本文参考:
a. https://www.jianshu.com/p/c46bfaa5dd15
1. shuffle及历史简介
shuffle,即"洗牌",所有采用map-reduce思想的大数据计算框架的必经及最重要的阶段。顾名思义,其处于map与reduce之间,可分为2个子阶段:
a. shuffle write: map任务(spark中为ShuffleMapTask)写上游计算产生的中间数据
b. shuffle read: reduce任务(spark中为ResultTask)读取map任务产生的中间数据,用于下游计算或处理
下图示出Hadoop MapReduce框架中,shuffle发生的机制与细节。

图中可以看出:map任务阶段输入数据经分区、排序以及溢写磁盘(生成临时文件),然后在磁盘上进行合并(一个map输出一个文件),而reduce任务将获取并合并多个map任务产生的文件,进行后续处理。
Spark的shuffle机制虽然也采用MR思想,但Spark是基于RDD进行计算的,实现方式与Hadoop有差异,并且中途经历了比较大的变动,简述如下:
a. 在久远的Spark 0.8版本及之前,只有最简单的hash shuffle,后来引入了consolidation机制

b. 1.1版本新加入sort shuffle机制,但默认仍然使用hash shuffle
c. 1.2版本开始默认使用sort shuffle
d. 1.4版本引入了tungsten-sort shuffle,是基于普通sort shuffle创新的序列化shuffle方式
e. 1.6版本将tungsten-sort shuffle与sort shuffle合并,由Spark自动决定采用哪一种方式
f. 2.0版本之后,hash shuffle机制被删除,只保留sort shuffle机制至今
下面的代码分析致力于对Spark shuffle先有一个大致的了解。
2. shuffle机制的最顶层: ShuffleManager特征
(1) ShuffleManager的创建位置
shuffle机制的初始化是在Spark执行环境初始化时执行。在创建driver端环境(SparkContext中)和executor端环境(ExecutorBackend)时,会进行创建。主要调用org.apache.spark.SparkEnv的create方法,来构建ShuffleManager。其主要代码如下:
// Let the user specify short names for shuffle managers // 注意sort, tungsten-sort对应的value均是SortShuffleManager val shortShuffleMgrNames = Map( "sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName, "tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName) // 通过配置文件获取manager类名 val shuffleMgrName = conf.get("spark.shuffle.manager", "sort") // 获取shuffle manager对应的类名,包括SortShuffleManager或从配置中获取的 val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName) // 通过反射构建ShuffleManager实例 val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
上面的代码中,可以看到已经没有了hash shuffle的存在。此外,也可以通过spark.shuffle.manager参数来指定第三方或其他方式实现的shuffle机制。
(2) ShuffleManager特征
ShuffleManager是一个scala特征。其代码如下:
package org.apache.spark.shuffle import org.apache.spark.{ShuffleDependency, TaskContext} /** * Shuffle系统的可插拔接口。ShuffleManager的创建基于spark.shuffle.manager设置, * 且在SparkEnv中的driver和每个executor上创建。driver在该shuffle manager上注册shuffle,executor(或者driver中本地运行的任务) * 能够请求读取或写入数据。 * * 注意:shuffle manager会在SparkEnv中实例化,因此其构造函数可将SparkConf和boolean isDriver作为参数 */ private[spark] trait ShuffleManager { /** * 使用ShuffleManager注册一个shuffle,获取一个句柄,以传到任务中 */ def registerShuffle[K, V, C]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle /** 为一个指定的分区提供ShuffleWriter,在map任务期间的executor调用 */ def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V] /** * 为一个范围(开始分区到结束分区-1, 闭区间)内的reduce分区提供ShuffleReader。在reduce任务期间的executor调用 */ def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C] /** * 从ShuffleManager移除shuffle的元数据 * @return 移除成功返回true, 否则为false.*/ def unregisterShuffle(shuffleId: Int): Boolean /** * 返回一个能够基于block坐标位置获取shuffle块数据的解析器 */ def shuffleBlockResolver: ShuffleBlockResolver /** Shut down this ShuffleManager. */ def stop(): Unit }
其中:
a. registerShuffle方法用于注册一种shuffle机制,并返回对应的ShuffleHandle,handle内会存储shuffle依赖信息。根据该handle类型可以进一步确定采用ShuffleWriter类型。
b. getWriter方法用于获取ShuffleWriter,它是executor执行map任务时调用的
c. getReader方法用于获取ShuffleReader,它是executor执行reduce任务时调用的
d. unregisterShuffle用于取消shuffle的注册
e. shuffleBlockResolver用于获取能够定位shuffle块的解析器
3. SortShuffleManager
hash shuffle取消之后,org.apache.spark.shuffle.sort.SortShuffleManager就是ShuffleManager目前唯一的实现类。
(1) registerShuffle方法
/** * 获取一个ShuffleHandle传入到tasks. */ override def registerShuffle[K, V, C]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle = { if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) { // 如果分区数小于spark.shuffle.sort.bypassMergeThreshold(默认为200)并且不需要map端的聚合,则可以直接写对应分区个数的 // 文件,且在结束时仅仅合并它们。可以避免2次序列化和反序列化操作以将溢写的文件合并在一起(正常的代码方法会发生这种情况)。 // 其缺点是一次打开多个文件,因此需要分配缓冲区更多的内存。 new BypassMergeSortShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else if (SortShuffleManager.canUseSerializedShuffle(dependency)) { // 否则,尝试以序列化形式缓存map输出,且这样做更高效(需要满足一定条件) new SerializedShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else { // 否则,以反序列化形式缓存map输出 new BaseShuffleHandle(shuffleId, numMaps, dependency) } }
可以看出,根据条件的不同,返回不同的handle。下面依次分析3中shuffle机制。
1) 检查是否满足SortShuffleWriter.shouldBypassMergeSort条件
private[spark] object SortShuffleWriter { def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = { // 如果需要map端聚合,则不能跳过排序 if (dep.mapSideCombine) { false } else { val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200) dep.partitioner.numPartitions <= bypassMergeThreshold } } }
代码中表示,如果同时满足一下两个条件,那么会返回ByPassMergeSortShuffleHandle,将启用bypass merge-sort机制
a. 该shuffle依赖中没有map端聚合操作(如groupByKey)
b. 依赖分区数不大于spark.shuffle.sort.bypassMergeThreshold规定的值,默认值为200
2) 如果不启用bypass机制,继续检查是否符合SortShuffleManager.canUseSerializedShuffle方法
/** * 一个帮助类,用于决定shuffle应该使用一个优化的序列化shuffle方法,还是应该退回到操作反序列化对象的原始方法 */ def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = { val shufId = dependency.shuffleId val numPartitions = dependency.partitioner.numPartitions if (!dependency.serializer.supportsRelocationOfSerializedObjects) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " + s"${dependency.serializer.getClass.getName}, does not support object relocation") false } else if (dependency.mapSideCombine) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " + s"map-side aggregation") false } else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " + s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions") false } else { log.debug(s"Can use serialized shuffle for shuffle $shufId") true } }
可以看出,如果同时满足3个条件,就会返回SerializedShuffleHandle,启用序列化Sort shuffle机制(也就是tungsten-sort):
a. 使用的序列化器支持序列化对象的重定位(KyroSerializer)
b. shuffle依赖中map端无聚合操作
c. 分区数不大于MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE的值,即2^24
3) 既不用bypass,也不用tungsten-sort,那么就返回默认的BaseShuffleHandle,采用基本的sort handle
(2) getWriter方法
基于不同的handle,获取相应的ShuffleWriter。
/** 为指定的分区获取ShuffleWriter,在executor执行map任务时调用 */ override def getWriter[K, V]( handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V] = { numMapsForShuffle.putIfAbsent( handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps) val env = SparkEnv.get handle match { case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] => new UnsafeShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], context.taskMemoryManager(), unsafeShuffleHandle, mapId, context, env.conf) case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] => new BypassMergeSortShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], bypassMergeSortHandle, mapId, context, env.conf) case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] => new SortShuffleWriter(shuffleBlockResolver, other, mapId, context) }
