scikit-learn简称sklearn,支持包括分类、回归、降维和聚类四大机器学习算法。还包含了特征提取、数据处理和模型评估三大模块。sklearn是Scipy科学计算库的扩展,建立在NumPy和matplotlib库的基础上。利用这几大模块的优势,可以大大提高机器学习的效率。
Scikit-learn项目最早由数据科学家 David Cournapeau 在 2007 年发起,需要NumPy和SciPy等其他包的支持,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。
在Windows环境中,sklearn 需要在安装 numpy+mkl 和scipy 之后才可以安装,安装过程如下。
首先,下载Python scikit-learn,Windows版下载网站地址为:https://www.lfd.uci.edu/~gohlke/pythonlibs/,链接为scikit_learn‑0.19.1‑cp36‑cp36m‑win_amd64.whl。
安装操作如下:
D:\Python\Python36\Tools>pip install d:\python\scikit_learn-0.19.1-cp36-cp36m-win_amd64.whl
Processing d:\python\scikit_learn-0.19.1-cp36-cp36m-win_amd64.whl
Installing collected packages: scikit-learn
Successfully installed scikit-learn-0.19.1 以抽油机杆断脱工况为例,通过功图标准化数据集与该井理论功图库进行分类对比,确定抽油杆断脱对应特征。功图变窄用实测功图载荷差与理论功图载荷差的比值来表征;最大载荷偏离用(实测最大载荷-理论最小载荷)/理论功图载荷差来表征。
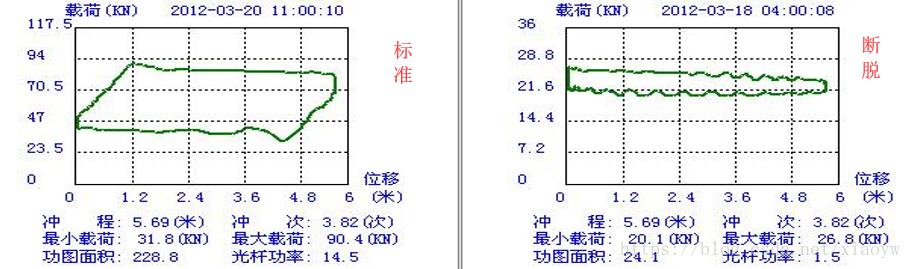
利用历史数据,给出抽油杆断脱的分类标识(断脱为1,非断脱为0),形成训练集。通过对大量抽油杆断脱井及非断脱井的宽窄偏离程度统计对比分析,确定断脱条件为T1(宽窄程度)小于74.5、T2(偏离程度)小于47.1,见下表:
| 油井 | T1 | T2 | 检泵原因 |
|---|---|---|---|
| 油井1 | 34.27258806 | 47.09825638 | 1 |
| 油井2 | 44.91577335 | 42.38897397 | 1 |
| 油井3 | 39.60183767 | 40.47473201 | 1 |
| 油井4 | 17.28699552 | 0 | 1 |
| 油井5 | 74.50145262 | 37.39663093 | 1 |
| 油井6 | 178.089172 | 131.0509554 | 0 |
| 油井7 | 177.4840764 | 129.9681529 | 0 |
| 油井8 | 182.0063694 | 133.9171975 | 0 |
| 油井9 | 178.8535032 | 133.4713376 | 0 |
| 油井10 | 180.6369427 | 135.2866242 | 0 |
利用决策树建立抽油杆断脱工况诊断模型。实测示功图经标准化处理提取特征信息,如果为错误功图则直接输出诊断结果,否则到达下一节点,进行断脱属性测试。此处节点分类权值为上一阶段训练集得出结果,如果符合断脱条件则输出诊断结果,不符合则继续进行其他工况诊断。如果准确率达不到期望值,可以重新调整特征信息。决策树部分示例代码如下:
import numpy as np
import scipy as sp
from sklearn import tree
from sklearn.cross_validation import train_test_split
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
def main():
data = []
lable= []
with open("decisiontree.txt") as ifile:
for line in ifile:
tmp = line.strip().split(' ')
tmp1=[]
for i in range(0,len(tmp)-1):
tmp1.append(float(tmp[i]))
data.append(tmp1)
lable.append(float(tmp[len(tmp)-1]))
x = np.array(data)
y = np.array(lable)
''''' 拆分训练数据与测试数据 '''
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
''''' 使用信息熵作为划分标准,对决策树进行训练 '''
clf = tree.DecisionTreeClassifier(criterion='entropy')
print(clf)
clf.fit(x_train, y_train)
''''' 把决策树结构写入文件 '''
with open("tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
''''' 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
print(clf.feature_importances_)
'''''测试结果的打印'''
answer = clf.predict(x_train)
print(x_train)
print(answer)
print(y_train)
print(np.mean( answer == y_train))
'''''准确率与召回率'''
precision, recall, thresholds = precision_recall_curve(y_train, clf.predict(x_train))
answer = clf.predict_proba(x)[:,1]
print(classification_report(y, answer, target_names = ['yes', 'no']))
if __name__ == '__main__':
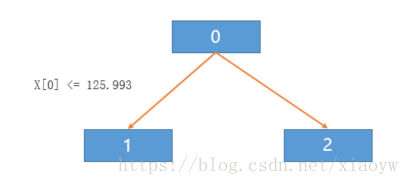
main()决策树的结构写入了tree.dot中,决策树结构如下(采用80%为训练数据,8条的结果,与引用文档所描述结果不一致):
digraph Tree {
node [shape=box] ;
0 [label="X[0] <= 125.993\nentropy = 0.954\nsamples = 8\nvalue = [3, 5]"] ;
1 [label="entropy = 0.0\nsamples = 5\nvalue = [0, 5]"] ;
0 -> 1 [labeldistance=2.5, labelangle=45, headlabel="True"] ;
2 [label="entropy = 0.0\nsamples = 3\nvalue = [3, 0]"] ;
0 -> 2 [labeldistance=2.5, labelangle=-45, headlabel="False"] ;
} 转化为决策树图形为:
运行程序结果如下,供参考:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
[1. 0.]
[[ 74.50145262 37.39663093]
[178.8535032 133.4713376 ]
[ 17.28699552 0. ]
[182.0063694 133.9171975 ]
[ 34.27258806 47.09825638]
[ 44.91577335 42.38897397]
[ 39.60183767 40.47473201]
[177.4840764 129.9681529 ]]
[1. 0. 1. 0. 1. 1. 1. 0.]
[1. 0. 1. 0. 1. 1. 1. 0.]
1.0
precision recall f1-score support
yes 1.00 1.00 1.00 5
no 1.00 1.00 1.00 5
avg / total 1.00 1.00 1.00 10由于本人水平有限,欢迎读者反馈。
参考:
1. 薛良玉,付国庆,蔡俊,等․ 油井生产工况诊断及智能预警. 2018年中国石油石化企业信息技术论文集 156-161
2. 用Python开始机器学习(2:决策树分类算法) CSDN博客 lsldd的专栏 2014年11月
3. Python科学计算初探——余弦相似度 CSDN博客 肖永威 2018年4月