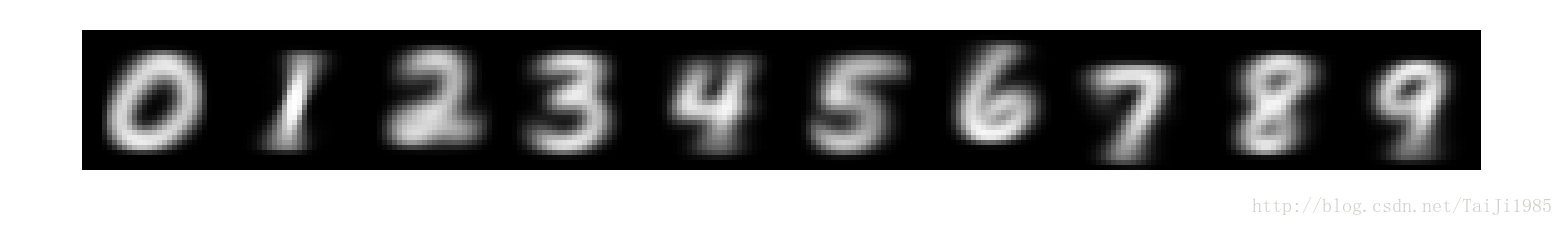问题
为了方便对比,我们仍然拿手写识别Mnist这个数据集作为我们的实验的数据集。Mnist数据集[1,2] 中包含60000张手写数字图片,10,000 张测试图片。每张图片的大小为28*28,包含一个手写数字。下面是一些样本举例:

我们希望实现这样一个分类器: 给定一张手写图片,分类器给出改数字属于哪个分类。(0-9共10个分类)
贝叶斯公式
(公式1)
给定B时A的概率等于给定A时B的概率乘以A的概率 除以 B的概率。
举例:
假设下雨的概率 P(A) = 0.1 不下雨的概率为 P(not A) = 1-P(A) = 0.9 ,假设P(B)表示带伞的概率。
下雨时我带伞的概率为 P(B|A) = 0.8 ,下雨不带伞的概率为P(not B|A) = 1-P(B|A) = 0.2
不下雨时我带伞的概率为 P(B| not A) = 0.05 ,不下雨不带伞不带伞的概率为P(not B |not A) = 0.95
那么有一天,我带伞了,问那天下雨吗,或者下雨的概率是多少?
根据公式,我们还需要知道带伞的概率P(B),
可以用全概率公式来求
带伞时,下雨的概率为:
那么 P(not A | B) = 1 - P(A|B) = 0.36 < P(A|B)
说明, 我带了伞更有可能是那天下雨。
另外,我们其实没有必要计算P(B),因为对于分类问题来说,我们只需要比较 P(A|B) 和 P(not A|B)的大小即可。即: P(B|A)P(A) vs P(B|not A)P(not A)
上述方法实际上是使用了最大后验概率(MAP)的方法,即认为后验概率最大的那个情况(分类)是最优可能的情况(分类)。
P(A)的值是一个先验概率,是通过已有经验得到的,比如本年度下雨天数和总天数的比值得到。
如果样本是多维数据,
对Mnist应用朴素贝叶斯分类
在数据集中,每个图片作为一个样本,它的分类结果共有10类,分别为0,1,2,3,…9 。
数据集中每张图片的的每个像素采用灰度值,我们为了方便下面处理将它变成二值图像。即将非0的点置为1。这样处理后,我们可以认为一个像素是否为1变成一个0-1分布。
我们计算这样一个概率值:
(公式3)
为了表述简单,我们令
(公式4)
我们求解的目标可以写为:
(公式5)
简单来说就是计算
那么下面的任务就是要求解
(公式6)
我们通俗的理解一下这个公式, 如果从属于第0类的图片在像素20上是1 个概率较高。那么如果发现像素20为1,则属于第0类的概率较高。在看分母,如果对于所有图片,在像素20上的1概率较高,说明这个像素对于分类的区分能力低,所以分母这个概率越高,则总的概率越低。
下面我们来逐个获得公式中需要的量。第i个样本第k个像素为1的概率,我们通过统计所有样本得到。
根据0-1分布公式
对上式求对数
为了让公式看起来简练,令
使用matlab实现
function model = bc_train(x,y,J)
%x : 样本 y:标签 J分类数
[K,N] = size(x); %K为维度, N为图像个数
%计算 P(x_k^i)
px = sum(x,2);
px = px/N;
%p(y^i=j)计算属于每一类的图像个数
py= zeros(J,1);
for j = 1:J
py(j) = sum(y == j);
end
%p(x|y)
pxy = zeros(J,K);
for j=1:J
xj = x(:,y == j); %属于J的图片
pxy(j,:) = sum(xj,2) / size(xj,2);
end
model.px = px;
model.py = py;
model.pxy = pxy;
model.J = J;
end
function yp = bc_predit(x,y,model)
px =model.px + 1e-10;
pxy = model.pxy;
py =model.py;
J= model.J;
[K,N] = size(x); %K为维度, N为待分类图像个数
% log_pyx 应为 J*N的矩阵, X为K*N的矩阵 pxy 为 J*K的矩阵
log_pxy = log(pxy+1e-10);
% log_pxik 应为 N*K 表示样本i的第k个像素的对数概率 px为K*1
rpx = repmat(px',N,1); % N*K
log_pxik = x'.*log(rpx) + (1-x').*(1-log(rpx));
t = sum(log_pxik,2);
t =repmat(t',J,1);
%log_pyx 应为 J*N的矩阵
log_pyx = log_pxy*x + log(1-pxy)*(1-x) + repmat(log(py),1,N) - t;
[m,I] = max(log_pyx);
yp = I;
end
function bc_show_model(model)
pa = [];
pxy = model.pxy;
for i = 1:model.J
p = pxy(i,:);
p = reshape(p,28,28);
pa = [pa p];
end
pa = imresize(pa,10,'nearest');
imshow(pa);
end测试脚本
labels = loadMNISTLabels('mnist/train-labels.idx1-ubyte');
images = loadMNISTImages('mnist/train-images.idx3-ubyte');
%二值化图像
images(images>0) = 1;
%label +1
labels = labels+1;
m = bc_train(images,labels,10);
labels = loadMNISTLabels('mnist/t10k-labels.idx1-ubyte')+1;
images = loadMNISTImages('mnist/t10k-images.idx3-ubyte');
images(images>0) = 1;
yp = bc_predit(images,labels,m);
acc = sum(yp' == labels)/length(labels)
最后输出结果 准确率 : 0.8418
使用bc_show_model 将