概述
这两天写了两篇自学tensorflow2.0的教程,其实tensorflow2.0集成了keras的功能,所以相对来说很简单。正好看到一些pytorch的资料,也稍微整理整理相关的数据加载工作,大多是异曲同工。如果是学生,还是建议tf2跟pytorch都要学习,学术界中pytorch已经逐渐占据上风,工业界tf还是独占鳌头,毕竟涉及到各种部署,tf有很大的优势。
tensorflow2.0数据加载
这里我先展示一下Tensorflow2.0是怎么加载数据的。
首先导入必要的包:
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
import pathlib
import seaborn as sns
#导入tf
import tensorflow as tf
from tensorflow import keras
加载数据集,输入网址会去下载到特定位置(这是一个汽车燃油效率的数据集):
# 加载数据集
dataset_path = keras.utils.get_file('auto-mpg.data', "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path
这里我们使用pandas去读取数据集,然后给每个字段都确定名字。用dataset变量复制一个原始数据的变量。
column_names = ['MPG' ,'Cylinders','Displacement', 'Horsepower', 'Weight', 'Acceleration','Model Year','Origin']
raw_dataset = pd.read_csv(dataset_path, names=column_names,na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
我们看一下数据:
 这样我们就可以读到我们的数据了,这是一个结构化的数据,用来做回归问题。这里我们多说两句,在tf2.0中一些预处理的相关工作。
这样我们就可以读到我们的数据了,这是一个结构化的数据,用来做回归问题。这里我们多说两句,在tf2.0中一些预处理的相关工作。
dataset.isna().sum()
找到无效值,看看无效值情况:
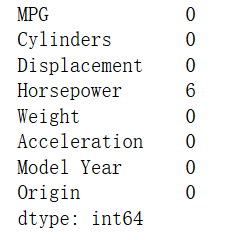
丢掉无效值并查看数据:
dataset = dataset.dropna()
dataset.isna().sum()
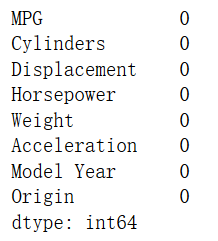
将标签转换成one-hot编码:
origin = dataset.pop('Origin')
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()
那么数据就处理结束啦(后面还需要做归一化,构建训练集测试集之类的工作):

Pytorch数据加载
不打算写使用自带数据集了,直接写加载自定义的数据集,我相信多数人也都是使用的自己找的一些数据集。
我们需要知道一个类,这个类是用于加载数据集的。
import torch.utils.data as Data
class MyDataset(Data.Dataset):
def __init__(self):
# 读取文件之类的
pass
def __getitem__(self, index):
# 获取一个数据
# 再次可以写预处理
# 返回一个数据对(x,y)
pass
def __len__(self):
# 返回数据集的大小
pass
其中Mydataset需要继承自带的Data.Dataset这个类,这里面的__init__(),getiten(),len()都是必须的。假设我们构建这样一个小demo数据集:
import torch.utils.data as Data
person_1 = ['高','富','帅','有']
person_2 = ['不高','富','帅','有']
person_3 = ['不高','不富','帅','有']
person_4 = ['不高','不富','不帅','无']
person = [person_1, person_2, person_3, person_4]
我们要把这个数据集写到上面所说的这样一个类中:
class SingleDog(Data.Dataset):
def __init__(self, person):
self.data = person
def __getitem__(self, index):
item = self.data[index]
x = item[:3]
y = item[-1]
return x, y
def __len__(self):
return len(self.data)
我们构建了一个SingleDog这个类,传入torch提供的加载数据的类。属性中是person这个变量(也就是一个个样本)。然后使用__getitem__()函数构建索引。x作为输入(也就是特征),y作为标签。__len__传入的是数据长度,这个长度是跟batchsize有关的。
single = SingleDog(person)
for index, (x, y) in enumerate(single):
print(f"迭代次数: {index}, x :{x}, y:{y}")
我们使用single来实例化这个类,传入数据person,然后我们可以看一下输入特征和标签。
 这样数据集就构建好了,然后我们来加载数据集。
这样数据集就构建好了,然后我们来加载数据集。
single_loader = Data.DataLoader(dataset=single, batch_size=2) # 一批数据有2个样例
for index, data in enumerate(single_loader):
x, y = data
print(f"迭代次数: {index}, x :{x}, y:{y}")
结果:
 这样我们就已经完成了数据集的加载。但是对于自然语言处理中的文本数据而言,我们的神经网络模型是没有办法直接处理文字的。所以在进行自然语言处理任务时我们需要构建word2id,构建一个能被直接处理的数据类:
这样我们就已经完成了数据集的加载。但是对于自然语言处理中的文本数据而言,我们的神经网络模型是没有办法直接处理文字的。所以在进行自然语言处理任务时我们需要构建word2id,构建一个能被直接处理的数据类:
word2id = {
'高':1,
'富':1,
'帅':1,
'不高':0,
'不富':0,
'不帅':0,
'有':1,
'无':0
}
class TensorSingleDog(Data.Dataset):
def __init__(self, person):
self.data = person;
def __getitem__(self, index):
item = self.data[index]
new_item = []
for feature in item:
new_item.append(word2id[feature])
x = new_item[:3]
y = new_item[-1]
return x, y
def __len__(self):
return len(self.data)
single = TensorSingleDog(person)
single_loader = Data.DataLoader(dataset=single, batch_size=2)
for index, data in enumerate(single_loader):
x, y = data
print(f"迭代次数: {index}, x :{x}, y:{y}")
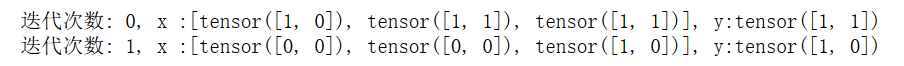 这样把数据变成tensor才能输入模型。这里,我也多说一点关于数据预处理的工作。
这样把数据变成tensor才能输入模型。这里,我也多说一点关于数据预处理的工作。
def my_collate_fn(batch_data):
x_batch = []
y_batch = []
for example in batch_data:
x, y = example
x_batch.append(x)
y_batch.append(y)
x_batch = torch.tensor(x_batch,dtype = torch.float32)
y_batch = torch.tensor(y_batch,dtype = torch.float32)
return x_batch, y_batch
single_loader = Data.DataLoader(dataset=single, batch_size=2, collate_fn=my_collate_fn)
for index, data in enumerate(single_loader):
x, y = data
print(x)
print(y)
重新构建的数据:

