机器学习基石 Lecture8: Noise and Error
Noise and Error
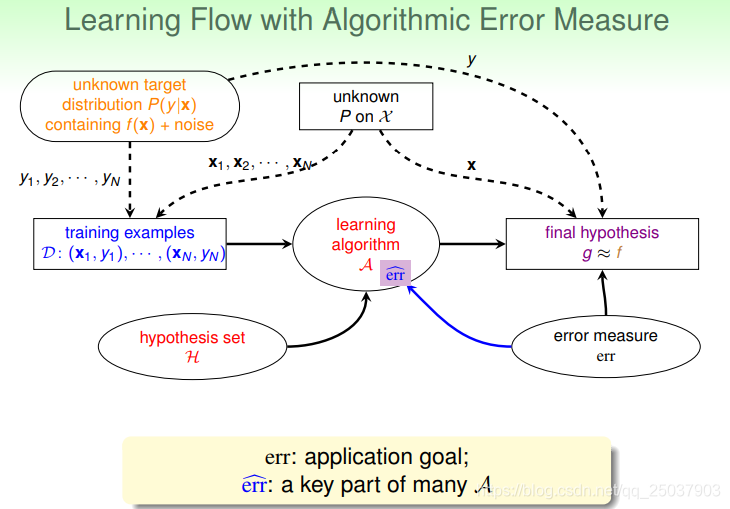
前面讲的机器学习的学习流程如下图所示:
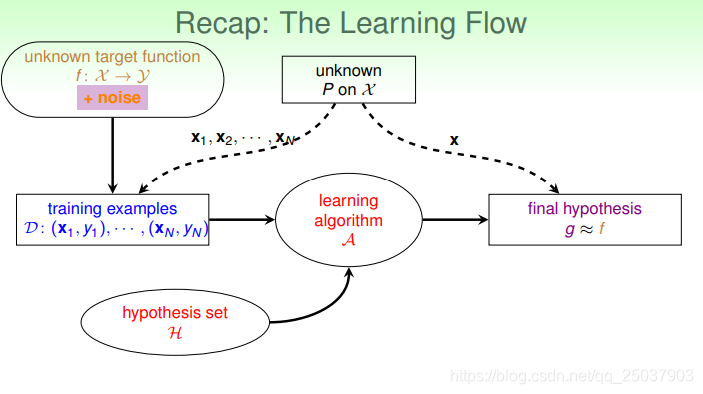
但是这个流程里假设的都是有一个真实的函数
来生成样本,但是现实中很有可能样本里带有一些噪音,也就是无法单纯用一个函数
来刻画
与
的关系。比如在信用卡问题里有以下几种噪音:
- y的噪音:对表现良好的用户标记为-1(不发信用卡)
- y的噪音:同样的用户不同的标签
- x的噪音:不准确的用户信息
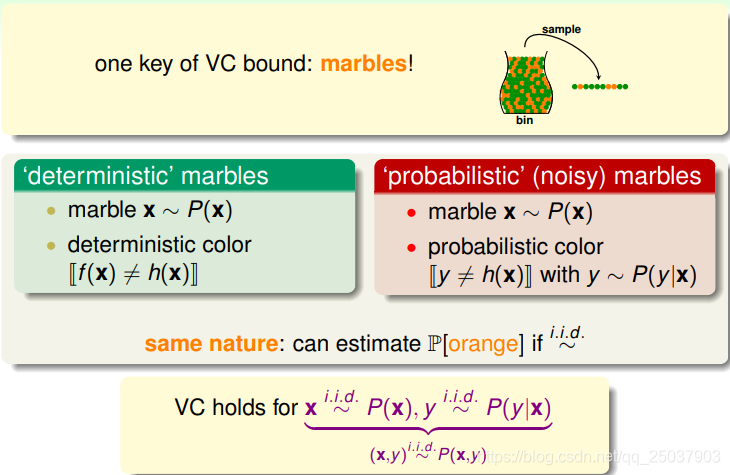
在有噪音的情况下,VC bound的不等式是否依然成立呢?我们可以从头开始推导,但是要包含有噪音的情况。建模成每个样本
服从一个概率分布
,而对于一个给定的
,对应的
也服从一个条件分布
。这样就包含了噪音的存在。最终的结果是VC bound的结果依然类似的成立:
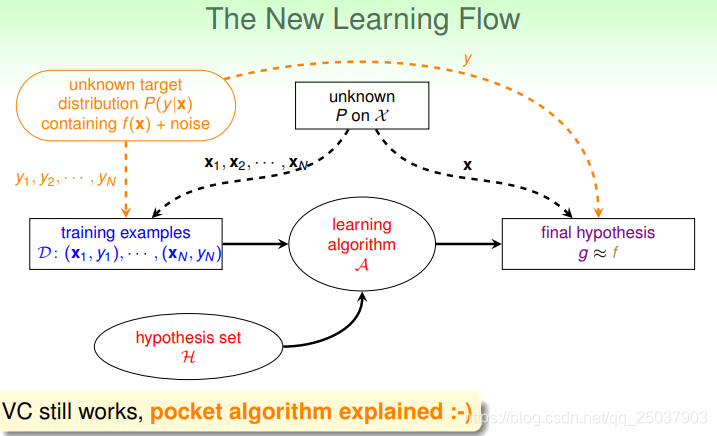
这时候我们机器学习的目标就从学习一个目标函数
变成了学习一个概率分布
。而对一个给定
有确定性结果
的目标函数
是这样一个概率分布的特殊情况。因此我们得到了一个新的机器学习的流程:
Error Measure
当我们得到一个最终的学习结果 的时候需要将其与真实函数 作对比,这样才能够知道最终学习到的效果如何。比如之前在PLA里考虑的在采样集合之外函数 的错误率 就是一种比较方式。更一般的说,这种方式叫做error measure E(g,f)。一般评估错误有几个自然的想法:
- 在数据集外未知的x上测试错误率(out-of-sample)

