1、RNN介绍:
RNN的基本想法是如何采用序列信息。在传统神经网络中我们假设所有的输入和输出都是相互独立的,但对于很多任务这样的假设并不合适。如果你想预测一个句子的下一个单词,的则需要知道之前的words包括哪些。
RNN被称为循环因为它们对句子的每个元素都执行相同的任务,输出依赖于之前的计算;另一个理解RNN的方法是假设他们用记忆能够获取之前计算过的信息。理论上RNN能够利用任意长的句子,但是实践中通常会回溯固定长度。
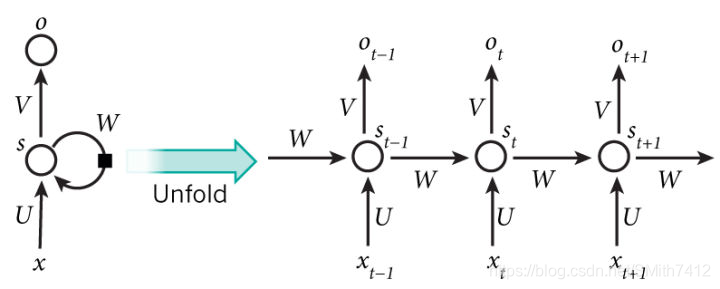
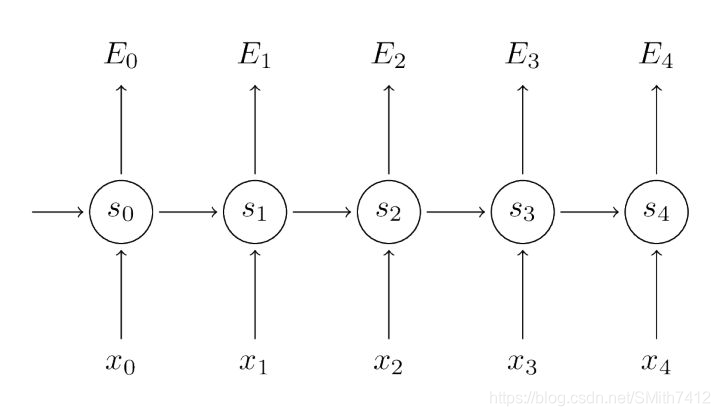
上图显示了一个RNN被展开(或展开)成一个完整的网络。 通过展开,我们指的是我们写出完整序列的网络。 例如,如果我们关心的序列是5个单词的句子,网络将被展开成5层神经网络,每个单词一层。 管理在RNN中发生的计算的公式如下:

需要说明的是
可以将隐藏状态 s_{t} 看作网络的memory,获取到了之前时刻中发生的信息,输出仅仅采用时刻t的memory来进行计算。正如之前所说,由于在实践中只能获取到一段时间内的信息,因此情况略复杂
传统的神经网络在每一层采用不同的参数,而RNN在所有步中采用共同的参数(U,V,W),这表示我们在每一步执行相同的任务,仅仅是输入不同而已。这样会缩减需要学习的参数数量
上图在每一步都输出,这并不是绝对必要的,需要针对不同任务进行设计。例如,在预测一个句子的情绪的时候,我们只关心最后的输出,而不是每个word之后的情绪值。相似的,我们并不需要在每个时刻都有输入。RNN的主要feature是隐藏状态,能够获取一个句子的信息
Different types of RNNs
我们来举例一些RNN的应用以及对应的sequence data。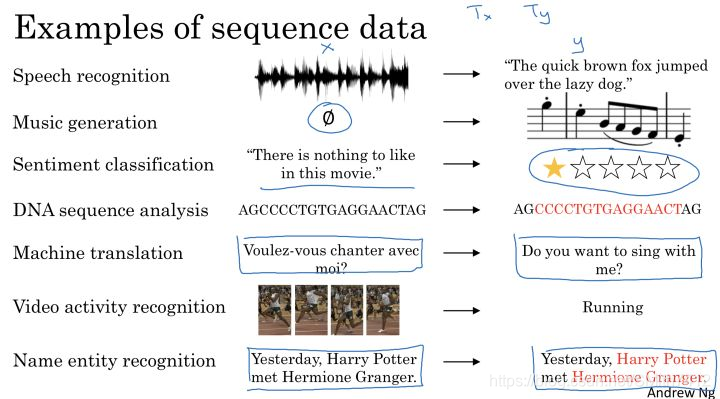
上图包括:
1、Speech recognition
2、Music generation
3、Sentiment Classification
4、DNA Sequence analysis
5、Machine Translation
6、Video activity recognition
7、Named Entity Recognition
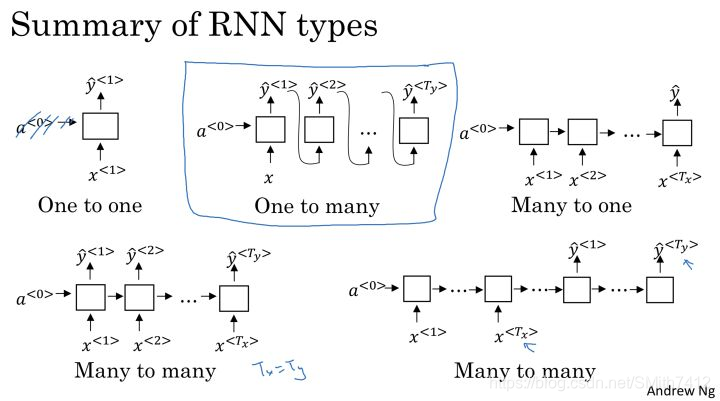
