一、聚类
聚类算法是一种无监督学习算法;所谓的无监督学习是指:训练样本的标记信息是未知的(不提供),目标是通过对未标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
聚类问题:给定一堆数据,尝试将数据样本进行分组,使得组内的样本之间相似度高于组间的样本。
相似度的度量:欧几里得距离,曼哈顿距离等等。
聚类的主要类型包括:互斥的vs重叠的,确定性的vs概率性的,层次聚类等。
二、K-means算法
1、输入:假设存在一个包含m个训练样本的训练数据集,{x1,……,xm},其中xi表示第i个训练样本。每个训练样本都是一个n维向量。此外,假设聚类数K已知。
2、目标:产出一个确定性的互斥聚类结果,使得簇内的差异尽可能的小,同时簇间的差异尽可能的大。
3、最小化代价函数:

1) μk是第K个簇的簇中心;
2) rik=1 ,表示当第i个样本被划分进了第k个簇,否则为0;
3) 限制条件:

4、迭代算法:

三、K-means算法实现
本次算法实现,采用了两种方法:1、自编程实现Kmeans算法;2、采用scikit-learn模块实现。
具体事例:对鸢尾花数据集(iris dataset)做 k-means 聚类,仅使用后两个特征进行聚类(即petal.length和petal.width)。
1、K=3时的自编程实现
def distance_calc(A,B): #定义计算坐标点距离(平方)的函数
import math
if (A.size != 2)and(B.size != 2):
print("please input 2*1 array!")
return
return (A[0]-B[0])**2 + (A[1]-B[1])**2
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:4]
plt.scatter(X[:,0],X[:,1],s=10,c='green',marker='o') #对数据集进行显示,以便于进行初步筛选
c0 = np.random.normal(2,0.5,2) #随机定义簇中心坐标
c1 = np.random.normal(2,0.5,2) #设定K值为3
c2 = np.random.normal(2,0.5,2) #设定K值为3
plt.scatter(c0[0],c0[1],s=55,c='red',marker='x',label='center0') #对随机定义的簇中心进行显示
plt.scatter(c1[0],c1[1],s=55,c='blue',marker='x',label='center1') #对随机定义的簇中心进行显示
plt.scatter(c2[0],c2[1],s=55,c='black',marker='x',label='center2') #对随机定义的簇中心进行显示
plt.legend(loc=2)
plt.title("The Original State") #定义标题以便于进行区分
plt.show()
label=[0 for index,elem in enumerate(X)] #对分类进行标记,元素只能取0/1/2
num = 0 #标记迭代次数
while(1):
J = 0 #清零代价函数
size0 = 0 #清零类型0中样本的个数
size1 = 0 #清零类型1中样本的个数
size2 = 0 #清零类型2中样本的个数
cc0 = np.array([0.,0.]) #清零类型0中样本的坐标和
cc1 = np.array([0.,0.]) #清零类型1中样本的坐标和
cc2 = np.array([0.,0.]) #清零类型2中样本的坐标和
for index,elem in enumerate(X): #遍历数据集,根据距离对样本进行分类
d0 = distance_calc(elem,c0) #计算样本到簇0中心的距离(平方)
d1 = distance_calc(elem,c1) #计算样本到簇1中心的距离(平方)
d2 = distance_calc(elem,c2) #计算样本到簇2中心的距离(平方)
if (d0<=d1) and (d0<=d2): #到簇0中心的距离近时
label[index] = 0
size0 += 1
cc0 += elem
elif (d1<=d0) and (d1<=d2): #到簇1中心的距离近时
label[index] = 1
size1 += 1
cc1 += elem
elif (d2<=d0) and (d2<=d1): #到簇2中心的距离近时
label[index] = 2
