聚类
在说K-means聚类算法之前必须要先理解聚类和分类的区别。
分类其实是从特定的数据中挖掘模式,作出判断的过程。比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选“垃圾”或“不是垃圾”,过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了。这是因为在点选的过程中,其实是给每一条邮件打了一个“标签”,这个标签只有两个值,要么是“垃圾”,要么“不是垃圾”,Gmail就会不断研究哪些特点的邮件是垃圾,哪些特点的不是垃圾,形成一些判别的模式,这样当一封信的邮件到来,就可以自动把邮件分到“垃圾”和“不是垃圾”这两个我们人工设定的分类的其中一个。
聚类的的目的也是把数据分类,但是事先是不知道如何去分的,完全是算法自己来判断各条数据之间的相似性,相似的就放在一起。在聚类的结论出来之前,我完全不知道每一类有什么特点,一定要根据聚类的结果通过人的经验来分析,看看聚成的这一类大概有什么特点。
1、概述
K-means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的K类别,采用距离作为相似性的评级指标,即认为两个对象的距离越近,其相似度越大。
2、核心思想
通过迭代寻找k个类簇的一种划分方案,使得用这k个类簇的均值来代表相应各类样本时所得的总体误差最小。
k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。k-means算法的基础是最小误差平方和准则,其代价函数是:
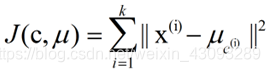
式中,μc(i)表示第i个聚类的均值。
各类簇内的样本越相似,其与该类均值间的误差平方越小,对所有类所得到的误差平方求和,即可验证分为k类时,各聚类是否是最优的。
