代码地址code
文章地址Object Detection from Video Tubelets with Convolutional Neural Networks
写这篇之前刚知道被布朗大学录取了,真是太开心啦!看论文更有动力了!
这篇是港大的Kai Kang 16年发表在CVPR上的,讲了视频中的目标检测。这篇是我毕设要看的论文,并且我也没有看到有好的翻译,大多数是Tubelets with Convolutional Neural Networks for Object Detection from Videos这篇文章的翻译,所以这篇应该属于翻译类别。这个tubelet我不知道怎么翻译,查看了csdn上的一些博客都没有介绍,这里直接用英文了。
1. Introduction
深度学习被广泛运用在图像识别、目标检测、语义分割、人体姿态估计等方面,在过去的几年中,得益于深度卷积神经网络deep CNN的发展,目标检测在ImageNet和PASCAL VOC等数据集上都取得了很好的成绩。最新的方法可以训练CNN以将目标区域object proposals进行分类,但是这些方法都是关注静态图像的检测,之后出现的ImageNet比赛提出了新的问题:如何高效鲁棒的解决视频VID中的目标检测问题?对于视频中的每一帧,都要求对其中的目标进行标注并得到确信值。尽管已经有了许多方法进行视频检测,但是很多都只针对于一种分类,比如行人或者车辆,而ImageNet却要求检测出值得进一步研究的所有目标群体。就像静态图像的目标检测可以帮助其他识别任务一样,在视频中的目标检测也可以提高视频分类、视频抓取和其他相关工作的性能,通过对视频中目标的定位和分析,视频的语义semantic会更加清晰,得到更加鲁棒的性能。
现有的方法没有办法解决这个问题,因为视频中的目标会有很大的变动。比如在Figure 1 (a)中,如果一只猫先面对镜头然后转身背对镜头,它背面的图像可能不会被识别成猫,因为背面包含的信息很少,不适合用作训练样本。正确的结果应该是根据视频上下帧的信息推断的,因为视频中的目标是有连续性的。由于视频中目标的位置是变化的,相关的图像应该有一条轨迹,从这个轨迹中我们可以得到时间上的信息。同时,检测结果的时间连续性应该被调整,因为目标bounding-box tubelet的检测值detection score不应该有剧烈的波动(Figure 1 (a))。
这些问题要求我们将目标跟踪object tracking融入目标检测中,deep CNN在这项任务上表现很好,大量的检测方法表明时间信息可以应用在校准检测结果上。但是,直接在VID上应用目标跟踪并不能很好的解决这个问题(Figure 1 (b)),在实验中,我们注意到在目标跟踪上直接应用静态图像目标检测只有37.4%的mAP,相较于45.3%mAP的object proposals来说可以说并不好。这种问题产生的原因是由于检测器对位置改变的敏感度和bounding box在轨迹和proposals之间的匹配出现错误。为了解决这个问题,我们应用一个tubelet box perturbation和最大池化过程,将mAP提高到45.2%,仅用1/38的边框就可以得到和object proposals同样的准确率。

在此,我们建造了一个基于deep CNN的检测和跟踪的多层级的框架,主要有两个模块:1、一个结合了目标检测和目标跟踪的tubelet proposal模块。2、一个tubelet classification and re-scoring模块,这个模块用空间最大池化spatial max pooling来得到鲁棒的边框得分,用时间卷积temporal convolution来得到时间上的连续性。检测和跟踪是紧密结合的:一方面,目标检测可以使跟踪变得高信,而且可以减少空间最大池化的的跟踪失败率;另一方面,跟踪也可以为检测指明新的候选区域。
这篇论文的贡献有三个方面:1、建立了一个上述的多层级架构;2、分析了静态目标检测和目标跟踪的关系,以及它们对于视频目标检测的影响;3、运用一个特殊的temporal CNN将时间信息结合到目标检测之中。
2. Related work
现在目标检测最好的方法基本都是基于deep CNN的。Girshirk等人用一种多层次的方法R-CNN来选出候选区域进行目标识别,这种方法将目标检测问题分解为bounding-box区域、CNN预训练、CNN微调、SVM训练、bounding-box回归等小问题;Szegedy等人建立了一个22层结构的GoogleNet,将R-CNN中的CNN用“inception”模块代替,赢得了ILSVRC 2014目标检测挑战;除了R-CNN,还有一个Fast R-CNN,喂给CNN的图片不再是变形成一样尺寸的图片了,还用了很多方法提高速度。但是这些都只是在静态图片上的目标检测,在视频检测中,这些方法不一定可以捕捉所有的真实目标,因为有些帧中的目标并不在最容易检测到的姿势或者状态。
基于YouTube Object Dataset(YTO)的目标定位和协同定位与VID任务类似,但这两者又有一些不同:1、YTO假设每一个VID只有一个已知的或未知的目标类别,只要求每一帧检测出一个目标,但是VID每一帧包含未知数量的目标,更接近于真实情况;2、YTO用localization metric来做衡量标准,而VID使用mean average precision(mAP)作为性能衡量标准。对于评估不同种类和阈值的总体性能,mAP更有挑战性。基于这些不同,VID任务难度更大,更接近真实情况,所以之前的目标定位并不能直接应用于VID。