对于tungsten-sort会使用UnsafeShuffleWriter,对于bypass会使用BypassMergeSortShuffleWriter,普通的sort则使用SortShuffleWriter。都继承于ShuffleWriter抽象类,且实现了write方法。
(3) getReader方法
/** * 为一个范围(开始分区到结束分区-1, 闭区间)内的reduce分区提供ShuffleReader。在executor执行reduce任务时调用 */ override def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C] = { new BlockStoreShuffleReader( handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context) }
ShuffleReader与ShuffleWriter不同,只有一种实现类,即BlockStoreShuffleReader。它继承自ShuffleReader特征,并实现了read方法。
4. 总结
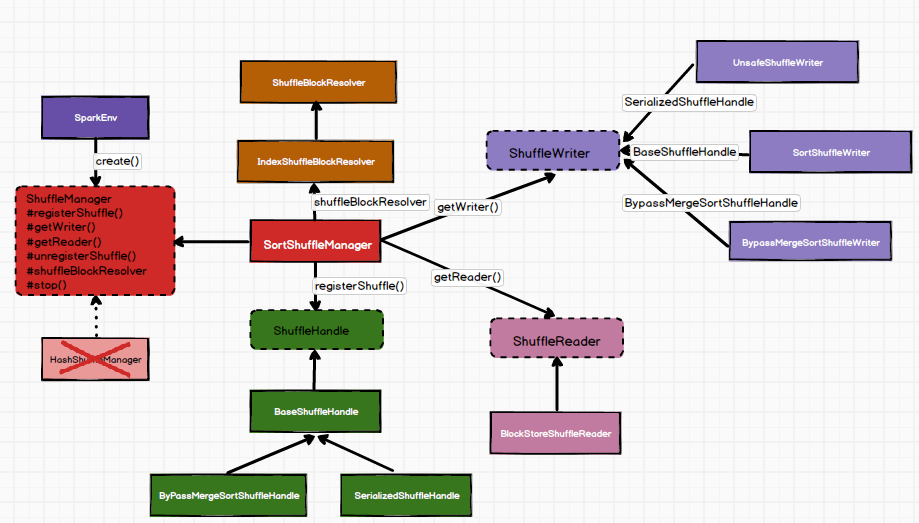
5. 附录
(1) SortShuffleManager的完整阅读代码


package org.apache.spark.shuffle.sort import java.util.concurrent.ConcurrentHashMap import org.apache.spark._ import org.apache.spark.internal.Logging import org.apache.spark.shuffle._ /** * 基于排序的shuffle中, 输入数据根据它们的分区id进行排序, 然后写入到一个单独的map输出文件。Reducers获取此文件的 * 连续区域以读取它们的map输出部分。当遇到输出文件过大而内存无法满足时,该output的排序后的子集将溢写磁盘,并且溢写磁盘 * 的文件将被合并,以产生最终的输出文件。 * * 基于排序的shuffle有2种不同的写方法来产生其map输出文件: * 1. 序列化排序:当满足如下3个条件时可以使用 * a. shuffle依赖不指定任何聚合(aggregation)或输出排序 * b. shuffle的序列化器(serializer)支持序列化值的重定位(当前KyroSerializer和Spark SQL中自定义的序列化器满足) * c. shuffle产生的输出分区数需小于2^24个 * 2.发序列化排序:用于处理其他情况 * ----------------------- * 序列化排序方法 * ----------------------- * 在序列化排序模式中,输入数据一经传入shuffle writer即被序列化,并且排序过程中以序列化的形式缓存。这种写方法实现了 * 如下几种优化: * a.其排序作用于序列化的二进制数据,而非Java对象,可以减小内存占用和GC开销。这种优化需要数据序列化器具有某些属性,以允许 * 序列化的数据无需反序列化就可以被重排序。了解更多细节,可查看SPARK-4550 * b.其使用一种特殊的高效缓存排序器ShuffleExternalSorter,对压缩数据的指针和分区Id的数组进行排序。排序数组中每条记录仅 * 使用8 byte,使得更多的数组适于缓存 * c.溢出合并流程作用于属于同一个分区的序列化记录的block上,并且在合并期间无需反序列化记录 * d.当溢出压缩编码支持压缩数据的拼接(concatenation)时,溢出合并仅仅拼接序列化且压缩的溢出分区,以产生最终的输出分区。 * 此过程允许使用有效的数据拷贝方法,例如NIO的transferTo,而且避免合并期间分配解压缩或拷贝缓存的需要。 */ private[spark] class SortShuffleManager(conf: SparkConf) extends ShuffleManager with Logging { // Spark1.6+之后,已强制溢写磁盘 if (!conf.getBoolean("spark.shuffle.spill", true)) { logWarning( "spark.shuffle.spill was set to false, but this configuration is ignored as of Spark 1.6+." + " Shuffle will continue to spill to disk when necessary.") } /** * shuffle id到为这些shuffle产生输出的mapper数量的映射 */ private[this] val numMapsForShuffle = new ConcurrentHashMap[Int, Int]() // 创建并维护逻辑block和物理文件位置之间的shuffle block映射关系 override val shuffleBlockResolver = new IndexShuffleBlockResolver(conf) /** * 获取一个ShuffleHandle传入到tasks. */ override def registerShuffle[K, V, C]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, C]): ShuffleHandle = { if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) { // 如果分区数小于spark.shuffle.sort.bypassMergeThreshold(默认为200)并且不需要map端的聚合,则可以直接写对应分区个数的 // 文件,且在结束时仅仅合并它们。可以避免2次序列化和反序列化操作以将溢写的文件合并在一起(正常的代码方法会发生这种情况)。 // 其缺点是一次打开多个文件,因此需要分配缓冲区更多的内存。 new BypassMergeSortShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else if (SortShuffleManager.canUseSerializedShuffle(dependency)) { // 否则,尝试以序列化形式缓存map输出,且这样做更高效(需要满足一定条件) new SerializedShuffleHandle[K, V]( shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]]) } else { // 否则,以反序列化形式缓存map输出 new BaseShuffleHandle(shuffleId, numMaps, dependency) } } /** * 为一个范围(开始分区到结束分区-1, 闭区间)内的reduce分区提供ShuffleReader。