学习笔记摘自TensorFlow中文社区http://www.tensorfly.cn/
本次学习字符的向量表示
字符的向量表示
学习目录
- 为何需要使用向量表示文字
- 通过直观地例子观察模型背后的本质,以及它是如何训练的(通过一些数学方法评估)。
- 展示了TensorFlow对该模型的简单实现
- 使这个简单的模型变得更好
1、为什么需要使用向量来表示文字
通常图像或音频系统处理的是由图片中所有单个原始像素点强度值或者音频中功率谱密度的强度值,把它们编码成丰富、高纬度的向量数据集。对于物体或语音识别这一类的任务,我们所需的全部信息已经都存储在原始数据中(显然人类本身就是依赖原始数据进行日常的物体或语音识别的)。然后,自然语言处理系统通常将词汇作为离散的单一符号,例如“cat”一词或可表示为Id537,而“dog”一词可以表示为Id143。这些符号编码毫无规律,无法提供不同词汇之间可能存在的关联信息。换句话说,在处理关于“dogs”一词的信息时,模型将无法利用已知的关于“cats”信息(例如,它们都是动物,有四条腿,可作为宠物等等)。可见,将词汇表达为上述的独立离散符号将进一步导致数据稀疏,使我们在训练统计模型时不得不寻求更多的数据。而词汇的向量表示将克服上述的难题。
向量空间模型(VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。向量空间模型在自然语言处理领域中有着漫长且丰富的历史,不过几乎所有利用这一模型的方法都依赖于分布式假设,其核心思想为出现于上下文情景中的词汇都有相类似的语义。采用这一假设的研究方法大致分为两类:基于技术的方法(潜在语义分析https://en.wikipedia.org/wiki/Latent_semantic_analysis)和预测方法(神经概率化语言模型http://www.scholarpedia.org/article/Neural_net_language_models)。这些东西在后续的学习中会讲到。
简而言之:基于计数的方法计算词汇与其邻近词汇在一个大型语料库中共同出现的频率及其他统计量。然后将这些统计量映射到一个小型且稠密的向量中。预测方法则试图直接从某词汇对其进行预测,在此过程中利用已经学习到的小型且稠密的嵌套向量。
Word2vec是一种可以进行高效率词嵌套学习的预测模型。其两种变体分别为:连续词袋模型(CBOW)及Skip_Gram模型。从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇(‘the cat sits on the’)来预测目标词汇(例如,‘mat’),而Skip_Gram模型做法相反,它通过目标词汇来预测源词汇。Skip_Gram模型采取CBOM的逆过程的动机在于:CBOW算法对于很多分布式信息进行了平滑处理(例如将一整段上下文信息视为一个单一观察量)。很多情况下,对于小型的数据集,这一处理是有帮助的。相形之下,Skip-Gram模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。下面着重讲解Skip-Gram模型。
处理噪声对比训练
神经概率化语言模型通常使用极大似然法(ML)进行训练,其中通过softmax function 来最大化当提供一个单词“h”(代表“history”),后一个单词的概率Wt(代表“target”),
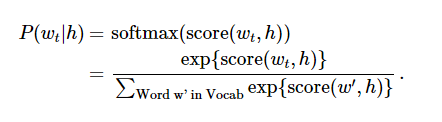
当score(w_t,h)计算了文字w_t和上下文h的相容性(通常使用向量积)。我们使用对数似然函数来训练训练集的最大值。
这里提出了一个解决语言概率模型的合适的通用方法。然而这个方法实际执行起来开销非常大,因为我们需要去计算并正则化当前上下文环境h中所有其他V单词w‘的概率得分,在每一步训练迭代中。

从另一个角度来说,当使用word2vec模型时,我们并不需要对概率模型中的所有特征进行学习。而CBOW模型和Skip-Gram模型为了避免这种情况发生,使用一个二分类器(逻辑回归)在同一个上下文环境里从k虚构的(噪声)单词w区分出真正的目标单词Wt。我们下面详细阐述一下CBOW模型,对于Skip-Gram模型只要简单地做相反的操作即可。

说实在的。我有点看不懂了,
未完