首先给出贝叶斯公式:

其中x表示样本,c表示类别。
一些概念:
P(c)为先验概率,即在得到新数据前的假设概率;
P(c|x)为后验概率,即在看到新数据后,我们要计算的该假设概率;
P(x|c)为该假设下得到这一数据的概率,称为似然度;
P(x)是在任意假设下得到这一数据的概率,称为标准化常量。
公式左边是这样一个条件概率:已知样本x,求它属于c类的概率。那么,相应的算法就变成,对于给定的待分类样本x,分别计算它属于不同分类的概率,概率最大者对应的类别就是x的类别。那么,问题就转变为求解公式右边的3个概率,下面就来看这3个概率怎么求。
P(
x)与类别标记无关,是一个常量,不影响最后大小的比较,计算中可以忽略;
P(c)表达了样本空间中各类所占的比例,可以用如下公式计算:
 P(x|c)是所有属性上的联合概率,不好直接估计。这里要用到
朴素贝叶斯分类器的一个重要假设:
属性条件独立性假设,即假设所有属性相互独立。
P(x|c)是所有属性上的联合概率,不好直接估计。这里要用到
朴素贝叶斯分类器的一个重要假设:
属性条件独立性假设,即假设所有属性相互独立。
P(x|c)是所有属性上的联合概率,不好直接估计。这里要用到
朴素贝叶斯分类器的一个重要假设:
属性条件独立性假设,即假设所有属性相互独立。
基于属性条件独立性假设,贝叶斯公式可写成:
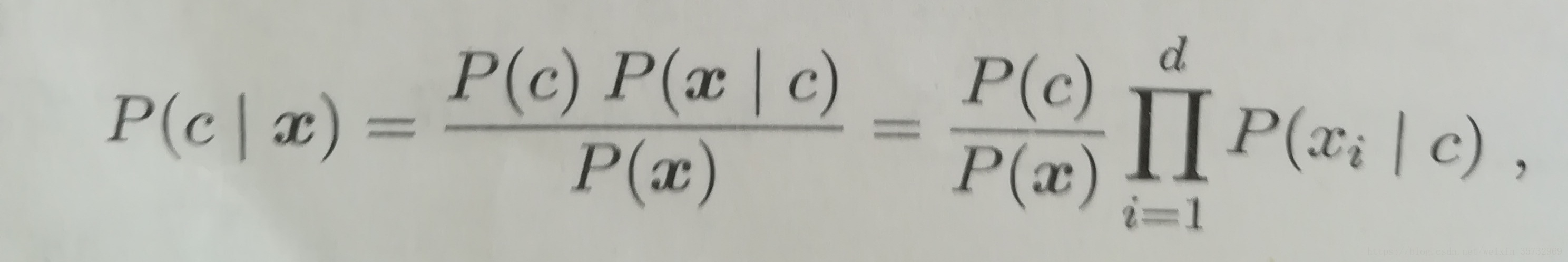
其中d为属性数目,Xi为第i个属性上的取值。忽略P(x),进一步得到贝叶斯判定准则:

问题转变为求条件概率P(Xi|c)。对于离散属性,通过下面公式计算:

对于连续属性,公式如下:
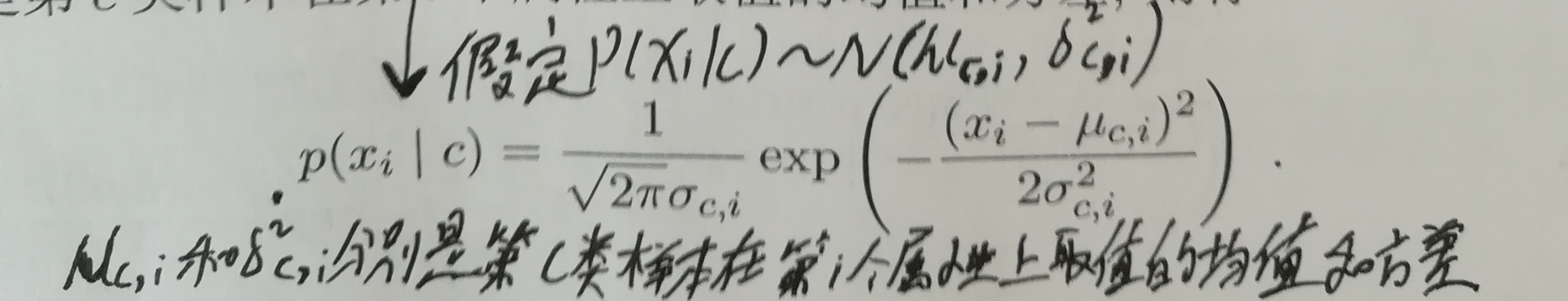
至此,根据贝叶斯
判定准则,可以得到x的分类。
为了防止训练集中有属性未出现,常用“拉普拉斯修正”(平滑处理),把P(c)和P(Xi|c)改写成如下形式:

matlab代码:
%每个属性可能取值数,0表示连续属性
%validattrs_num = [3,3,3,3,3,2,0,0];
%mean_variance:计算的均值和方差,结构:struct('mean',{[1,2],[2,3]},'variance',{[3,4],[4,5]});
function [class] = predictFunc(x,y,validattrs_num,mean_variance,example1)
t = tabulate(y+1);
%类别标记
classes = t(:,1)-1;
%类别数
classes_num = t(:,2);
%类别频率,拉普拉斯修正
classes_fr = (classes_num+1)./(length(y)+length(classes));
%类别预测概率
pr = 1;
max_pr = 0;
%预测的类别
class = 0;
%同类别同属性计数器
sameattr_num = 0;
%类别循环
for i=1:length(classes),
%连续属性的均值方差的索引
index= 1;
%属性循环
for j=1:length(example1),
%离散属性
if validattrs_num(j)~=0,
%样本循环
for k=1:length(y),
%处理某一类别
if classes(i) == y(k),
%离散属性值相同,计数
if isequal(x{k,j},example1{1,j}),
sameattr_num = sameattr_num + 1;
endif;
endif;
endfor;
%拉普拉斯修正的比例
pr = pr * ((sameattr_num+1)/(classes_num(i)+validattrs_num(j)));
sameattr_num = 0;
else%连续属性概率密度
pr = pr * exp(-(example1{1,j}-mean_variance.mean{index}(i))^2/(2*mean_variance.variance{index}(i)))/((2*pi*mean_variance.variance{index}(i))^0.5);
index = index + 1;
endif;
endfor;
pr = pr * classes_fr(i);
%最大概率对应的类别
if pr>max_pr,
max_pr = pr;
class = classes(i);
endif;
pr = 1;
endfor;
参考资料:周志华《机器学习》,Allen《贝叶斯思维》
相关博文:
半朴素贝叶斯分类器