上一篇文章中写了关于爬取关注画师的作品,不过最开始想用python的爬虫就是为了Miku,想要爬点Miku的图片下来做二次元人物的人脸识别,一开始也是由于刚入门不太懂所以没有轻易尝试直接爬取一个tag下的作品,不过经过之前的折腾后,对python的基础爬虫也算有点了解了,这次尝试爬取了指定标签下的所有作品。
跟上篇文章相比,在初始url和获取页面url上做了点改动,使用了beautifulSoup包对html先做一个初步的分析,再使用正则表达式提取信息,因为新手所以beautifulSoup和正则得都很丑,大家就不要鄙视了,结果是好的就行嘛0.0
改动和需要注意的地方:
1.P站里的某个tag下最多显示1000页图片,也就是20000张图片,比如“初音ミク”标签下共有33W多张图片,也就是16000页多,但只能按顺序显示前1000页而已,如果按时间排序大概从2016.5.1-今天,默认排序为投稿日期,要使用收藏数(就是每张图片下面那个星星数)来排序需要开通会员功能,这里我把每张图片的收藏数也获取到,然后分文件夹存放,就相当于实现了那个会员功能了,O(∩_∩)O哈哈哈~然后爬了一些以后确实可以发现差距啊
2.20000图片如果全部爬取下来是不现实的,我给ubuntu分的空间总共才40G,已经用掉一半了(虽然可以用外接设备的空间),所以我一开始尝试爬取图片成功了几页后,就把获取1-50收藏数图片的代码注释掉了(就一行),下面可以看到,只获取高收藏数的
3.为了以后方便,因为爬下来的高清原图将来要用的话还要再处理为小一点分辨率的图片,所以在程序开始运行时可以自己选择要保存的图片大小等级,虽然下面的代码中没有实现获取小分辨率的,不过那相比起获取最大分辨率的原图简单地太多了,暂时用不到就没加上去
4.这一次大多参数选择在运行时输进去,可以改的有tag名字,起始页数,获取图片的分辨率,这个没什么难的
5.由于图片数目太多,难免出现重名的,比如说miku,初音ミク的很多,所以在最后存储的时候加了个判断重名并重命名的代码
6.由于担心网络不稳定中间连接失败,或者有人刚在该tag下投稿就会将前一页的作品顶到下一页去,所以还要增加判断该图片有没有获取过,这用一个存储url的list就可以解决了
7.假如中间程序崩溃了,重新开始的话,从哪开始还不太清楚,虽然可以把相关信息打印出来或保存在文件中,再次运行输入起始page号就可以,不过到目前为止还没想到更好的办法,想过用shell脚本调用这个.py文件判断返回值再用脚本重新执行这个程序,不过网上没找到相关资料,最后还是放弃了,有大神来的话求教啊~
8.之前爬千夜大大的图没有碰到png的图片,所以没注意到,原来P站有的是png后缀的图,如果你强行保存成.jpg那是看不了的,所以保存图片时还加了提取后缀的正则表达式,然后将图片保存成对应的格式
下面直接上完整的程序:
# -*- coding:utf-8 -*-
#created by zfq
#first edited: 2016.12.09
import requests
import re
import os
from bs4 import BeautifulSoup
s = requests.Session()
class Pixiv:
def __init__(self):
self.baseUrl = "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index"
self.LoginUrl = "https://accounts.pixiv.net/api/login?lang=zh"
self.loginHeader = {
'Host': "accounts.pixiv.net",
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36",
'Referer': "https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index",
'Content-Type': "application/x-www-form-urlencoded; charset=UTF-8",
'Connection': "keep-alive"
}
self.return_to = "http://www.pixiv.net/"
self.pixiv_id = 'xxxxxxxx',
self.password = 'xxxxxxxx'
self.postKey = []
self.savedUrlList = [] #存放存储过的图片的url
#获取此次session的post_key
def getPostKeyAndCookie(self):
loginHtml = s.get(self.baseUrl)
pattern = re.compile('<input type="hidden".*?value="(.*?)">', re.S)
result = re.search(pattern, loginHtml.text)
self.postKey = result.group(1)
loginData = {"pixiv_id": self.pixiv_id, "password": self.password, 'post_key': self.postKey, 'return_to': self.return_to}
s.post(self.LoginUrl, data = loginData, headers = self.loginHeader)
#获取页面
def getPageWithUrl(self, url):
return s.get(url).text
#输入文件夹名,创建文件夹
def mkdir(self, path, folderName):
folderName = folderName.strip()
isExists = os.path.exists(os.path.join(path, folderName))
if not isExists:
os.makedirs(os.path.join(path, folderName))
print '建了一个名字叫做' + folderName + '的文件夹!'