显然输入和输出可能是类似的序列,也可能是完全不同的内容,我们可以将其分为以下几种:
1、One to One 传统NN
2、One to Many 例如Music/Text Generation
3、Many to One 例如Sentiment Classification 情感分析
4、Many to Many 输入与输出序列大小相同 例如Named
5、Entity Recognition
6、Many to Many 输入与输出序列大小不同 例如Machine 7、Translation
Training RNNs
训练RNN与训练传统神经网络类似,采用反向传播算法,但是有一些不同。因为RNN的参数是由所有时间步共同使用的,因此每次输入的梯度不仅仅依赖于当前步的计算,并且依赖于之前的时间步的数据,例如需要计算 t=4 时刻的梯度,我们需要反向传播3步然后将所有的梯度累加。这称为Backpropation Through Time(BPTT),在RNN Part 3-Back Propagation Through Time and Vanishing Gradients(BPTT算法和梯度消失) 中我们对BPTT进行了详细介绍。这里需要知道的是由于vanishing/exploding gradient problem导致普通RNN采用BPTT很难学习到long-term dependencies。
例如下面的这句话:
The cat, which already ate ..., was full.
The cats, which already ate ..., were full.
这里的was/were的选择实际上是由之前的cat/cats来决定的,但是普通RNN中,cat这里距离后面句子太远,因此难以学到这个内容。
为了解决这个问题,存在其他类型的采用Gated机制的神经网络,例如GRU、LSTM等被提出来解决这个问题。
文章来自:https://zhuanlan.zhihu.com/p/31028421
2、RNN中的BPTT算法和梯度消失问题
前面我们介绍了循环神经网络的基本结构,通过了解了前馈神经网络的反向传播算法的推导,接下来,介绍一下:
1、RNN中的反向传播算法,并解释为什么跟传统的反向传播不同
2、梯度消失现象,导致了LSTM和GRU的发展。梯度消失问题最早由Sepp Hochreiter在1911年提出,并且由于深度学习的流行而重新受到了关注