还有一些方法是关于动作定位的,在动作视频的每一帧,要求系统将人物动作的区域用bounding box标注出来,这些关于动作proposal的工作与这篇论文的工作有关系。Yu和Yuang等人通过计算actionness scoring来确定这些bounding box,并解决了最大集覆盖问题maximum set coverage problem;Jain等人的工作是使用Selective Search方法来确定tubelet proposals,并且产生区分人的动作和背景的新特征;在CVPR2014的Finding action tubes一文中,候选区域被喂给两个CNN来学习特征,接着用SVM来对动作进行预测,这些候选区域可以通过预测和空间上的重叠连接起来。
目标跟踪的研究已经进行很久了,最近,将deep CNN运用在目标检测上得到了很好的效果:Wang研究了一种特定目标跟踪器,从ImageNet预训练网络中选择最有影响力的特征;Nam训练了一种多领域的CNN来做目标跟踪,在跟踪新目标时,创造一个新的网络,将原有的预训练CNN的共享层与一个新的二分层结合。但是,即使是基于CNN的跟踪器,性能依旧不是很好,因为它们还是依靠目标外表信息而不是理解目标种类的语义。
3. Method
在这一部分,我们会介绍视频目标检测和我们这个网络架构的细节,框架的总体结构如Figure 2所示,主要包含两个模块:一个spatio-temporal tubelet proposal模块和一个tubelet分类和重得分模块。这两个主要部分将会在3.2和3.3详细阐述。

3.1 Task setting
在静态图片中,视频目标检测任务VID与图像识别任务DET是类似的,从图像识别任务的200个类别中取30个类别进行目标检测,每一个视频中的所有类别都是完全标注的。对于每一个视频段,算法需要得到一个标注数组(fi, ci, si, bi),fi代表帧数,ci代表种类标签,si代表确信值,bi代表bounding box。在VID中,我们也用与DET一样的评价标准:mAP。
3.2 Spatio-temporal tubelet proposal
视频中的目标有时间和空间上的连续性,在相邻的帧中,同一个目标有相似的表现和位置。而用现有的目标检测和目标跟踪的方法并不能有效的解决VID任务,一方面,一个简单的方法就是把视频当做多个图像的组合,对每一张图像进行独立的目标检测,这个策略只考虑到了目标外表的相似性而没有考虑到时间上的连续性,所以从Figure 1 (a)中看到,即使是相邻的帧,其检测score也有很大的波动;另一方面,普遍的目标检测方法将正在检测的bounding box当做样本来更新检测器,检测器会集中于视频中的样本,由于目标的大幅度变化而出现漂移现象(Figure 1 (b))。
spatio-temporal tubelet proposal模块将静态图像的识别和目标检测、目标跟踪结合起来,模块对于目标检测器和目标跟踪的时间连续性是有区分能力的。有三个主要步骤:image object proposal, object proposal scoring和high-confidence object tracking。
step 1 Image object proposal object proposals是由Selective Search(SS)算法得到的,对于视频的每一帧,SS输出大约2000个proposals,大多数是负样本,不包含目标。当一个proposal对于ImageNet的所有分类的detection score都低于一个阈值时,用R-CNN中提供的预训练的AlexNet模型将这些显而易见是负样本的样本移除。实验中使用-1.1作为阈值,大概会剩下6.1%的候选区域。这一步骤见Figure 2 (a)。
step 2 Object proposal scoring 由于VID的30个分类是从DET的200个分类的子集,所以为DET任务训练的网络可以直接用于VID任务,网络是一个在ImageNet上预训练的GoogLeNet,然后根据DET任务进行微调。同R-CNN一样,对于每一个DET分类,用模型中提取的“pool5”特征来做hard negative mining,用于SVM的训练。在VID任务中,用30个SVM来对proposals进行分类,SVM得分越高,proposal中含有目标的可能性就越大。
step 3 High-confidence proposal tracking 对于每个分类,我们双向跟踪高置信度的detection proposals。所用追踪器是Visual tracking with fully convolutional networks这篇论文提到的,在实验中有更加鲁棒的性能。从step 2中选择最高置信度的proposal,作为检测开始的位置,被称为“anchors”,从一个anchor开始,前至第一帧,后至最后一帧,用两个tracklet连接出了目标的轨迹。当目标运动,从anchor中离开时,追踪器有可能会飘到背景或者其他目标上,或者跟不上原先目标的尺寸和状态,所以,当确信度低于一个阈值时(通常取0.1),我们尽早停止追踪,以防出现错误的tracklet。在得到一条轨迹之后,从剩下的检测目标中挑选一个新的anchor,一般来说,高确信的目标通常会成群出现,所以直接选取下一个高确信度的目标很可能会与原先的tracklet有重合,为了减少冗余,我们用一些抑制方法,比如非最大值抑制。当step 2中的检测目标与现有的轨迹有超过一个阈值的重合度时(通常采用0.3IoU),不会将其选为新的anchor。这个追踪-抑制过程持续到所有剩下的目标都低于一个阈值为止(通常选取SVM得分小于0)。每一个视频中,这个过程要对所有的30个类别都进行一次。
