版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_40883132/article/details/83119735
读取20类新闻文本的数据细节
#从sklearn.datasets 里导入新闻数据抓取器fetch_20newsgroups
from sklearn.datasets import fetch_20newsgroups
#需要及时从互联网下载数据
news=fetch_20newsgroups(subset='all')
#查验数据规模和细节
print (len(news.data))
print(news.data[0])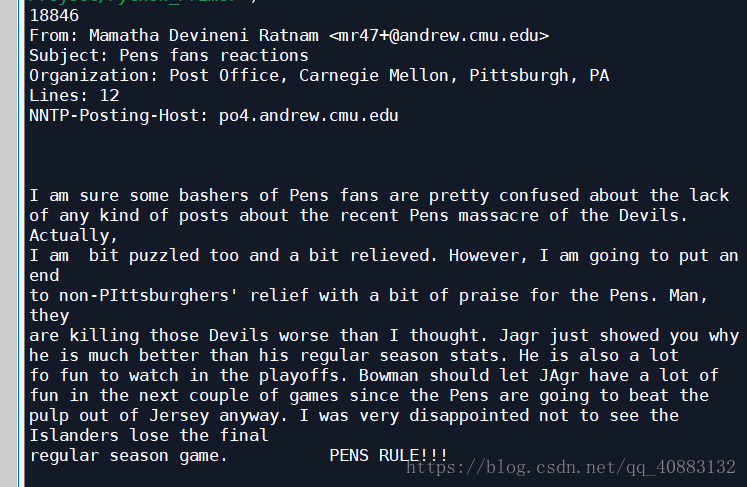
数据分割:
#数据分割
from sklearn.cross_validation import train_test_split
#随机采样25%的数据样本作为测试集
X_train,X_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33)
使用朴素贝叶斯分类器对新闻 文本数据进行预测:
#使用朴素贝叶斯分类器进行预测
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer()
X_train=vec.fit_transform(X_train)
X_test=vec.transform(X_test)
#从sklearn.naive_bayes里导入朴素贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
#初始化朴素贝叶斯模型
mnb=MultinomialNB()
#使用 训练数据对模型参数进行估计
mnb.fit(X_train,y_train)
#对测试样本进行预测额,结果保留在储存变量y_predictio中
y_predict=mnb.predict(X_test)对朴素贝叶斯分类器在新闻文本数据上的变现进行性能评估:
#性能评估
from sklearn.metrics import classification_report
print('The Accuracy of Naive Bayes Classifier is',mnb.score(X_test,y_test))
print(classification_report(y_test,y_predict,target_names=news.target_names))
特点分析:朴素贝叶斯模型被广泛应用于海量互联网文本分类任务由于较强的特征条件独立假设,使得模型预测所需要的估计参数规模从幂指数量级向线性级减少,极大地节约了内存消耗和计算时间。但是,也正是
受这种强假设的限制,模型训练时无法将各个特征之间的联系考量在内,使得该模型在其他数据特征关联性较强的分类任务上表现不佳。
完整代码参考:
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 17 22:38:37 2018
@author: asus
"""
#从sklearn.datasets 里导入新闻数据抓取器fetch_20newsgroups
from sklearn.datasets import fetch_20newsgroups
#需要及时从互联网下载数据
news=fetch_20newsgroups(subset='all')
#查验数据规模和细节
print (len(news.data))
print(news.data[0])
#数据分割
from sklearn.cross_validation import train_test_split
#随机采样25%的数据样本作为测试集
X_train,X_test,y_train,y_test=train_test_split(news.data,news.target,test_size=0.25,random_state=33)
#使用朴素贝叶斯分类器进行预测
from sklearn.feature_extraction.text import CountVectorizer
vec=CountVectorizer()
X_train=vec.fit_transform(X_train)
X_test=vec.transform(X_test)
#从sklearn.naive_bayes里导入朴素贝叶斯模型
from sklearn.naive_bayes import MultinomialNB
#初始化朴素贝叶斯模型
mnb=MultinomialNB()
#使用 训练数据对模型参数进行估计
mnb.fit(X_train,y_train)
#对测试样本进行预测额,结果保留在储存变量y_predictio中
y_predict=mnb.predict(X_test)
#性能评估
from sklearn.metrics import classification_report
print('The Accuracy of Naive Bayes Classifier is',mnb.score(X_test,y_test))
print(classification_report(y_test,y_predict,target_names=news.target_names))
扫描二维码关注公众号,回复:
3753362 查看本文章