1) BPTT算法
我们给出了RNN的基本方程:
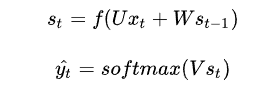
我们定义损失为cross entrophy loss(交叉熵损失),定义如下: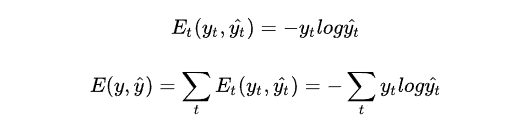
其中 \hat{y_{t}} 是时刻t的正确word,而 y_{t}是我们的预测结果,将整个句子作为训练样本,因此total error是每个时刻点t的error的累加。
我们的目标是先计算出error的梯度,然后采用梯度下降算法学习出好的参数。就跟我们将误差累加一样,我们也累加每个时刻点的梯度,例如
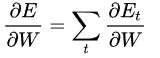
为了计算梯度我们采用chain rule of differentiation ,我们采用E3作为例子
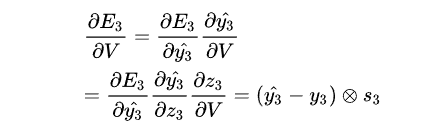

最后 们将每个时刻的梯度贡献都累加了起来,换句话说,因为W在每一步都影响到了输出,因此我们需要将梯度从时刻t=3通过网络反向传播到时刻t=0
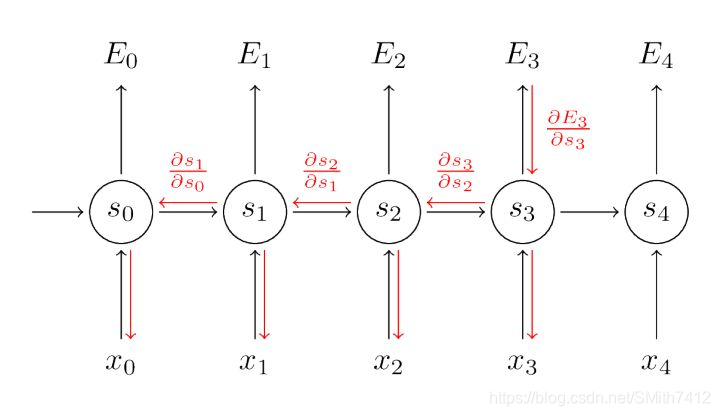
需要注意的是,这与我们在前馈神经网络中使用的标准反向传播算法完全相同,主要的差异在于我们将每时刻W的梯度相加,在传统的神经网络中,我们在层之间并不共享参数,因此不需要相加。BPTT只是标准反向传播在展开的循环神经网络上应用的一个名字而已。
当然,关于BPTT,大家也可参考这篇博文:https://www.cnblogs.com/wacc/p/5341670.html
2)The Vanishing Gradient Problem
在之前的Recurrent Neural Networks Part 2-Tensorflow实现RNN中我们提到了RNN难于学习到long-range dependencies between words that are several steps apart. 然而英文句子的意思通常是由距离不那么近的单词决定的。例如
“The man who wore a wig on his head went inside”.
这个句子是关于一个男人进去了,而不是关于wig的,但是一个plain RNN是很难获取到这样的信息的,为什么呢?我们来看一下我们之前计算出来的梯度:
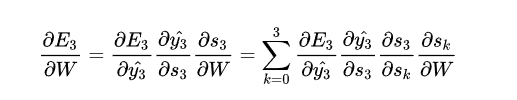
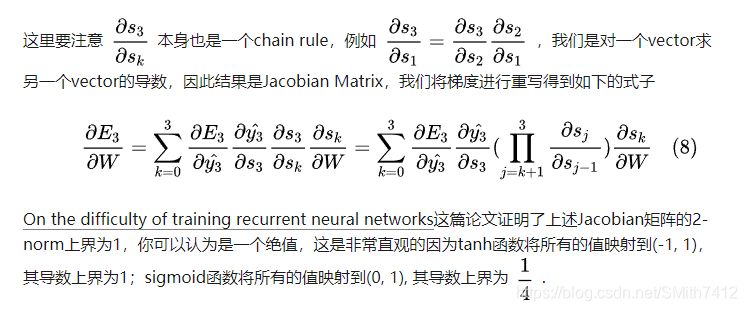
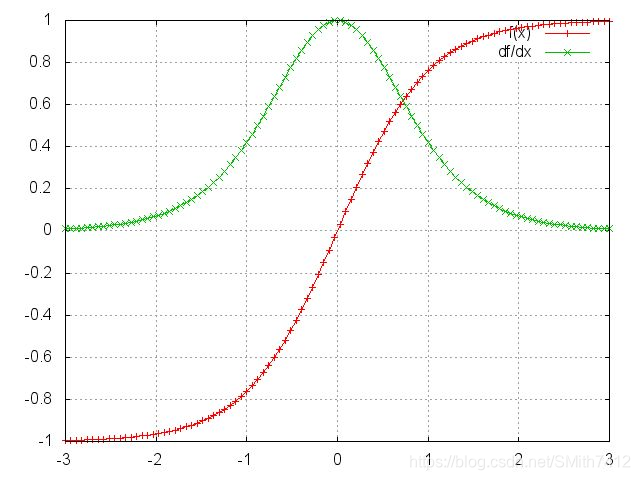
可以看到tanh和sigmoid函数在两端的导数接近0,它们接近一条平坦的直线,我们称神经元是饱和的,它们梯度为0并且回将前一层中的其他梯度驱动到0。因此在矩阵和多个矩阵乘法(t-k)的值比较小的情况下,梯度值快速地指数收缩,最终在几个时间步后完全消失。来自遥远步骤的梯度贡献会变为0,这些步骤的状态不会影响正在学习的内容:你最终无法学习到long-range dependencies, 梯度消失不是RNN独有的,在deep Feedforward Neural Network. 只不过RNN往往比较深,这使得梯度消失问题在RNN中比较显著。
因此,虽然简单循环网络从理论上可以建立长时间间隔的状态之间的依赖关系(Long-Term Dependencies),但是由于梯度爆炸或消失问题,实际上只能学习到短周期的依赖关系。这就是所谓的长期依赖问题。
很容易想象,基于我们的激活函数和网络参数,可能会产生梯度爆炸如果Jacobian matrix的值比较大的话,这称为exploding gradient problem.
Vanishing gradients比exploding gradient受到更多关注有两个原因:
exploding gradients是比较明显的,梯度会变成NaN并且代码会崩溃;
在预定义的阈值前对梯度进行修剪是一个简单而有效的解决梯度爆炸问题的方案
Vanishing gradients问题更复杂因为它的出现并不明显,而且不太清楚如何解决。
幸运的是有一些方法可以解决vanishing gradient problem。对于W矩阵适当的初始化可以减少vanishing gradient的效果,正则化也可以。
一个更佳的方法是采用ReLU替代tanh或者sigmoid函数,ReLU导数要么是0,要么是1,不会出现梯度消失问题。
另一个更佳流行的方法是采用Long Short-Term Memory(LSTM) 或者Gated Recurrent Unit(GRU) 架构。LSTM是1997年提出来的,并且是NLP中应用最广泛的模型。