基于以上三个步骤,我们得到了从高确信anchor开始的轨迹,这个轨迹就是tubelet proposals。
3.3 Tubelet classification and rescoring
在tubelet proposal模块之后,对于每一个分类,我们都有了含有高确信值的anchor的tubelet,一种简单的方法是对于这些tubelets中的bounding-box采用step 2中的方法进行分类,但是这种方法的性能比静态图像识别要差,有以下四条原因:
1、在tubelet中的proposal数量远远少于Selective Search之后的proposal,有可能会错过一些目标,降低召回率。
2、在静态图像识别中训练的检测器对于目标的移动是很敏感的(Figure 2 (d)),即使一个轨迹边框与目标的重合度很大,它也可能没有合理的检测得分。
3、在追踪过程中,我们为了减少冗余tubelets会进行抑制操作,所以相对于图像proposal来说,tubelet会更稀少。这种抑制方法与非最大值抑制(NMS)有冲突,因为在传统NMS中,即使一个正边框的确信值很低,但它与其他高确信值的边框有很大的重合,它就会被抑制,不会影响总平均精确度。而早期抑制导致有一些低确信值的正边框与高确信值的检测结果没有重合,所以没有被抑制。
4、即使在已经标注过的数据上,tubelet上的检测得分也是波动很大(Figure 1 (a)),所以我们还需要利用时间信息得到连续的检测得分。
step 4 Tubelet box perturbation and max-pooling 这一步骤是将tubelet中的box用更高确信度的box替换,有两种扰动方法。
第一种扰动方法是随机扰动tubelet box的边框以在每一帧的每一个box旁边产生新的box,就是指我们随机对一个tubelet box的左上角和右下角的坐标进行采样。随机偏置的值来自于下面两个分布:
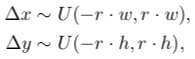
U是均匀分布,w和h是box的宽度和高度,r是采样率参数,r越高代表原来的box确信值越低。
第二种扰动方法是用与这个tubelet box的重合度高于一个阈值的object detections代替这个tubelet box。这个步骤模拟NMS过程:如果这个box是一个有低确信度的正边框,这个过程可以恢复一些其他的正边框来抑制这个边框。衡量重合度的阈值越高,tubelet box的确信度就越高。
上述两种方法都在4. Experiments中。
在perturbation结束后,每一个增强后的边框和原来的tubelet box都用step 2中的方法得到score。对于每一个tubelet box,只有检测确信值最大的、增强后的box被保留下来,并替代原来的tubelet box。这种最大值池化的过程是为了增强检测器的空间鲁棒性,并利用tubelet周围的object detections。
step 5 Temporal convolution and re-scoring 即使有max-pooling这个步骤,同一轨迹上的detection scores也会有很大的波动,会导致性能损失。例如,如果在相邻帧上的tubelet boxes都有高检测得分,那这一帧上的同样的物体的tubelet box很可能也有高检测得分,而静态图片目标检测没有考虑这种时间连续性。
在我们的框架中,添加了一个Temporal Convolutional Network(TCN),TCN使用一维特征,包括检测得分detection scores、跟踪得分tracking scores、anchor offsets,还对每一个tubelet box标注temporally dense prediction(dense prediction要求不但给出具体目标的位置,还要描绘物体的边界,如图像分割、语义分割、边缘检测等等,翻译取密集标注)。
TCN的结构见Figure 3,它是一个四层一维全卷积网络,输出每一个tubelet box的temporally dense prediction score。对于每一个分类,我们都用tubelet特征作为输入,训练一个针对类别的TCN。输入值是时间序列,包括检测得分、跟踪得分和anchor offsets,输出值是tubelet box是否包含目标的可能性。如果box与已经标定为真的数据重合度大于0.5,则监督标签为1,反之则为0。
这种temporal convolution基于感受野中的时间特征来产生分类预测,而一维密集标注提供了比单一标注更复杂的信息。在测试中,我们用连续score代替了二值分类。