论文:
本文主要贡献:
1、提出了一种新的采样策略,使网络在少数的epoch迭代中,接触百万量级的训练样本;
2、基于局部图像块匹配问题,强调度量描述子的相对距离;
3、在中间特征图上加入额外的监督;
4、描述符的紧实性。
基于CNN的局部图像块匹配方法可以分为两类:一是,作为二分类问题,不存在明确的特征描述子概念,好处是准确率相对第二类高很多,但可移植性能差;二是,CNN输出学习的图像块描述子,没有度量学习层,好处是可以作为以前的很多基于手工描述子方法应用的直接替代。
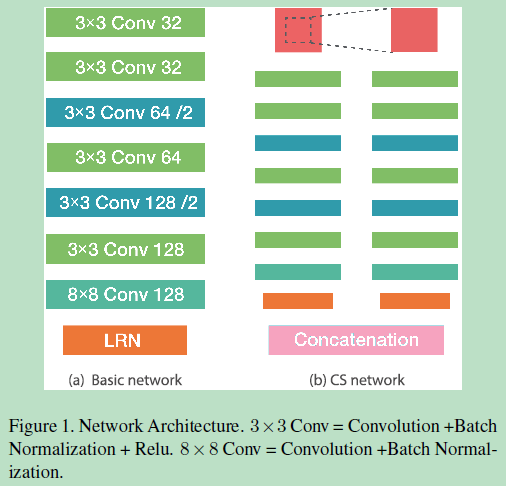
A、网络框架:
左边是输入:32*32*1图像块,输出128的特征描述子;右边是双塔结构,The input of the tower on the left is the same with a solo L2-Net, while the input of the tower on the right is generated by cropping and resizing the central part of the original patches.
B、数据集
Brown dataset 和HPatches dataset 数据集
C、训练数据的采样策略
由于采集的数据patch中正负样本极度不平衡,大量的负样本,之前的方法是选取等量的正负样本作为固定的训练数据集,但这违背了实际中测试数据存在大量负样本的事实。本文采用随机采样的方式, ,其中1和2是匹配点对,经过特征提取网络得到
,其中1和2是匹配点对,经过特征提取网络得到 ,通过L2范数计算特征描述子的距离矩阵,其大小为p*p,对角线上的是正样本点对距离,其他位置是负样本。
,通过L2范数计算特征描述子的距离矩阵,其大小为p*p,对角线上的是正样本点对距离,其他位置是负样本。

D、损失函数
包括三个方面:
- (1)描述子相似性。相对的距离度量匹配和不匹配图像块对;
- (2)描述子的紧实性。让更少维度的描述子包含足够多的特征信息,减少冗余,也就是说描述子的维度尽量减少相关性冗余;
- (3)在特征提取网络中间层的特征图增加约束,而不只是在最后,匹配的特征图更相近,不匹配远离。
E、训练及预测
左边框架正常输入64*64*1图像块;右边训练时,用训练好的左边框架参数初始化双塔结构的左边网络,左边固定不变,更新右边参数直至收敛。
数据扩充方式:垂直、水平翻转;选择90,180,270度。


结论:
(1)紧致性学习很重要。由于数据量巨大,对于网络来说,记住数据比学习泛化性特征更容易些,因此如果没有这个约束,网络过拟合严重,学习输出的特征相关性较大,存在特征维度的冗余,因此紧致性约束的重要性高于训练数据选择的策略,同时解决了过拟合问题;
(2)训练样本的选择策略很重要,充分利用数据。
(3)损失函数的设计,从多个角度约束特征描述子的学习,得到更紧致的特征,特征图的约束提高了网络性能。