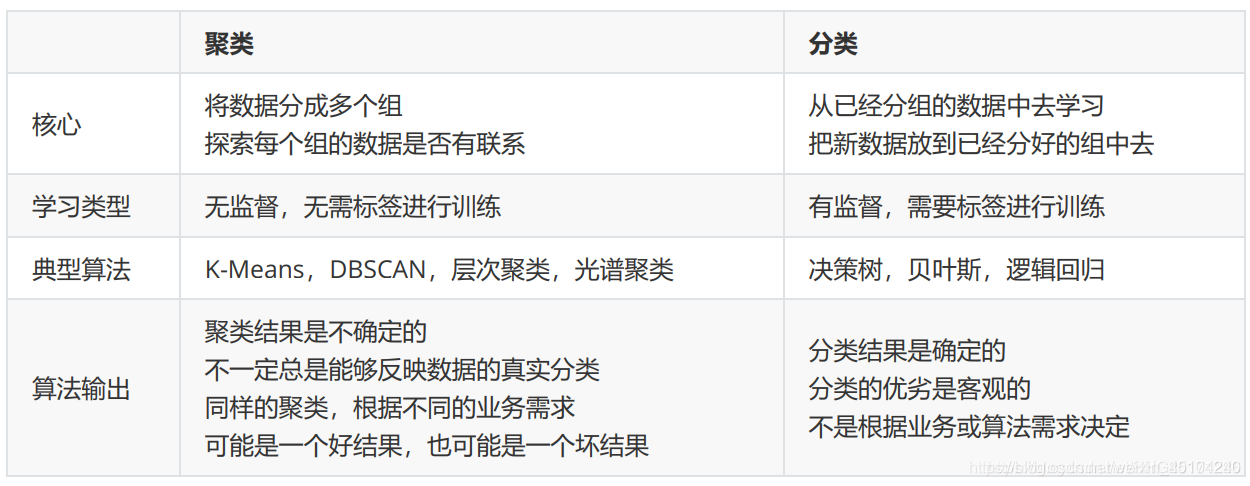
1.无监督学习与聚类算法
对于决策树,随机森林,PCA和逻辑回归等算法中,他们虽然有着不同的功能,但却都属于“有监督学习”的一部分,也就是说,模型在训练的时候,即需要特征矩阵X,也需要真实标签y。
机器学习当中,还有相当一部分算法属于“无监督学习”,无监督的算法在训练的时候只需要特征矩阵X,不需要标签。而聚类算法,就是无监督学习的代表算法。
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动。
2.KMeans是如何工作的
我们通过下图来了解具体什么是聚类算法K-Means。

看了这张图,是不是觉得很简单?
作为聚类算法的典型代表,KMeans可以说是最简单的聚类算法没有之一,那它具体是怎么完成聚类的呢?
3.关键概念:簇和质心
KMeans算法将一组N个样本的特征矩阵X划分为K个无交集的簇,直观上来看是簇是一组一组聚集在一起的数
据,在一个簇中的数据就认为是同一类。簇就是聚类的结果表现。
簇中所有数据的均值通常被称为这个簇的“质心”(centroids)。在一个二维平面中,一簇数据点的质心的横坐标就是这一簇数据点的横坐标的均值,质心的纵坐标就是这一簇数据点的纵坐标的均值。同理可推广至高维空间。
在KMeans算法中,簇的个数K是一个超参数,需要我们人为输入来确定。KMeans的核心任务就是根据我们设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如
下:

4.我们进行一次聚类看看吧
当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这 个数据集的数据分布,以此来为我们聚类时输入的n_ clusters做一 个参考。
首先,我们来自己创建一个数据集。 这样的数据集是我们自己创建,所以是有标签的。
4.1 创建数据
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=1500,n_features=8,centers=4,random_state=4) #这里预置4个簇
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1],marker='o',s=8)
plt.show()
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y==i, 0], X[y==i,1] ,marker='o',s=8,c=color[i]) #为每个簇提前做颜色的标记(机器不知道)
plt.show()

4.1 进行分类
from sklearn.cluster import KMeans
n_clusters = 4
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
y_pred = cluster.labels_
y_pred
Out: array([1, 2, 3, …, 1, 0, 2])
pre = cluster.fit_predict(X)
pre
Out: array([1, 2, 3, …, 1, 0, 2])
pre == y_pred
Out: array([ True, True, True, …, True, True, True])
#重要属性cluster_centers_,查看质心
centroid = cluster.cluster_centers_
centroid
Out:
centroid.shape
Out: (4, 8)
#重要属性inertia_,查看总距离平方和
inertia = cluster.inertia_
inertia
Out: 11943.363388393387
color = ["red","pink","orange","gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred==i, 0], X[y_pred==i,1] ,marker='o',s=8,c=color[i])
ax1.scatter(centroid[:,0],centroid[:,1],marker='x',s=20,c='black')
plt.show()
分类结果:

看到这里,是不是觉得机器学习十大算法之一—聚类算法K-Means不太难?不过,学习聚类算法K-Means还有很长路要走,这里我只是用简单的例子和代码来引领大家走进机器学习的大门,也是我做这一期博客的初衷,也希望大家多多支持和鼓励,点个赞,加个关注,我会持续更新机器学习十大算法。
机器学习-十大算法系列欢迎访问我的主页,我会持续更新,谢谢。