GRUs是2014年提出来的,是LSTM的简化版本,两种RNN架构都用来处理梯度消失问题并且俄能够有效的学习long-range dependencies,我们将在后边部分介绍。
本小节内容来自:https://zhuanlan.zhihu.com/p/31842423
3、LSTM和GRU解决方案
短期记忆
RNN受到短期记忆的影响。如果序列很长,他们将很难将信息从较早的时间步传送到后面的时间步。因此,如果你尝试处理一段文本进行预测,RNN可能会遗漏开头的重要信息。
在反向传播期间,RNN存在梯度消失的问题(梯度用于更新神经网络权重的值)。梯消失度问题是当梯度反向传播随着时间的推梯度逐渐收缩。如果梯度值变得非常小,则不会产生太多的学习。
因此,在递归神经网络中,获得小梯度更新的层会停止学习。那些通常是较早的层。因为这些层不再学习,RNN会忘记它在较长序列中看到的内容,因此只有短期记忆。
LSTM和GRU解决方案:
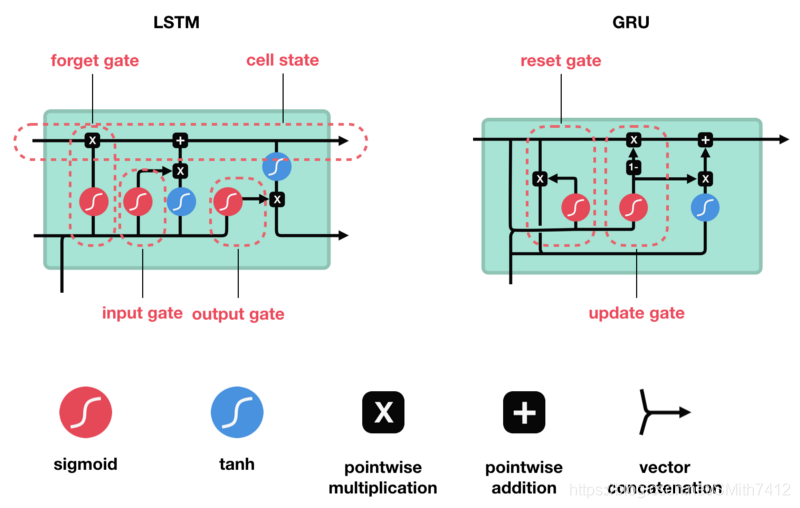
这些门可以了解序列中哪些数据重要以进行保留或丢弃。这样,它可以将相关信息传递到长序列中进行预测。现有的基于RNN的几乎所有技术结果都是通过LSTM和GRU这两个网络实现的。LSTM和GRU进行语音识别,语音合成和文本生成,甚至可以使用它们为视频生成字幕。
将通过直观的解释和插图来进行解释,尽量避免使用数学。
直觉
让我们从一个思想实验开始。假设你在网上查看评论来决定你是否要买Life麦片。你会首先阅读评论,确定某人认为麦片好不好
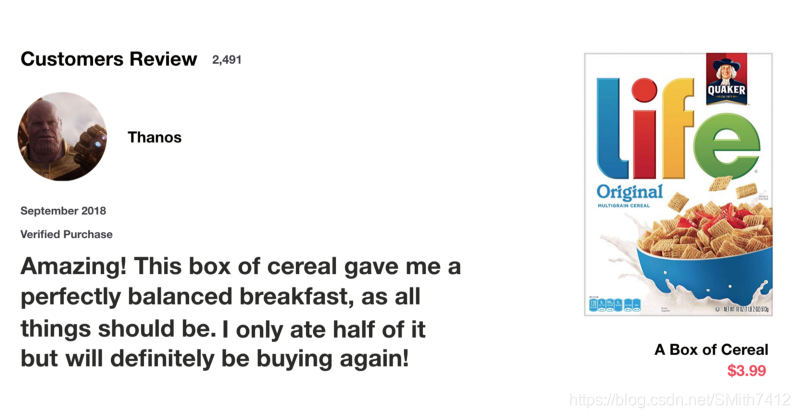
当你阅读评论时,你的大脑下意识地只会记住重要的关键词。你会选择“amazing”和“perfectly balanced breakfast”这样的词汇。你不太关心“this”,“give”,“all”,“should”等字样。如果朋友第二天问你评论说什么,你一般不会一字不漏地记住它。你可能还记得主要观点,比如“will definitely be buying again”。如果你是这样,那么其他的单词就会从记忆中逐渐消失。

这就是LSTM或GRU的作用。它可以学习只保留相关信息来进行预测,忘记不相关的数据。在这种情况下,你记得的单词让你判断麦片是好的。
1)LSTM
LSTM具有与RNN类似的控制流。它在前向传播时处理传递信息的数据。区别在于LSTM单元内的操作。
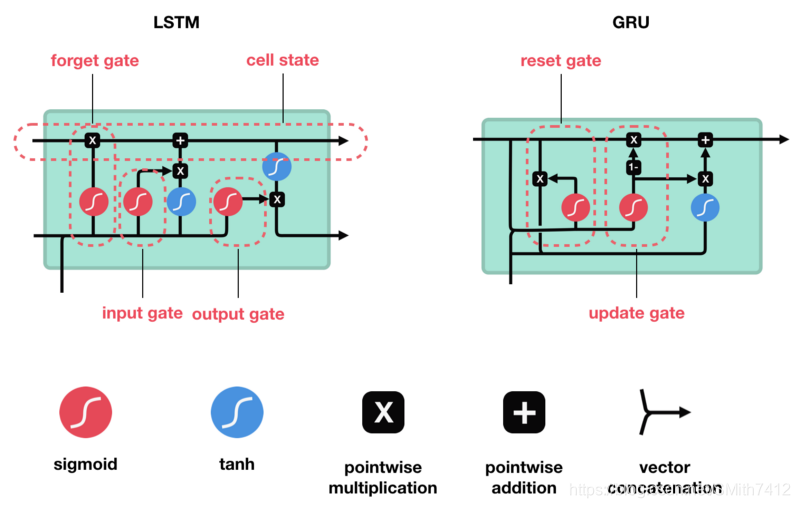
