朴素贝叶斯( Naive Bayes )分类器,是指将贝叶斯( Bayes )原理应用于具有较强独立性假设的特征(变量),而得到的一族简单的概率分类器。
Naive Bayes 分类器假设:
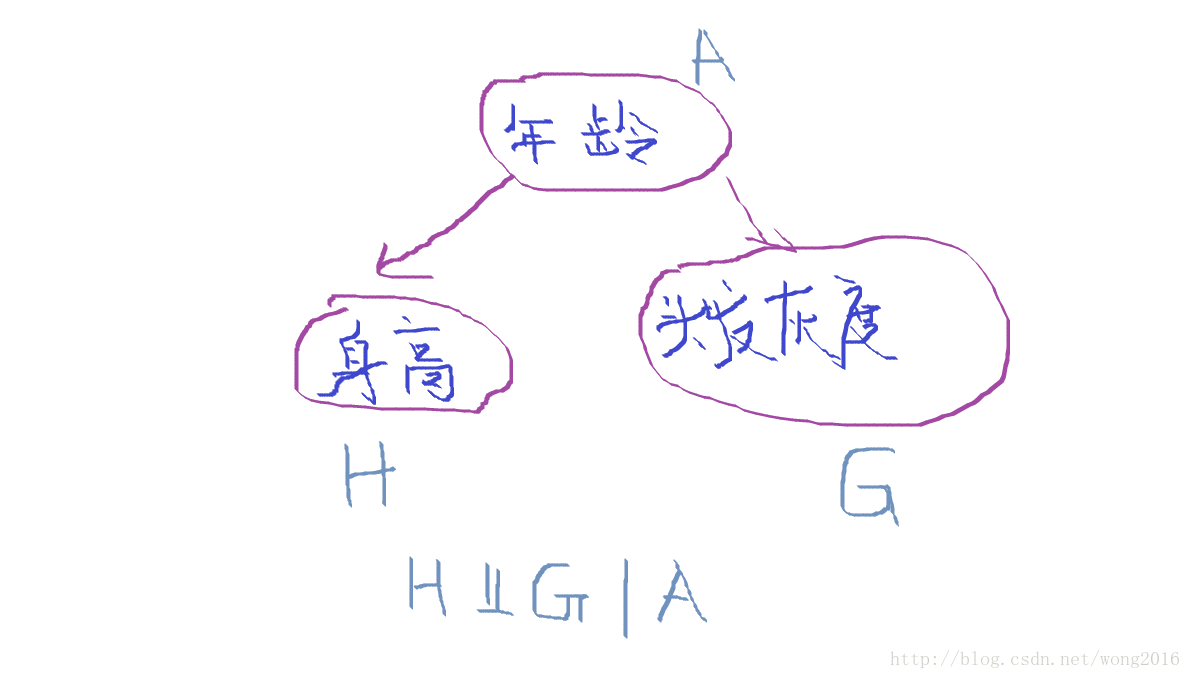
给定类变量,一个特定的变量独立于其它任何变量。称该独立性为条件独立,例如,给定
简记为
已知一个人的年龄,那么他的身高和头发灰度是条件独立的。
概率模型
假设有 K 个类,不妨记为
在 Bayes 统计中,称
“naive” 条件独立假设:
给定类

这样,后验概率可以表示为
故
这里,
Bayes 分类器
根据最大后验概率( maximum a posteriori or MAP )的决策规则,将待分类的向量
参数估计和事件模型
通常,在没有关于类的先验知识的情况下,类的先验概率可取均匀分布,即,
一个性别分类的例子
问题描述:根据一个人的身高(height )、体重(weight )和脚的尺寸(footsize )这三个特征,预测该人的性别(sex )。
- 训练
实例训练集见下表:
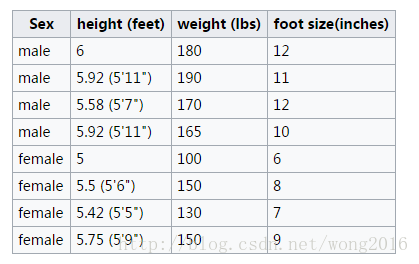
假设特征都服从正态分布,利用两个性别类的样本分别估计这三个特征的均值和方差,确定正态分布。

假设性别类的先验概率
- 检验
给定一个待分类的样本:

分别计算该样本属于两类的后验概率:
其中,分母
注意到,给定样本后,分母是常数,因此不影响分类,可以忽略。计算分子中的各项概率:
所以
同理,可以计算得到
显然,女性类的后验概率大于男性类的,因此,预测该样本为女性。
数据试验
我们在机器学习的基准数据集 HouseVotes84 上训练 Naive Bayes 分类器,并在该数据集上检验分类效果。HouseVotes84 数据集由美国众议院435名议员在1984年对16项议案的投票结果组成。每名众议员分别对16项议案投赞成(简记为y )、反对(简记为n )或中立。该数据集位于 R 包 mlbench 里,由435行观测、17个变量(列)的数据框组成。这17个变量分别为:
- Class Name: 2 (democrat, republican)
- handicapped-infants: 2 (y,n)
- water-project-cost-sharing: 2 (y,n)
- adoption-of-the-budget-resolution: 2 (y,n)
- physician-fee-freeze: 2 (y,n)
- el-salvador-aid: 2 (y,n)
- religious-groups-in-schools: 2 (y,n)
- anti-satellite-test-ban: 2 (y,n)
- aid-to-nicaraguan-contras: 2 (y,n)
- mx-missile: 2 (y,n)
- immigration: 2 (y,n)
- synfuels-corporation-cutback: 2 (y,n)
- education-spending: 2 (y,n)
- superfund-right-to-sue: 2 (y,n)
- crime: 2 (y,n)
- duty-free-exports: 2 (y,n)
- export-administration-act-south-africa: 2 (y,n)
在R 环境加载数据集 HouseVotes84,并显示前6行
library(mlbench)
data(HouseVotes84)
head(HouseVotes84)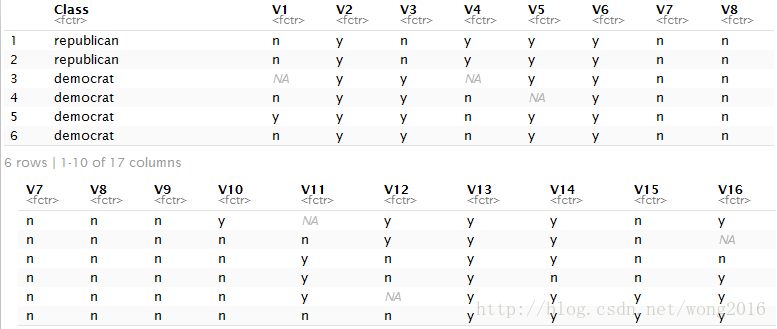
数据集中的 NA,代表“中立”的投票,在训练分类器时被忽略。
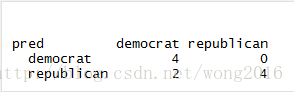
现在,以HouseVotes84 为训练集,使用 e1071 包的函数naiveBayes 建立 Naive Bayes 分类器,预测该数据集前10行
的分类结果,并与真实类作比较。
library(e1071)
data(HouseVotes84, package = "mlbench")
model <- naiveBayes(Class ~ ., data = HouseVotes84)
pred <- predict(model, HouseVotes84[1:10,])
table(pred, HouseVotes84$Class[1:10])