上式的代价函数无法用解析的方法最小化,只能有迭代的方法。
3、算法过程
1、从N个样本数据中随机选取K个对象作为初始的聚类质心。
2、分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
3、所有对象分配完成之后,重新计算K个聚类的质心。
4、与前一次的K个聚类中心比较,如果发生变化,重复过程2,否则转过程5.
5、当质心不再发生变化时,停止聚类过程,并输出聚类结果。
【情景问题的模型建立】
根据航空公司目前积累的大量客户会员信息和其乘坐的航班记录,可以得到包括姓名、乘坐次数、价格等十几条属性信息。
本情景案例是想要获取客户价值,识别客户价值应用的最广泛的模型是RFM模型,三个字母分别代表recency(最近消费时间间隔)、frequency(消费频率)、消费金额(monetary)这三个指标。结合具体情景,最终选取客户关系长度L、消费时间间隔R、消费频率F、飞行里程M、折扣系数的平均值C这5个指标作为航空公司识别客户价值的指标,记为LRFMC模型。
所以本案例通过对LRFMC模型的五个指标进行K-means聚类分析来识别出最优价值的客户。
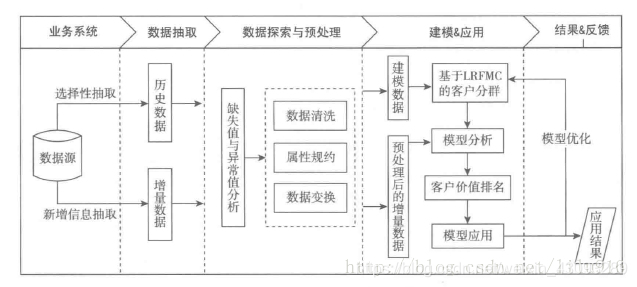
主要步骤
如上图所示,主要包括:
1、对数据集进行数据探索分析与预处理,包括数据缺失与异常处理、数据属性的规约、清洗和变换。
2、利用步骤1中完成预处理的数据,基于LRFMC模型进行客户分群,对各个客户群进行特征分析,识别出有价值的客户。
3、针对不同价值的客户进行不同的营销手段,个性化服务。
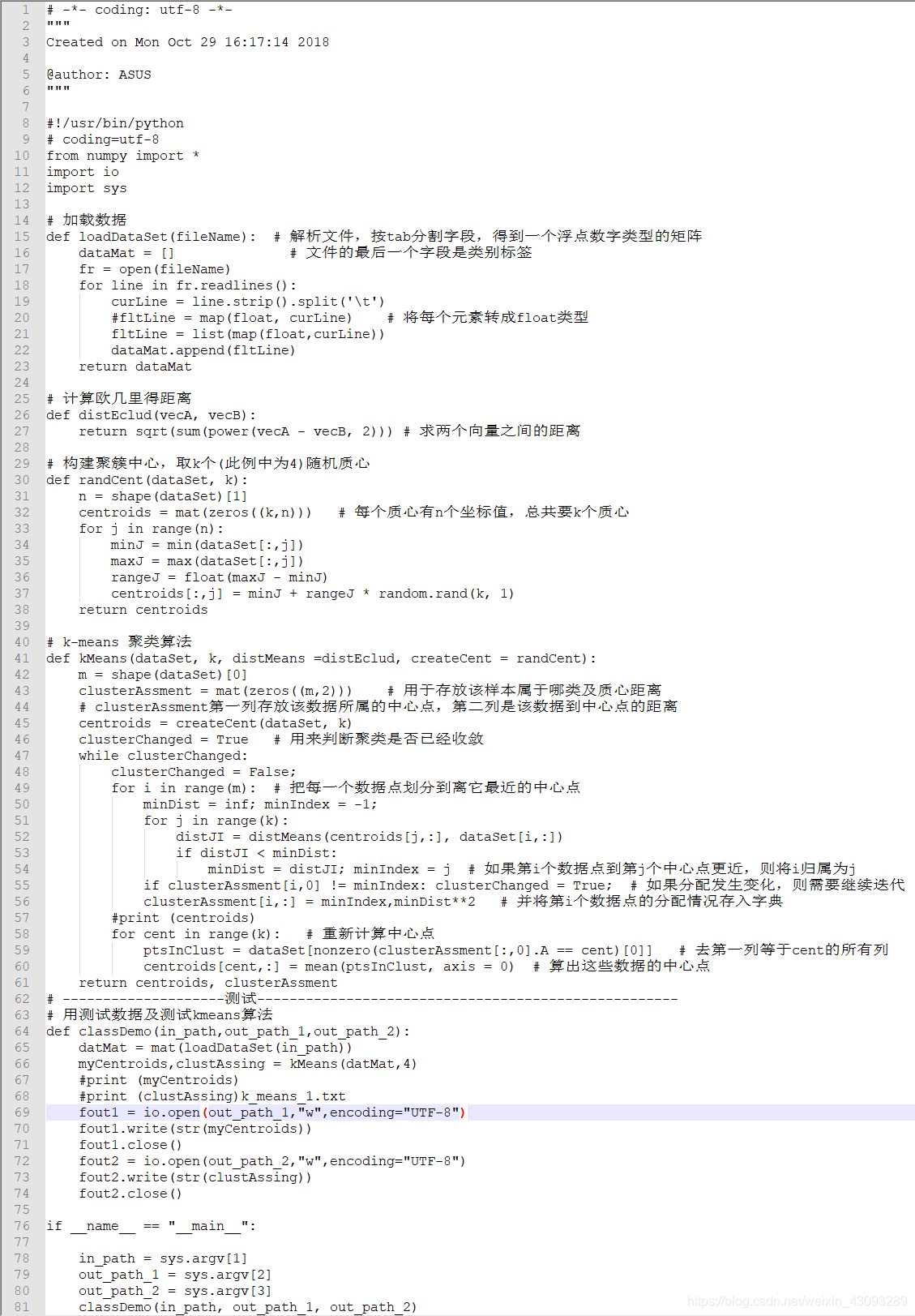
python实例
在代码中需要传入的数据(in_path)传出的数据打印到文件中(out_path_1和out_path_2)