os.chdir(self.tag) #切换到目录
self.rootPath = os.getcwd()
print self.rootPath
os.makedirs(os.path.join(self.rootPath, "1-50"))
os.makedirs(os.path.join(self.rootPath, "51-300"))
os.makedirs(os.path.join(self.rootPath, "301-1000"))
os.makedirs(os.path.join(self.rootPath, "1000以上"))
print '在' + folderName + '文件夹下建立了 1-50 51-300 301-1000 1000以上 4个文件夹'
return True
else:
print '名字叫做' + folderName + '的文件夹已经存在了!'
os.chdir(self.tag) #切换到目录
self.rootPath = os.getcwd()
#下载指定url的图片
def getBigImg(self, sourceUrl, wholePageUrl, name):
header = {
'Referer': wholePageUrl,
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'
}
if sourceUrl in self.savedUrlList:
print '该图片已经存在,不用再次保存,跳过!'
else:
self.savedUrlList.append(sourceUrl)
imgExist = os.path.exists(os.getcwd() + '/' + name.encode('utf-8') + '.jpg') #如果存在重名的,则给name加1重新命名
if (imgExist):
name = name + 're'
print u'存在重名图片,重新命名为: ' + name
suffixPattern = re.compile('.((\w){3})\Z')
suffix = re.search(suffixPattern, sourceUrl) #获取文件后缀,png或jpg
img = s.get(sourceUrl, headers = header)
f = open(name + '.' + suffix.group(1), 'wb') #写入多媒体文件要b这个参数
f.write(img.content) #多媒体文件要是用conctent!
f.close()
def getImg(self, url):
#查找本页面内最大分辨率的图片的url的正则表达式
singleImgePattern = re.compile('<div class="_illust_modal.*?<img alt="(.*?)".*?data-src="(.*?)".*?</div>', re.S)
wholePageUrl = 'http://www.pixiv.net' + str(url)
pageHtml = self.getPageWithUrl(wholePageUrl)
singleImgResult = re.search(singleImgePattern, pageHtml) #如果这个页面只有一张图片,那就返回那张图片的url和名字,如果是多张图片 那就找不到返回none
#单图的获取方法
if(singleImgResult):
imgName = singleImgResult.group(1)
imgSourceUrl = singleImgResult.group(2)
print u'这个地址含有1张图片,地址:' + wholePageUrl
print u'正在获取第1张图片.....'
print u'名字: ' + singleImgResult.group(1)
print u'源地址:' + singleImgResult.group(2)
self.getBigImg(imgSourceUrl, wholePageUrl, imgName)
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
#多图的获取方法
else:
wholePageUrl = str(wholePageUrl).replace("medium", "manga")
pageHtml = self.getPageWithUrl(wholePageUrl)
totalNumPattern = re.compile('<span class="total">(\d*)</span></div>', re.S) #找到这一页共有几张图
totalNum = re.search(totalNumPattern, pageHtml)
if (totalNum): #如果是动图get不到这个num,返回的是none
print u'这个地址含有' + totalNum.group(1) + u'张图片,地址:' + str(wholePageUrl)
urlPattern = re.compile('<div class="item-container.*?<img src=".*?".*?data-src="(.*?)".*?</div>', re.S)
namePattern = re.compile('<section class="thumbnail-container.*?<a href="/member_illust.*?>(.*?)</a>', re.S)
urlResult = re.findall(urlPattern, pageHtml)
nameResult = re.search(namePattern, pageHtml)
for index,item in enumerate(urlResult):
print u'正在获取第' + str(index + 1) + u'张图片......'
