计算的。

因此我们可以类似地构造一个假的loss函数来让程序进行梯度计算,加入我们把loss设计为如下形式:

那么这样进行梯度计算之后的结果正是我们想要的目标函数的梯度。

还有一些在实际使用策略梯度法时候的建议:1.记住梯度的方差非常大。2.可以考虑用比较大的batch。 3.用tweaking learning比较难。

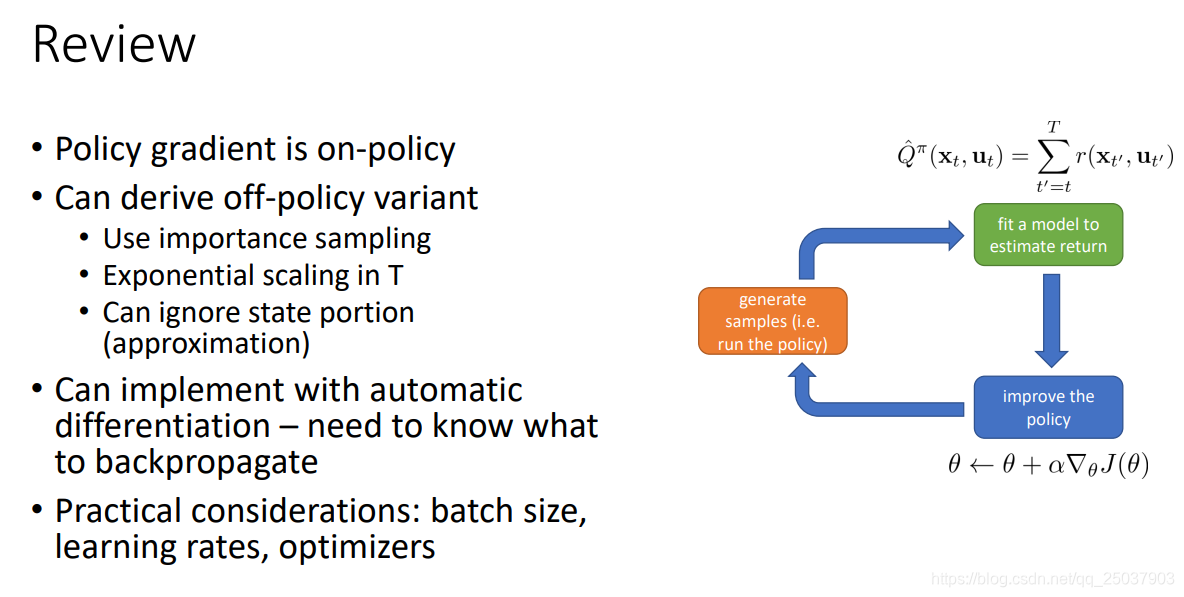
回顾一下:
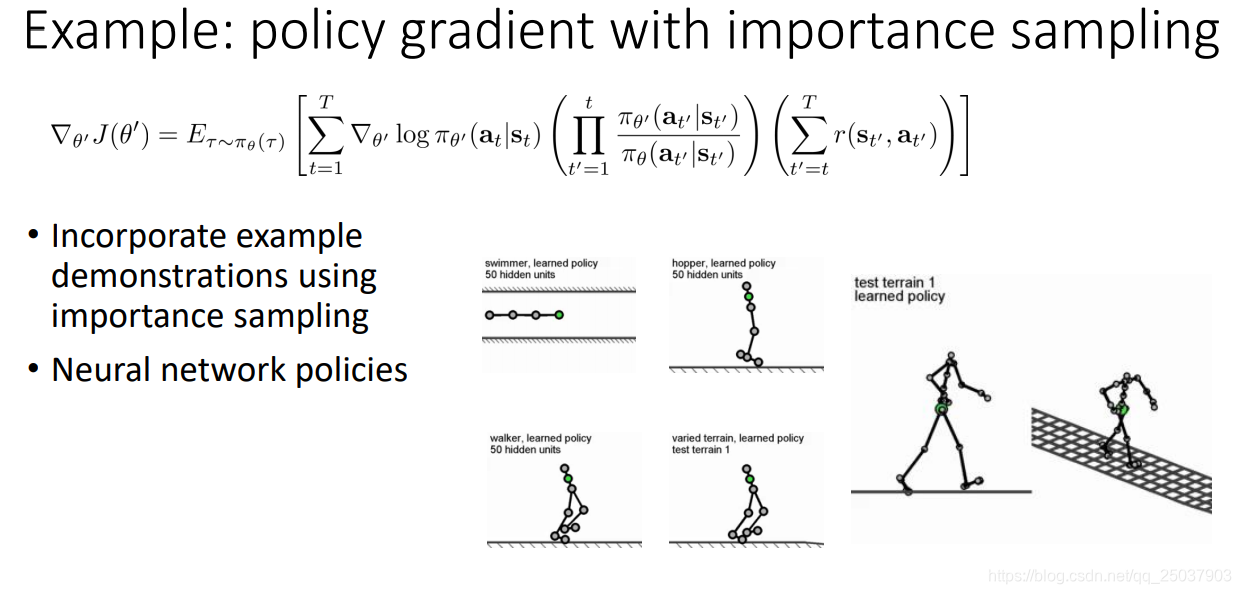
7. Policy gradient examples
后面提到了几个使用策略梯度的例子,似乎TRPO后面会详细讲。

最后是一些推荐的文章:

路漫漫其修远兮,吾将早晚听不懂。