目录
1.算法原理介绍
#k-means聚类方法
"""
k-means聚类算法流程:
1.K-mean均值聚类的方法就是先随机选择k个对象作为初始聚类中心.
2.这个时候你去计算剩余的对象于哪一个聚类中心的距离是最小的,优先分配给最近的聚类中心.
3.分配后,原先的聚类中心和分配给它们的对象就又会被看作一个新聚类.
4.每次进行分配之后,聚类中心又会被重新计算一次
5.直到满足某些终止条件为止:1.没有聚类中心被分配 2.达到了局部的聚类均方误差最小
"""
K-means聚类方法优缺点
优点:
1.原理简单上手比较快
2.算法的可解释度强
3.主要参数只有k
4.收敛速度快
缺点:
1.不适用非线性数据集
2.特征尺度比较敏感
3.无法处理噪声值或者异常值2.算法核心代码
KMeans函数中需要我们做到如下的操作:
KMeans本质上是一个迭代的算法
1.分配数据点到中心
2.更新质心
3.如何质心不再变化,就停止更新,退出迭代
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from matplotlib.colors import ListedColormap
def plot_decision_region(X,y,classifier,resolution=0.02):
colors= ('lightgreen','yellow','blue','pink','red','grey','lightyellow')
colors1= ('blue','red','yellow','pink','lightgreen')
# 背景色
cmap = ListedColormap(colors[0:7])
# plot the decision surface
#这里+1 -1的操作我理解为防止样本落在图的边缘处,不知道对不对
x1_min,x1_max = X[:,0].min()-1,X[:,0].max()+1
#print(x1_min, x1_max)
x2_min,x2_max = X[:,1].min()-1,X[:,1].max()+1
#print(x2_min, x2_max)
# 生成网格点坐标矩阵
xx1,xx2 = np.meshgrid(np.arange(x1_min,x1_max,resolution),
np.arange(x2_min,x2_max,resolution))
Z = classifier.predict(np.array([xx1.ravel(),xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
# 绘制轮廓等高线 alpha参数为透明度
plt.contourf(xx1,xx2,Z,alpha=0.3,cmap=cmap)
plt.xlim(xx1.min(),xx1.max())
plt.ylim(xx2.min(),xx2.max())
for idx,cl in enumerate(np.unique(y)):
plt.scatter(x=X[y==cl,0],
y = X[y==cl,1],
alpha=0.8,
c=colors1[idx],
label=cl,
edgecolors='black',
s=9)
# 从Excel读取数据
data = pd.read_excel('Clustering_5.xlsx')
# 提取特征和标签
X = data.iloc[:, :2].values
X1 = data.iloc[:, 0].values
X2 = data.iloc[:, 1].values
y = data['y'].values
#设置k-means方法参数
k = 5
# kmeans 聚类
kmeans = KMeans(n_clusters = k,random_state=42)
y_pred = kmeans.fit_predict(X)
#
plt.figure(figsize=(8,10))
plt.subplot(2,1,1)
plt.scatter(X1,X2,s=4)
plt.title("图像散点分布图")
plt.xlabel("X1")
plt.ylabel("X2")
plt.subplot(2,1,2)
plt.title("2")
plt.title("K-means图像散点决策图")
x=[i[0] for i in X]
y=[i[1] for i in X]
plot_decision_region(X,y_pred,classifier=kmeans,resolution=0.02)
plt.savefig(r"C:\Users\Zeng Zhong Yan\Desktop\py.vs\MachineLearning\K-means.png",dpi=500)
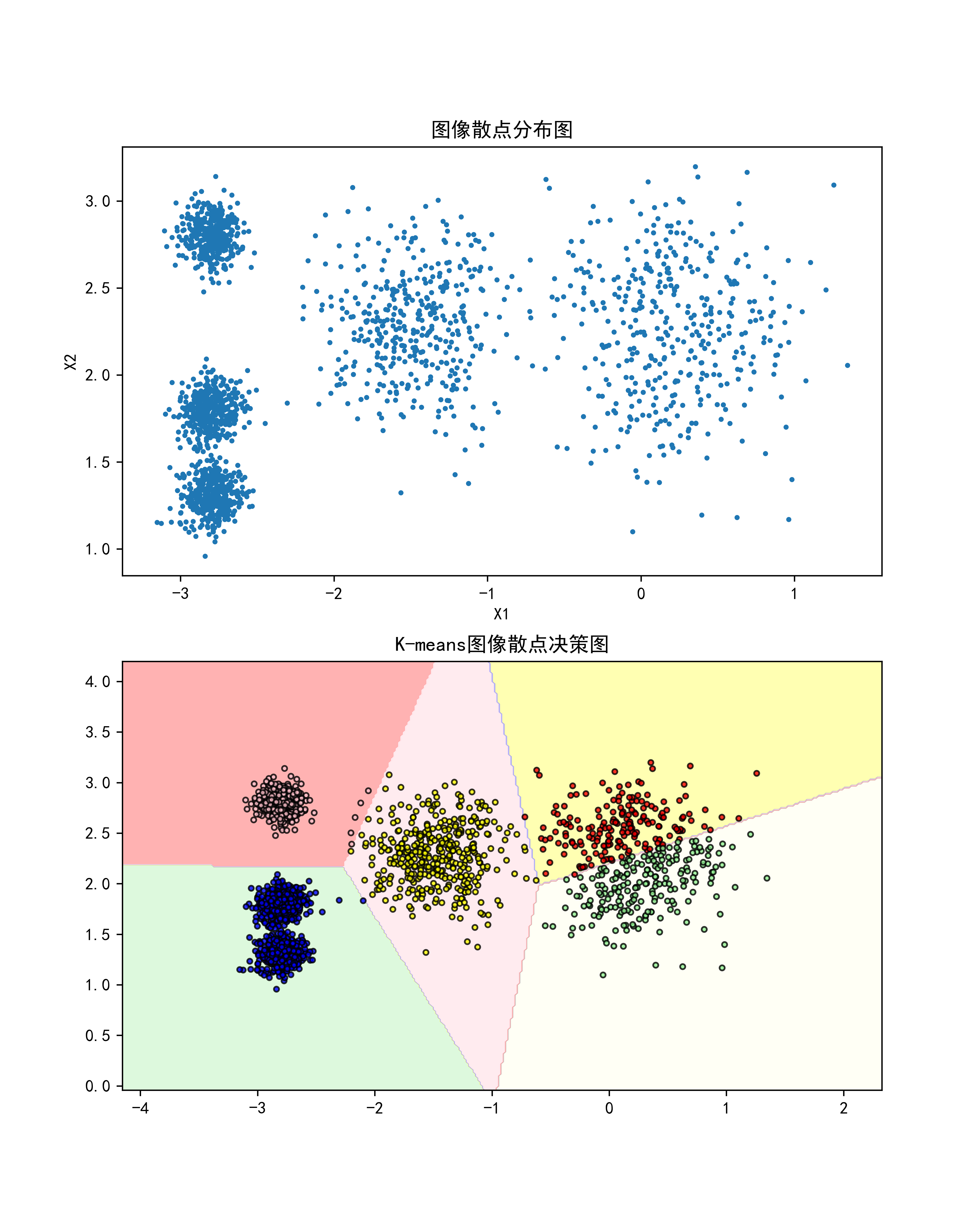
plt.show()3.算法效果展示
图片分为两部分:
1.图像散点分布图,以x1,x2为轴绘制而成.
2.K-means图像散点决策图,核心函数的写法请参考如下文章:
决策面绘制:https://blog.csdn.net/RPG_Zero/article/details/107629361