knn原理及其python实现
k近邻
顾名思义,是k个最近邻居。
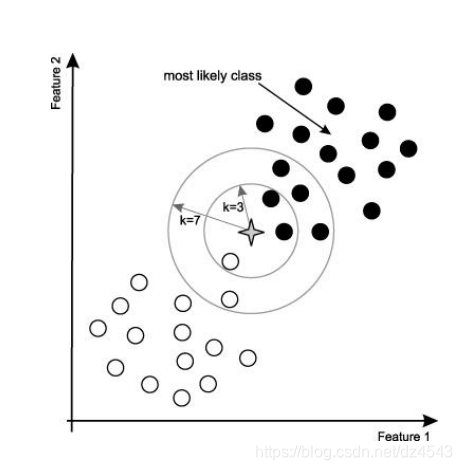
比如说上图,有2类,黑点和白点。那么怎么划分星号?
按照knn来说,会寻找最近的几个点。比如说,当k=3时,是2个黑点,1个白点,黑点投票多,所以被分为黑点。当k=7的时候,是5个黑点,2个白点,黑点投票多,更加nearest黑点一些,也是被划分为黑点。
k必须是奇数不能为偶数?
当然并不是绝对的。
比如当k=4时,黑点是2个,白点是2个,这样怎么划分?
假设这四个点到星号点(测试点)的距离为 ,前二者 属于黑点,后二者 属于白点。从距离来看,星号点距离黑点要近一点,应该划分为为黑点。
所以我们可以这么做,以距离做个加权,比如取距离倒数为权重,越远则权重越小。由此可见k为偶数也是可以的。
knn for prediction
比如你要估计一个同学的成绩,虽然不知道他的成绩,但如果你知道他朋友(neighbors)的成绩,我们可以取其k个朋友的成绩的均值作为他的成绩
代码测试
- 生成数据,使用sklearn方便点
#导入的包
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from collections import Counter
data = make_blobs(n_samples=200,centers=2)#生成数据,200个点,2类
X,y = data #划分为x,y
X_test = np.array([6,4])#测试数据,随便写的
#显示
plt.scatter(X[:,0],X[:,1], c=y, cmap = plt.cm.spring, edgecolor='k')
plt.scatter(x[0],x[1], color = 'b')#测试点,蓝色的点
plt.show()
生成的数据如下图:
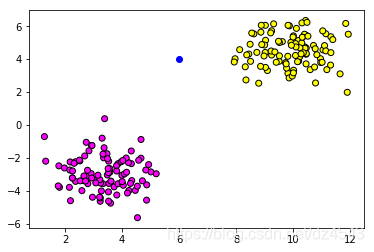
从图中来看似乎离黄色更近。当然,由于没固定种子,每次运行生成的数据都不一样,这里仅做展示。
- 计算测试点与所有样本的欧氏距离:
distance = [sqrt(np.sum((X_train-x)**2)) for X_train in X]#计算距离,这里是欧式距离
当然如果不嫌麻烦也可以这么写:
distance = []
for x_train in X:
d = sqrt(np.sum(x-x_train)**2)#俩个向量相减仍是向量,向量元素平方后求和
distance.append(d)
- 排序求最近邻
nearest = np.argsort(distance)#对distance排序,返回的是增序的索引
k=3#定义k,即使用k个近邻
top_k_y=[y[i] for i in nearest[:k]]#最近的k个测试集的类别
votes = Counter(top_k_y)#Counter是个类,
prediction = votes.most_common(1)[0][0]#带参数1,意思是计算投票数最高的,设2即计算前2个最高的
的返回是个列表依次存放降序投票数目的列表。比如,带入参数2(即计算投票数排前2名的结果),其结果如下:
运行:
votes.most_common(2)
结果:
[(1,2),(0,1)]
这表示属于’1’类的紧邻有2个,属于’0’类的有1个,这种情况下,测试集就属于0类了