size2 += 1
cc2 += elem
if size0 == 0: #重新计算簇0中心坐标
cc0 = np.random.normal(2,1,2) #防止分母为零
else:
cc0 = cc0/size0
if size1 == 0: #重新计算簇1中心坐标
cc1 = np.random.normal(2,1,2) #防止分母为零
else:
cc1 = cc1/size1
if size2 == 0: #重新计算簇2中心坐标
cc2 = np.random.normal(2,1,2) #防止分母为零
else:
cc2 = cc2/size2
delta0 = distance_calc(cc0,c0) #计算前后两次簇0中心坐标的距离(平方)
delta1 = distance_calc(cc1,c1) #计算前后两次簇1中心坐标的距离
delta2 = distance_calc(cc2,c2) #计算前后两次簇2中心坐标的距离
c0 = cc0 #更新簇0中心坐标
c1 = cc1 #更新簇1中心坐标
c2 = cc2 #更新簇2中心坐标
num += 1
for index,type in enumerate(label): #对不同类型的样本分别进行显示
if type == 0:
plt.scatter(X[index,0],X[index,1],s=10,c='red',marker='o')
J += distance_calc(X[index,:],c0)
elif type == 1:
plt.scatter(X[index,0],X[index,1],s=10,c='blue',marker='o')
J += distance_calc(X[index,:],c1)
elif type == 2:
plt.scatter(X[index,0],X[index,1],s=10,c='black',marker='o')
J += distance_calc(X[index,:],c2)
plt.scatter(c0[0],c0[1],s=55,c='red',marker='x',label='center0') #对簇0中心坐标进行显示
plt.scatter(c1[0],c1[1],s=55,c='blue',marker='x',label='center1') #对簇1中心坐标进行显示
plt.scatter(c2[0],c2[1],s=55,c='black',marker='x',label='center2') #对簇2中心坐标进行显示
plt.legend(loc=2)
plt.title('The State of The %d Iteration'%num) #定义标题以便于进行区分
plt.show()
if (delta0<0.001) and (delta1<0.001) and (delta2<0.001): #根据前后两次簇中心移动的距离判断是否跳出死循环
break
print('簇0中心坐标为:',c0) #打印显示K-means后的簇0中心坐标
print('簇1中心坐标为:',c1) #打印显示K-means后的簇1中心坐标
print('簇2中心坐标为:',c2) #打印显示K-means后的簇1中心坐标
print('K=3时的最小代价为:',J) #打印显示K=3时代价函数的最小值
print(size0,size1,size2)
2、K=3时的scikit-learn实现
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data[:,2:4]
# print(X)
kmeans = KMeans(n_clusters=3,random_state=0).fit_predict(X)
color = ('red','blue','black')
colors = np.array(color)[kmeans]
plt.scatter(X[:,0],X[:,1],c=colors)
plt.show()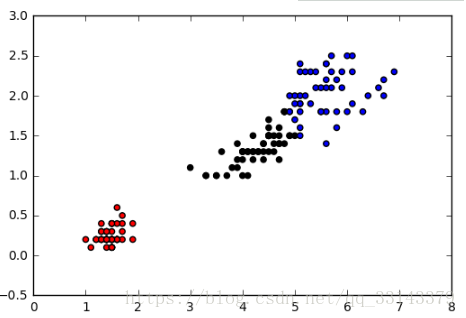
比较上述两个图片的结果,可以发现两种方法的结果基本一致,不同点在于边界处的分类,这是由于自编程时跳出死循环的条件不同导致的,通过调整条件可使得结果完全一样。
3、K=2时的自编程实现
def distance_calc(A,B): #定义计算坐标点距离(平方)的函数
import math
if (A.size != 2)and(B.size != 2):
print("please input 2*1 array!")
return
return (A[0]-B[0])**2 + (A[1]-B[1])**2
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:,2:4]
plt.scatter(X[:,0],X[:,1],s=10,c='green',marker='o') #对数据集进行显示,以便于进行初步筛选
c0 = np.random.normal(2,0.5,2) #随机定义簇中心坐标
c1 = np.random.normal(2,0.5,2) #设定K值为2
plt.scatter(c0[0],c0[1],s=55,c='red',marker='x',label='center0') #对随机定义的簇中心进行显示
plt.scatter(c1[0],c1[1],s=55,c='blue',marker='x',label='center1') #对随机定义的簇中心进行显示
plt.legend(loc=2)
plt.title("The Original State") #定义标题以便于进行区分
plt.show()
label=[0 for index,elem in enumerate(X)] #对分类进行标记,元素只能取0或1
num = 0 #标记迭代次数
while(1):
J = 0 #清零代价函数
size0 = 0 #清零类型0中样本的个数
size1 = 0 #清零类型1中样本的个数
cc0 = np.array([0.,0.]) #清零类型0中样本的坐标和
cc1 = np.array([0.,0.]) #清零类型1中样本的坐标和
for index,elem in enumerate(X): #遍历数据集,根据距离对样本进行分类
d0 = distance_calc(elem,c0) #计算样本到簇0中心的距离(平方)
d1 = distance_calc(elem,c1) #计算样本到簇1中心的距离(平方)
if d0 <= d1: #到簇0中心的距离近时
label[index] = 0
size0 += 1
cc0 += elem
else: #到簇1中心的距离近时
label[index] = 1
size1 += 1
cc1 += elem
if size0 == 0: #重新计算簇0中心坐标
cc0 = np.random.normal(2,1,2) #防止分母为零
else:
cc0 = cc0/size0
if size1 == 0: #重新计算簇1中心坐标
cc1 = c0 = np.random.normal(2,1,2) #防止分母为零
else:
cc1 = cc1/size1
delta0 = distance_calc(cc0,c0) #计算前后两次簇0中心坐标的距离
delta1 = distance_calc(cc1,c1) #计算前后两次簇1中心坐标的距离
c0 = cc0 #更新簇0中心坐标
c1 = cc1 #更新簇1中心坐标
num += 1
for index,type in enumerate(label): #对不同类型的样本分别进行显示
if type == 0:
plt.scatter(X[index,0],X[index,1],s=10,c='red',marker='o')
J += distance_calc(X[index,:],c0)
else:
plt.scatter(X[index,0],X[index,1],s=10,c='blue',marker='o')
J += distance_calc(X[index,:],c1)
plt.scatter(c0[0],c0[1],s=55,c='red',marker='x',label='center0') #对簇0中心坐标进行显示
plt.scatter(c1[0],c1[1],s=55,c='blue',marker='x',label='center1') #对簇1中心坐标进行显示
plt.legend(loc=2)
plt.title('The State of The %d Iteration'%num) #定义标题以便于进行区分
plt.show()
if (delta0<0.001) and (delta1<0.001): #根据前后两次簇中心移动的距离判断是否跳出死循环
break
print('簇0中心坐标为:',c0) #打印显示K-means后的簇0中心坐标
print('簇1中心坐标为:',c1) #打印显示K-means后的簇1中心坐标
print('K=2时的最小代价为:',J) #打印显示K=2时代价函数的最小值
print(size0,size1)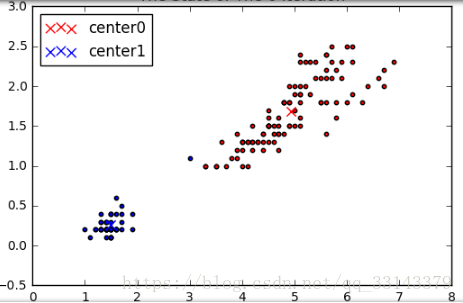
4、K=2时的scitkit-learn实现
import numpy as np
from sklearn import datasets
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data[:,2:4]
kmeans = KMeans(n_clusters=2,random_state=0).fit_predict(X)
color = ("red","blue")
colors = np.array(color)[kmeans]
plt.scatter(X[:,0],X[:,1],c=colors)
plt.show()
比较上述两个图片的结果,可以发现两种方法的结果基本一致,不同点在于边界处的分类,这是由于自编程时跳出死循环的条件不同导致的,通过调整条件可使得结果完全一样。