print u'名字: ' + nameResult.group(1) + str(index + 1)
print u'源地址:' + item
self.getBigImg(item, wholePageUrl, nameResult.group(1)+str(index + 1))
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
else:
print '这个网址是一个gif,跳过!'
print 'Done!'
print '--------------------------------------------------------------------------------------------------------'
def start(self):
self.tag = raw_input('Please input the tag: ')
self.page = int(raw_input('Please input the page you want to start from: '))
self.resolution = int(raw_input('Please input the resolution, from 1 to 3, 1 is highest resolution: '))
path = "/home/zfq/EclipseWork/Pixiv/GetByTag"
self.mkdir(path, self.tag) #调用mkdir函数创建文件夹
self.getPostKeyAndCookie() #获得此次会话的post_key和cookie
for pageNum in range(self.page, 100):
url = "http://www.pixiv.net/search.php?word=%s&s_mode=s_tag_full&order=date_d&type=illust&p=%d"%(self.tag, pageNum)
pageHtml = self.getPageWithUrl(url) #获取该页html
pageSoup = BeautifulSoup(pageHtml, 'lxml')
imgItemsResult = pageSoup.find_all("ul", class_="_image-items autopagerize_page_element") #找到20张图片所在的标签,返回的list长度为1
imgItemsSoup = BeautifulSoup(str(imgItemsResult), 'lxml')
imgItemResult = imgItemsSoup.find_all("li", class_="image-item") #找到每张图片所在的标签,返回list长度应为20
imgUrlPattern = re.compile('<a href="(.*?)"><h1.*?</h1>', re.S) #在该图片所在image-item标签里找到url和收藏数
imgStarsPattern = re.compile('<ul class="count-list.*?data-tooltip="(\d*).*?".*?</ul>', re.S)
for imgItem in imgItemResult:
if (self.resolution == 1): #获取原图)
imgUrl = re.search(imgUrlPattern, str(imgItem))
imgStars = re.search(imgStarsPattern, str(imgItem))
if ((not imgStars) or (int(imgStars.group(1)) <= 50)):
os.chdir(self.rootPath + '/1-50') #切换到对应目录
elif (int(imgStars.group(1)) <= 300):
os.chdir(self.rootPath + '/51-300')
self.getImg(imgUrl.group(1))
elif(int(imgStars.group(1)) <= 1000):
os.chdir(self.rootPath + '/301-1000')
self.getImg(imgUrl.group(1))
else:
os.chdir(self.rootPath + '/1000以上')
self.getImg(imgUrl.group(1))
p = Pixiv()
p.start()
大多数已经做了注释了,运行:
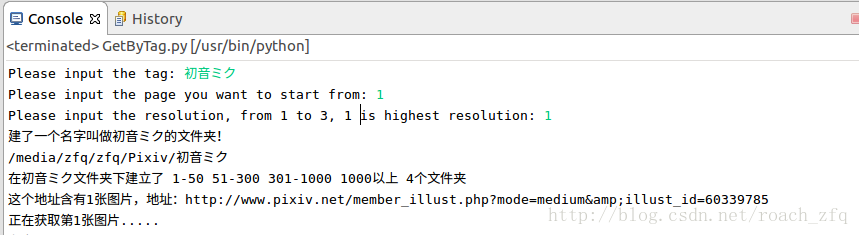
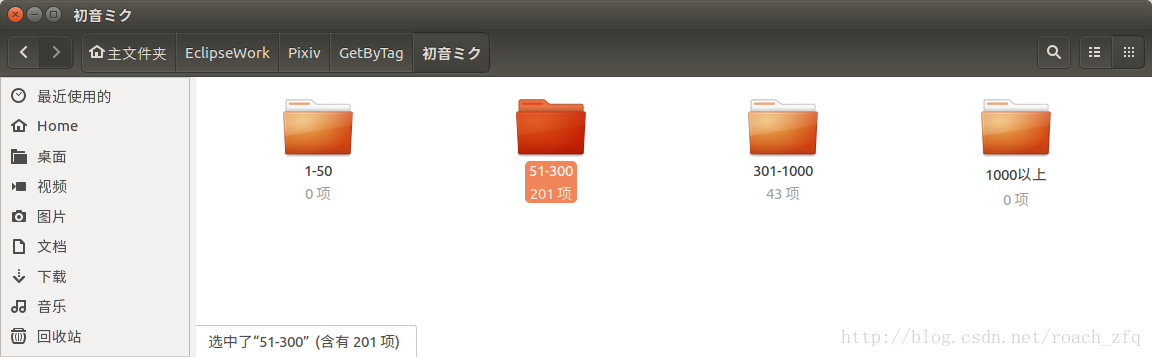
文件夹:

然后我最开始没有注释1-50收藏数的代码,也会get到1-50收藏数的,就是按页码按顺序依次get到1-50文件夹里:
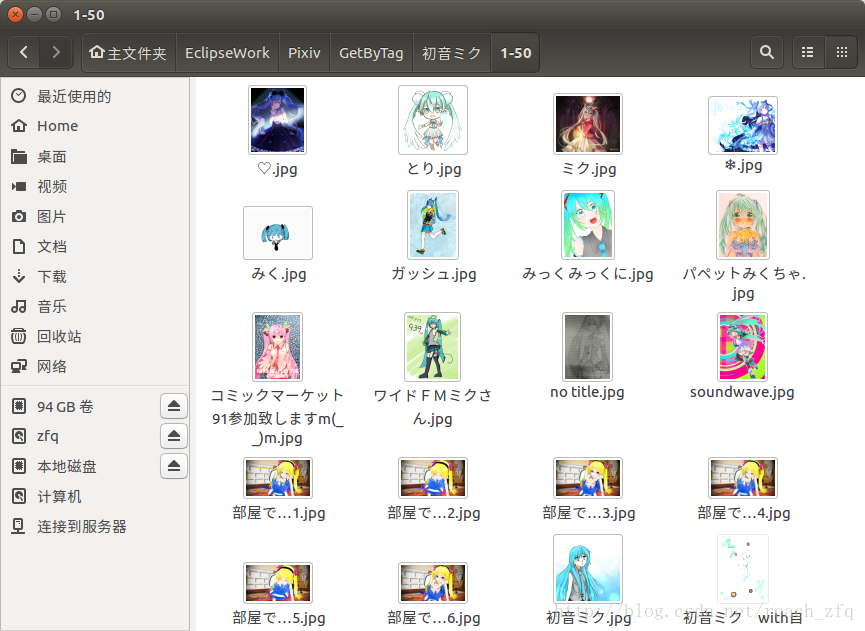
这些图。。嘛。。。不爬也罢吧。。确实也因为空间不够,所以就没爬1-50的了。不过也有个问题是刚上传的图如果是好图,但由于太新还没人看到那就get不到了。。
感觉今天的网速和网络都还可以,第一次是在大概10分钟后爬了150张图后连接崩溃,然后从又从那一页重新开始,不得不说这样的话效率确实太低了。
晒一下到目前的成果吧:
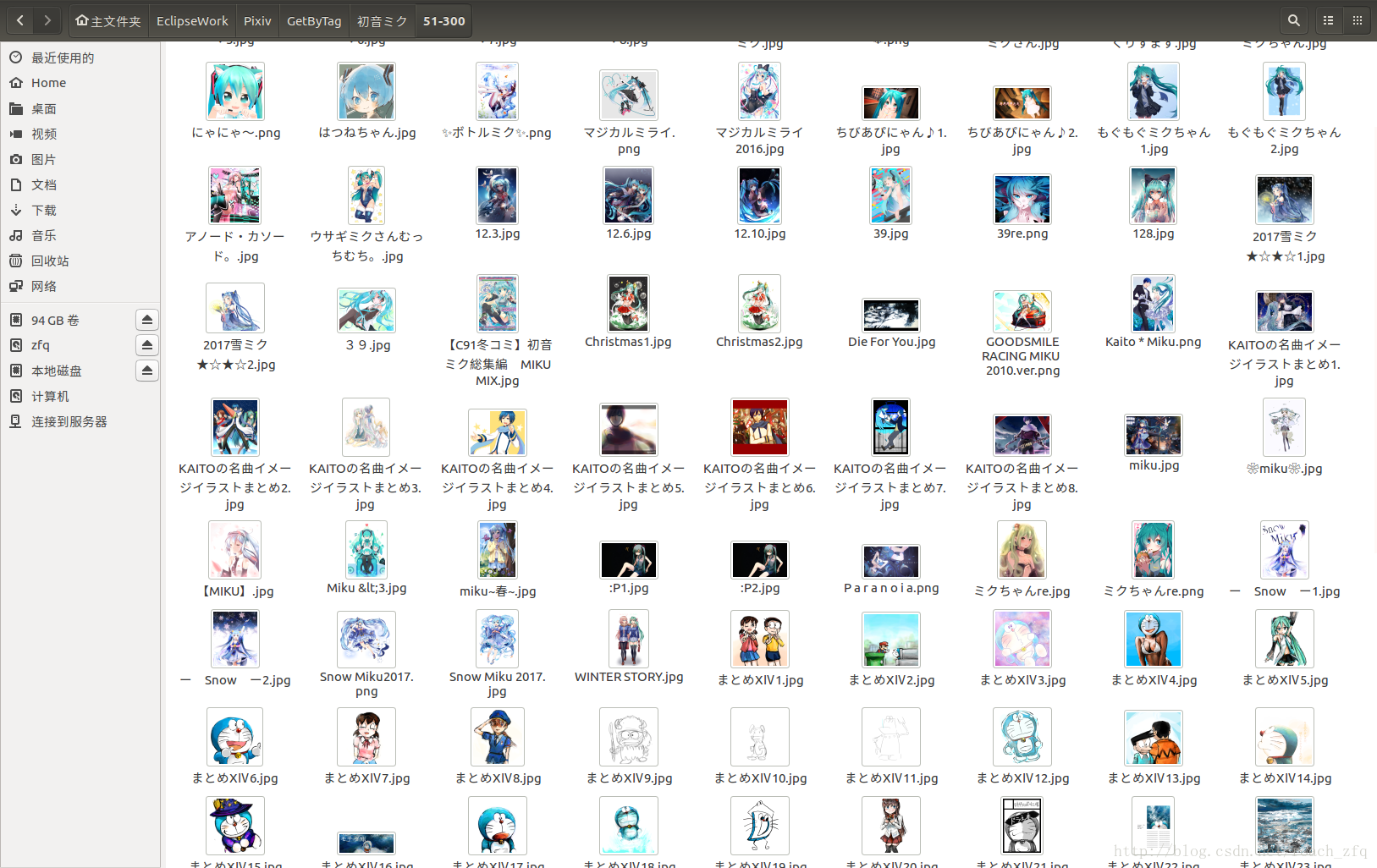
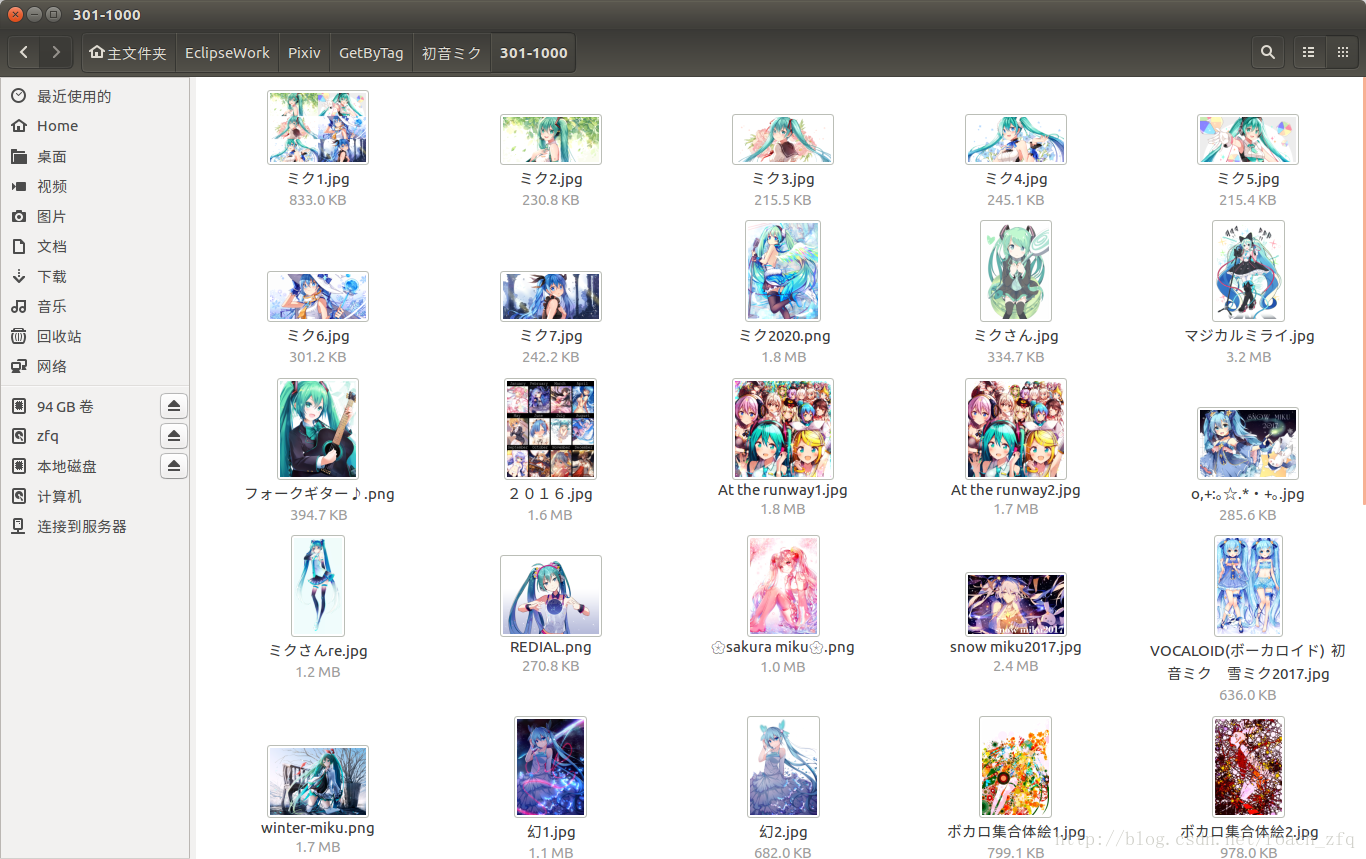
到目前竟然还没有一张1000星以上的图。。大概爬到2016.11.25,60页左右,也可以看出这几类的图片数量比例了。
这个也还算是练习,经过这些练习后,感觉对python和linux系统越来越熟悉了,常见的python代码和shell脚本应该也看得懂了,不过说实话学这个对将来真的有用吗,我也说不出来,只是有这个想法就去做了而已,感觉挺有趣的,哈哈,感觉做什么事情动力都很重要呢(╯□╰)o~谢谢Miku>.<~
目前就这样吧,又爬了大概100张了,还是没有1000星的,爬太多也装不下,以后有具体任务和目标再来爬好了,比如爬排行榜,爬V家众人头像来做动漫人脸识别?爬取特定画风来识别?爬取收藏数高和低的来识别好图和差图?啊~~人工智能真的太厉害了,可以做的事好多呢,说不定将来哪一天真的可以在现实中创造出一个二次元妹子?哈哈@_@,我很期待...
这次代码的github,https://github.com/zhaofenqiang/Pixiv,以后关于的P站的都存在这了
来张爬到的活动小丑,完~