- 在每个单独的x之上评估再进行平均(pointwise)
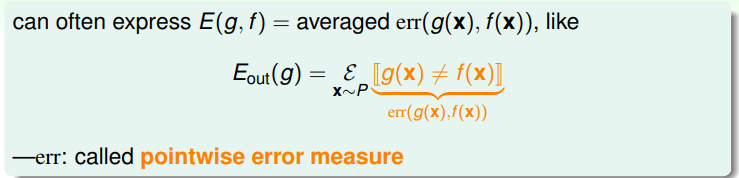
- 使用简单的是否预测正确来判断(classification,0/1 error)

0/1 error一般使用在分类中,还有一种重要的error叫做平方误差,一般用在回归中:

比如对于一个简单的问题而言,使用不同的error就可以针对不同的“最优”的目标函数 :

这样error measure在机器学习的过程中就能对算法起到一个引导的作用,引导算法得到不同的最终结果:

Algorithmic Error Measure
上面的0/1 error中对于不同类型的判断错误同等对待,但是实际应用中不同的错误类型可能导致的严重后果完全不同。比如如下一个指纹识别的例子。当用在超市会员打折时,false reject可能会导致用户非常生气,而false accept导致的结果也没有很坏。因此可能对不同的错误类型赋予不同的权重:

但如果是CIA的指纹识别机,不同的错误导致的后果又是与超市完全相反:

因此对于不同的应用场景而言我们会为算法定义一个新的err来表达对不同错误的容忍程度,用
表示(因为和问题里实际的err有可能还是不一样)。当定义
时我们需要考虑两方面,一个是合理性,一个是是否易于实现:

于是对于算法而言就有了新的
来指导其选择假设函数,新的机器学习流程如下:
Weighted Classification
对于不同的错误分类需要有一个权重来表示它的重要程度,因此新的计算错误率的时候需要将系数也加入其中:

于是我们新定义了一个带权重的集合内错误率:
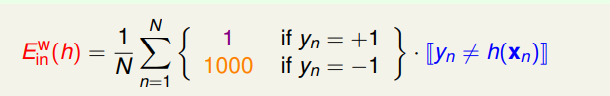
这对于PLA算法而言没有影响,因为对于线性可分的数据集,最终得到的结果集合内错误率应该是0。但是对于非线性可分的数据集的pocket PLA算法而言就需要进行对应的修改。修改出现在使用刚更新的
判断是否需要替代当前最好的系数
的时候。初始的判断方式是使用集合内的错误率
,现在替换为
即可。
但是对于pocket PLA算法而言,我们能够保证使用 能得到较好的结果,但是使用 呢?
这个时候只需要将对应错误类型的样例进行正比于系数的虚拟赋值,这样就将这个使用了
的问题转化为了一个使用了
错误的问题:

转化之后的问题是当前已经解决的问题,因此对于这个形式的err,pocket PLA算法的结果也能得到保证。转化后的问题为:

最后注意一个习题,习题表明了对于正负例比例严重失调的时候,使用带权重的错误能够用来避免算法只返回一个不变的结果:
