1 范数(norm)
它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。一般我们用范数来衡量两个向量之间的距离,也就是相似度。
1.1常见的范数
0-范数
有多少个非零的数1-范数(曼哈顿距离)
2-范数 (欧几里得距离)
∞-范数
范式图例

2 向量和矩阵(Vector and Matrix)
既有大小,又有方向的量叫向量。一般来说在工程应用里,我们常用向量或者矩阵来表示一组数据,这样可以来表示数据的高维特性。而矩阵就是很多向量的集合。
2.1 向量的一些运算
- 加法
编程实现(python)
import numpy as np
a = np.array([-1, 2])
b = np.array([3, 1])
print a + b - 向量和向量相乘
编程实现(python):
import numpy as np
a = np.array([3, 5, 2])
b = np.array([1, 4, 7])
print a.dot(b)
print np.dot(a, b) - 向量外积
import numpy as np
a = np.array([3, 5, 2])
b = np.array([1, 4, 7])
print np.cross(a, b) - 矩阵向量积
编程实现(python):
import numpy as np
a = np.matrix('4 3 1;1 2 5')
x = np.array([[5], [2], [7]])
print a*x-向量的转置
转置之后
编程实现(python)
import numpy as np
a = np.array([[2, 4]])
a.T2.2 矩阵的特征向量和特征值(Eigenvector and Eigenvalue)
对一个方阵A,如果可以对A进行矩阵分解得到:
特征值分解
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。
特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么,可以将每一个特征向量理解为一个线性的子空间,我们可以利用这些线性的子空间干很多的事情。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
编程实现(python)
import numpy as np ##引入numpy模块
x=numpy.diag((1,2,3)) ##写入对角阵x
x ##输出对角阵x
array([[1,0,0],
[0,2,0],
[0,0,3]])
a,b=numpy.linalg.elg(x) ##特征值赋值给a,对应特征向量赋值给b
a ##特征值 1 2 3
array([1.,2.,3.])
b ##特征向量
array([1.,0.,0.],
[0.,1.,0.],
[0.,0.,1.]) 2.3 矩阵的迹(Trace Of Matrix)
import numpy as np ##引入numpy模块
x=numpy.diag((1,2,3)) ##写入对角阵x
x ##输出对角阵x
x.trace()2.4 奇异值分解(Singular Value Decomposition)
选自>https://blog.csdn.net/shenziheng1/article/details/52916278
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有 个学生,每个学生有 科成绩,这样形成的一个 的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
假设A是一个 的矩阵,那么得到的 是一个 的方阵(里面的向量是正交的, 里面的向量称为左奇异向量), 是一个 的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值), (V的转置)是一个 的矩阵,里面的向量也是正交的, 里面的向量称为右奇异向量。那么奇异值和特征值是怎么对应起来的呢?首先,我们将一个矩阵A的转置乘A,将会得到一个方阵,我们用这个方阵求特征值可以得到:
这里得到的v,就是我们上面的右奇异向量。此外我们还可以得到:
这里的σ就是上面说的奇异值,u就是上面说的左奇异向量。奇异值σ跟特征值类似,在矩阵Σ中也是从大到小排列,而且σ的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵,这里定义一下部分奇异值分解:
右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的面积之和(在存储观点来说,矩阵面积越小,存储量就越小)要远远小于原始的矩阵A,我们如果想要压缩空间来表示原矩阵A,我们存下这里的三个矩阵:U、Σ、V就好了。
编程实现(python)
import numpy as np
M = [[1,2,3],[4,5,6],[7,8,9]]
U,D,Vt = np.linalg.svd(M)2.5 Jacobian Matrices and Hessian Matrices
2.5.1 Jacobian Matrices
在向量分析中, 雅可比矩阵是一阶偏导数以一定方式排列成的矩阵。
雅可比矩阵的重要性在于它体现了一个可微方程与给出点的最优线性逼近. 因此, 雅可比矩阵类似于多元函数的导数。
2.5.2 Hessian Matrices
海森矩阵是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵。
3 张量(Tensor)
张量(Tensor)这个词来最早自于物理。比如我们常见的标量(Scalar)如质量、温度等,只有尺度(Magnitude)而没有方向(Direction);向量(Vector)如重力、速度等,不仅有尺度大小还有一个方向。而张量则是在标量和向量的基础之上做的进一步推广。比如柯西应力张量(Cauchy’s stress tensor),是一个描述物体表面压力的物理量。如下图所示:
节选自>>https://www.wukong.com/question/6531498435785261325/

张量的提出是为了研究一些不依赖于坐标系的内在的几何性质和物理性质。相对论出现以后,张量这个概念被发扬光大了(相对论需要研究不同参考系下的同一物理系统的规律)。在现代数学上,张量定义为多重线性映射(multilinear map)。
TensorFlow中的Tensor或者说张量就是多维数组
- 1是一个0维张量/0维数组,又叫标量(scalar),形状为[]
- [1, 2, 3]是一个1维张量/1维数组,又叫向量(vector),形状为[3].
- [[1, 2, 3], [4, 5, 6]]是一个2维张量/2维数组,又叫矩阵(matrix),形状为[2, 3]
- [[[1, 2, 3]], [[4, 5, 6]]]是一个3维张量/3维数组,有时候,张量特指3维以上的张量(低于3维的,如前所述,分别叫标量、向量、矩阵),形状为[2, 1, 3]

4 凹凸函数(Concave and Convex Function)
函数是凸的满足条件:
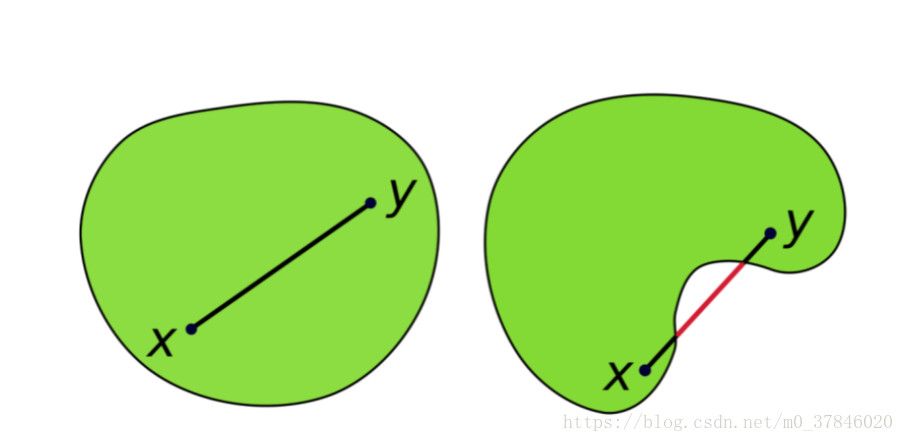
左边为凸函数,右边为凹函数。