这些操作用于允许LSTM保留或忘记信息。这些操作可能会有点难,所以我们将逐步介绍这些它们。
核心概念
LSTM的核心概念是单元状态(cell state),它是多种不同的门。单元状态充当传输的高速公路,在序列链中传递相关信息。你可以将其视为网络的记忆。理论上,单元状态可以在序列的整个处理过程中携带相关信息。因此,即使来自较早时间步的信息也可用于较晚时间步,从而减少短期记忆的影响。随着单元状态继续进行,信息通过门被添加或移除到单元状态。门是不同的神经网络,用来决定哪些信息可以允许进入单元状态。在训练中,门可以知道哪些信息是需要保存或忘记的。
LSTM包含遗忘门、输入门、单元状态、输出门
遗忘门
首先,我们介绍遗忘门(forget gate)。此门决定应丢弃或保留哪些信息。来自先前隐藏状态和来自当前输入的信息通过sigmoid函数传递。值介于0和1之间。越接近0越容易遗忘,越接近1则意味着要保留。
输入门
要更新单元状态,我们需要输入门。首先,我们将先前的隐藏状态和当前输入传递给sigmoid函数。这决定了通过将值转换为0到1来更新哪些值。0表示不重要,1表示重要。你还将隐藏状态和当前输入传递给tanh函数,将它们压缩到-1和1之间以帮助调节网络。然后将tanh输出与sigmoid输出相乘。sigmoid输出将决定哪些信息很重要,需要tanh输出保存。
单元状态
现在我们有足够的信息来计算单元状态。首先,单元状态逐点乘以遗忘向量。如果它乘以接近0的值,则有可能在单元状态中丢弃值。然后我们从输入门获取输出并进行逐点加法,将单元状态更新为神经网络发现相关的新值。这就得到了新的单元状态。
输出门
最后我们有输出门。输出门决定下一个隐藏状态是什么。请记住,隐藏状态包含有关先前输入的信息。隐藏状态也用于预测。首先,我们将先前的隐藏状态和当前输入传递给sigmoid函数。然后我们将新的单元状态传递给tanh函数。将tanh输出与sigmoid输出相乘,以决定隐藏状态应携带的信息。它的输出是隐藏状态。然后将新的单元状态和新的隐藏状态传递到下一个时间步。
回顾一下,遗忘门决定了哪些内容与前面的时间步相关。输入门决定了从当前时间步添加哪些信息。输出门决定下一个隐藏状态应该是什么。
代码演示
通过查看代码有些人可以更好的理解,以下是一个使用python伪代码的例子。

总结:
1.首先,先前的隐藏状态和当前输入被连接起来。我们称之为组合(combine)。
2.组合的结果传入到遗忘层中。该层删除不相关的数据。