在executor执行reduce任务时调用 */ override def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C] = { new BlockStoreShuffleReader( handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context) } /** 为指定的分区获取ShuffleWriter,在executor执行map任务时调用 */ override def getWriter[K, V]( handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V] = { numMapsForShuffle.putIfAbsent( handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps) val env = SparkEnv.get handle match { case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] => new UnsafeShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], context.taskMemoryManager(), unsafeShuffleHandle, mapId, context, env.conf) case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] => new BypassMergeSortShuffleWriter( env.blockManager, shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver], bypassMergeSortHandle, mapId, context, env.conf) case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] => new SortShuffleWriter(shuffleBlockResolver, other, mapId, context) } } /** 从ShuffleManager移除shuffle的元数据. */ override def unregisterShuffle(shuffleId: Int): Boolean = { Option(numMapsForShuffle.remove(shuffleId)).foreach { numMaps => (0 until numMaps).foreach { mapId => shuffleBlockResolver.removeDataByMap(shuffleId, mapId) } } true } /** 关闭ShuffleManager. */ override def stop(): Unit = { shuffleBlockResolver.stop() } } private[spark] object SortShuffleManager extends Logging { /** * 当以序列化形式缓冲map输出时,SortShuffleManager支持的最大shuffle输出分区数。 * 这是这一种极端防御性编程措施,单个shuffle不能产生超过1600W个输出分区 * */ val MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE = PackedRecordPointer.MAXIMUM_PARTITION_ID + 1 /** * 一个帮助类,用于决定shuffle应该使用一个优化的序列化shuffle方法,还是应该退回到操作反序列化对象的原始方法 */ def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = { val shufId = dependency.shuffleId val numPartitions = dependency.partitioner.numPartitions if (!dependency.serializer.supportsRelocationOfSerializedObjects) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " + s"${dependency.serializer.getClass.getName}, does not support object relocation") false } else if (dependency.mapSideCombine) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " + s"map-side aggregation") false } else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) { log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " + s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions") false } else { log.debug(s"Can use serialized shuffle for shuffle $shufId") true } } } /** * BaseShuffleHandle的子类, 用于标识何时选择使用序列化shuffle */ private[spark] class SerializedShuffleHandle[K, V]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, V]) extends BaseShuffleHandle(shuffleId, numMaps, dependency) { } /** * BaseShuffleHandle的子类, 用于标识何时选择使用bypass merge sort shuffle */ private[spark] class BypassMergeSortShuffleHandle[K, V]( shuffleId: Int, numMaps: Int, dependency: ShuffleDependency[K, V, V]) extends BaseShuffleHandle(shuffleId, numMaps, dependency) { }
(2) ShuffleBlockResolver特征的源码
package org.apache.spark.shuffle import org.apache.spark.network.buffer.ManagedBuffer import org.apache.spark.storage.ShuffleBlockId private[spark] /** * 该特征的实现类了解如何检索逻辑shuffle block(即map, reduce和shuffle)的block数据。实现类可使用文件或文件段(file segment) * 封装shuffle数据。当检索shuffle数据时,BlockStore使用它来抽象化不同的shuffle实现 */ trait ShuffleBlockResolver { type ShuffleId = Int /** * 检索指定的块数据. 如果块数据不可用,则抛出无法指定的异常(unspecified exception) */ def getBlockData(blockId: ShuffleBlockId): ManagedBuffer def stop(): Unit }
(3) IndexShuffleBlockResolver继承类源码解读
package org.apache.spark.shuffle import java.io._ import java.nio.channels.Channels import java.nio.file.Files import org.apache.spark.{SparkConf, SparkEnv} import org.apache.spark.internal.Logging import org.apache.spark.io.NioBufferedFileInputStream import org.apache.spark.network.buffer.{FileSegmentManagedBuffer, ManagedBuffer} import org.apache.spark.network.netty.SparkTransportConf import org.apache.spark.shuffle.IndexShuffleBlockResolver.NOOP_REDUCE_ID import org.apache.spark.storage._ import org.apache.spark.util.Utils /** * 创建并维护shuffle block在逻辑块和物理文件位置的映射关系。相同map任务的shuffle块数据存储于一个单独统一的数据文件中。 * 数据文件中数据块的偏移(offset)则存储于另一个额外的索引文件。 * * shuffle数据的命名构建:shuffle数据的shuffleBlockId的名称,设置为0的reduce ID以及".data"作为后缀。 * 索引文件不同之处在于后缀为".index" * */ // Note: Changes to the format in this file should be kept in sync with // org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getSortBasedShuffleBlockData(). private[spark] class IndexShuffleBlockResolver( conf: SparkConf, _blockManager: BlockManager = null) extends ShuffleBlockResolver with Logging { // _blockManager默认为空,当未指定时,将从SparkEnv中进行获取 private lazy val blockManager = Option(_blockManager).getOrElse(SparkEnv.get.blockManager) // SparkTransportConf用于将Spark JVM中(如Executor, Driver或一个独立部署的shuffle服务)的SparkConf转换为TransportConf(包含 // 环境细节,比如分配到JVM中的核数) // transportConf包含shuffle.io.serverThreads和shuffle.io.clientThreads等配置属性 private val transportConf = SparkTransportConf.fromSparkConf(conf, "shuffle") def getDataFile(shuffleId: Int, mapId: Int): File = { blockManager.diskBlockManager.getFile(ShuffleDataBlockId(shuffleId, mapId, NOOP_REDUCE_ID)) } private def getIndexFile(shuffleId: Int, mapId: Int): File = { blockManager.diskBlockManager.getFile(ShuffleIndexBlockId(shuffleId, mapId, NOOP_REDUCE_ID)) } /** * 从一个map中移除包含输出文件的数据文件和索引文件 */ def removeDataByMap(shuffleId: Int, mapId: Int): Unit = { var file = getDataFile(shuffleId, mapId) if (file.exists()) { if (!file.delete()) { logWarning(s"Error deleting data ${file.getPath()}") } } file = getIndexFile(shuffleId, mapId) if (file.exists()) { if (!file.delete()) { logWarning(s"Error deleting index ${file.getPath()}") } } } /** * 检测给定的索引和数据文件是否匹配。如果匹配,返回数据文件中的各分区对应的长度,否则返回null */ private def checkIndexAndDataFile(index: File, data: File, blocks: Int): Array[Long] = { // the index file should have `block + 1` longs as offset. if (index.length() != (blocks + 1) * 8L) { return null } val lengths = new Array[Long](blocks) // Read the lengths of blocks val in = try { new DataInputStream(new NioBufferedFileInputStream(index)) } catch { case e: IOException => return null } try { // Convert the offsets into lengths of each block var offset = in.readLong() if (offset != 0L) { return null } var i = 0 while (i < blocks) { val off = in.readLong() lengths(i) = off - offset offset = off i += 1 } } catch { case e: IOException => return null } finally { in.close() } // the size of data file should match with index file if (data.length() == lengths.sum) { lengths } else { null } } /** * 写一个包含每个块偏移量的索引文件,写结束时需要为输出文件的结尾加上最终的偏移。getBlockData将使用这个方法来指定每个 * 块的结束和开始。 * * 提交数据和索引文件的操作为原子操作,使用现有的或用新的替换。 * * 注意:当使用现有索引时,lengths将被更新以匹配现有索引文件 */ def writeIndexFileAndCommit( shuffleId: Int, mapId: Int, lengths: Array[Long], dataTmp: File): Unit = { val indexFile = getIndexFile(shuffleId, mapId) val indexTmp = Utils.tempFileWith(indexFile) try { val dataFile = getDataFile(shuffleId, mapId) // 每个executor种仅有一个IndexShuffleBlockResolver, synchronization确保如下的check和rename是原子性的 synchronized { val existingLengths = checkIndexAndDataFile(indexFile, dataFile, lengths.length) if (existingLengths != null) { // 同一个任务的另一个尝试已经成功写了map输出,因此只需要使用已存在的分区长度,并且删除临时map输出 System.arraycopy(existingLengths, 0, lengths, 0, lengths.length) if (dataTmp != null && dataTmp.exists()) { dataTmp.delete() } } else { // 当前任务第一次成功尝试写map输出,因此以我们已写的索引和数据文件替换任何已经存在的索引和数据文件 val out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(indexTmp))) Utils.tryWithSafeFinally { // 我们去每个块的长度,需要将其转化为偏移量 var offset = 0L out.writeLong(offset) // 注意,先写如一个0偏移量 for (length <- lengths) { offset += length out.writeLong(offset) } } { out.close() } // 删除已存在的index和data文件 if (indexFile.exists()) { indexFile.delete() } if (dataFile.exists()) { dataFile.delete() } if (!indexTmp.renameTo(indexFile)) { throw new IOException("fail to rename file " + indexTmp + " to " + indexFile) } if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) { throw new IOException("fail to rename file " + dataTmp + " to " + dataFile) } } } } finally { if (indexTmp.exists() && !indexTmp.delete()) { logError(s"Failed to delete temporary index file at ${indexTmp.getAbsolutePath}") } } } // 基于blockId获取块数据 override def getBlockData(blockId: ShuffleBlockId): ManagedBuffer = { // 该block实际上将是该map的单个map输出文件的范围(range),因此找出已合并的文件,然后从索引中查找该文件的偏移量 val indexFile = getIndexFile(blockId.shuffleId, blockId.mapId) // SPARK-22982: if this FileInputStream's position is seeked forward by another piece of code // which is incorrectly using our file descriptor then this code will fetch the wrong offsets // (which may cause a reducer to be sent a different reducer's data). The explicit position // checks added here were a useful debugging aid during SPARK-22982 and may help prevent this // class of issue from re-occurring in the future which is why they are left here even though // SPARK-22982 is fixed. val channel = Files.newByteChannel(indexFile.toPath) channel.position(blockId.reduceId * 8L) val in = new DataInputStream(Channels.newInputStream(channel)) try { val offset = in.readLong() val nextOffset = in.readLong() val actualPosition = channel.position() val expectedPosition = blockId.reduceId * 8L + 16 if (actualPosition != expectedPosition) { throw new Exception(s"SPARK-22982: Incorrect channel position after index file reads: " + s"expected $expectedPosition but actual position was $actualPosition.") } new FileSegmentManagedBuffer( transportConf, getDataFile(blockId.shuffleId, blockId.mapId), offset, nextOffset - offset) } finally { in.close() } } override def stop(): Unit = {} } private[spark] object IndexShuffleBlockResolver { // No-op reduce ID used in interactions with disk store. // The disk store currently expects puts to relate to a (map, reduce) pair, but in the sort // shuffle outputs for several reduces are glommed into a single file. val NOOP_REDUCE_ID = 0 }