版权声明:本文为博主原创文章,转载请备注https://blog.csdn.net/travelerwz。 https://blog.csdn.net/Travelerwz/article/details/83409369
requests+BeautifulSoup爬取网页图片
最近一直抽时间在看requests+BeautifulSoup爬取网页内容这一块的内容,所以,打算把自己看的总结一下,分享也是一种学医,给自己做做笔记。
1.首先,我们看一下requests库
requests库主要用于访问网页,这个网上资源比较多,所以我就不多说了,我这直间给出一个连接,大家可以看看。
快速上手requests
2.BeautifulSoup库
这个是一个强大的解析工具,它借助网页的结构和属性等特性来解析网页,而且可以方便的提取网页的元素,非常好用,入门教程我觉得崔庆才老师的文章很值的学习,给出链接崔庆才BeautifulSoup;
我主要说一下提取元素的技巧,因为我刚开始看的时候没有注意到这一点;
BeautifulSoup的find_all(‘tag’)方法,是按照tag取出来的tag标签及其内容。那如何取到标签的内容,或者子标签的内容。实际上这还是一个DOM的层级结构问题。
之所有要选取到提取h4标签,而不是直接find_all(‘a’),是因为网页上的a标签很多,一些不是我们所需要提取的内容。
<h1 class="title">
<a target="111" href="4444">123</a>
</h4>
我随便写一个例子,我们要提取a标签里面的内容的话,应该这样做:
links = soup.find_all('h1')
for link in links:
print link.a.get_text()
print link.a['href']
这样我们成功的提取到了a标签中href的内容,href 是一种属性。
这个就是我们使用这两种库的时候一个小小的技巧,当然也很重要。
3.我们来爬取一个网页的图片的链接
当然,我们获取了网片的链接,就可以欢快的下载图片了
我的代码的注释会比较多一些。
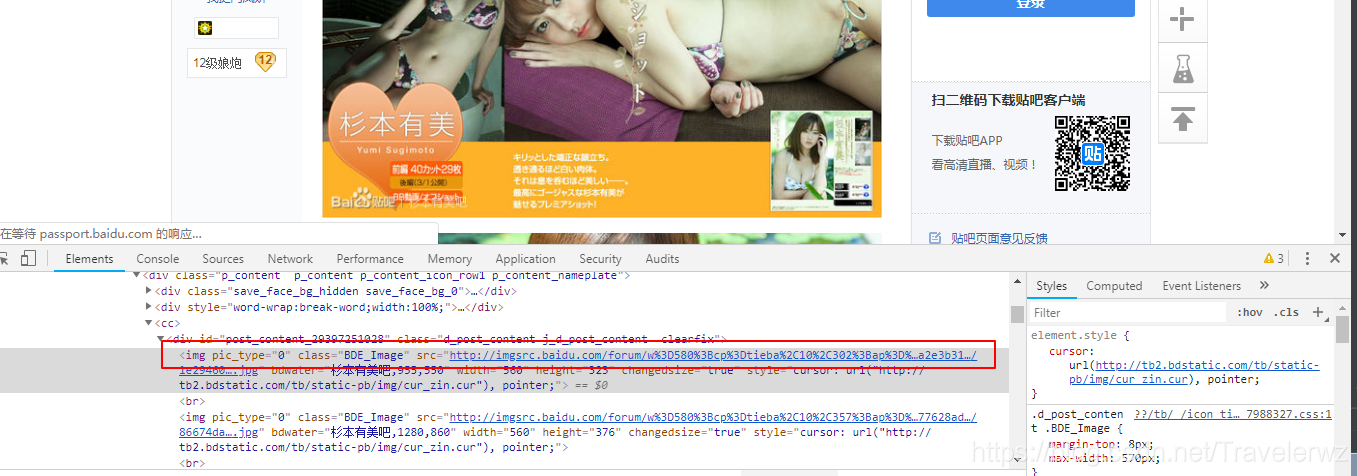
代码:
import requests
from bs4 import BeautifulSoup
import os
#获取html
f = requests.get('http://tieba.baidu.com/p/2166231880').text
s = BeautifulSoup(f,'lxml')
s_imgs = s.find_all('img',attrs={'class':'BDE_Image'})
for s_img in s_imgs:
img_url = s_img['src']
print(img_url)
这个实现了爬取图片的url;