3.使用组合创建候选(candidate)层。它保存要添加到单元状态的可能值。
4. 组合也传入输入层。该层决定应将候选者中的哪些数据添加到新的单元状态。
5.在计算遗忘层,候选层和输入层之后,使用那些向量和先前的单元状态来计算单元状态。
6.然后计算输出。
7.输出和新的单元状态逐点相乘得到新的隐藏状态。
就是这些!LSTM网络的控制流程是几个张量操作和一个for循环。你可以使用隐藏状态进行预测。结合所有这些机制,LSTM能够选择在序列处理期间需要记住或忘记哪些信息。
2)GRU
所以现在我们知道LSTM是如何工作的,让我们简单地看一下GRU。GRU是新一代RNN,与LSTM非常相似。GRU不使用单元状态,而是使用隐藏状态来传输信息。它也只有两个门,一个重置门和一个更新门(reset gate and update gate)。
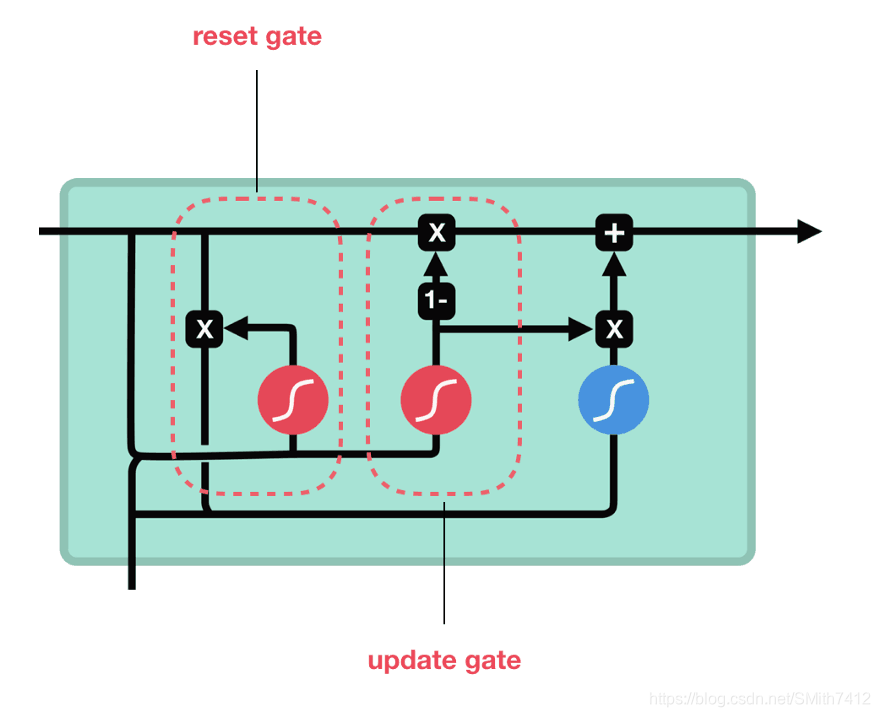
更新门
更新门的作用类似于LSTM的遗忘和输入门。它决定要丢弃哪些信息和要添加哪些新信息。
重置门
重置门是另一个用来决定要忘记多少过去的信息的门。
这就是GRU。GRU的张量操作较少;因此,他们的训练速度要比LSTM快一些。但还说不清哪个更好。研究人员和工程师通常都会尝试,以确定哪一个更适合他们的用例。
原文更加精彩哟~
一份详细的LSTM和GRU图解:https://www.atyun.com/30234.html
其作者利用动态图片,帮助理解LSTM与GRU的原理,很好理解!
关于Text-RNN的原理可以参考一下文章!
更好文章参考:
1、Tensorflow实战(1): 实现深层循环神经网络:https://zhuanlan.zhihu.com/p/37070414
2、从LSTM到Seq2Seq-大数据算法:https://x-algo.cn/index.php/2017/01/13/1609/
3、RCNN kreas:https://github.com/airalcorn2/Recurrent-Convolutional-Neural-Network-Text-Classifier
4、RCNN tf:https://github.com/zhangfazhan/TextRCNN
5、RCNN tf (推荐):https://github.com/roomylee/rcnn-text-classification
