⭐原文链接:Siamese Neural Networks for One-shot Image Recognition (cmu.edu)
这部分主要讲解模型的数学结构和训练方法,可以参照代码进行梳理与理解(代码将在PartⅣ中详细说明)。
*注:文中部分字母由于格式问题会出现部分偏差,可结合字母在特定段落中的位置进行理解(如小数点显示为方框等)。
*黑字——原文翻译
*红字——存在问题
*蓝字——优势
*绿字——主观分析(未对全部细节进行分析,仅针对本文内容补充)
3. Deep Siamese Networks for Image Verification
在20世纪90年代初,Bromley和LeCun首次引入Siamese nets以解决图像匹配问题(image matching problem)的签名验证(signature verification)。
siamese神经网络由接受不同输入的双网络(twin networks)组成,但由顶部的能量函数(energy function)连接。这个函数在每一侧的最高级别特征表示(feature representation)之间计算一些度量(metric)(图3)。
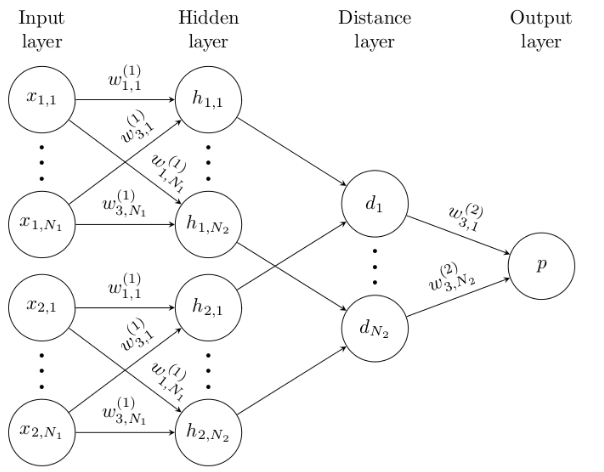
Figure3. 一个简单的2隐层siamese network,用于logistic prediction p 的binary classification.网络的结构在顶部和底部部分进行复制,形成双网络,每层都有共享的权重矩阵(shared weight matrices)。
双网络之间的参数是相关联的(tied)。权重关联(Weight tying)保证了两个极其相似的图像不可能被它们各自的网络映射到特征空间中非常不同的位置,因为每个网络都计算相同的函数。
*siamese nets中的两个网络间的网络参数是一致的,保证从两图像中获取特征的方式一致。
此外,网络是对称的(symmetric),因此每当我们向双胞胎网络呈现两张不同的图像时,最上面的连接层将计算相同的度量,就像我们将相同的两张图像呈现给相反的双胞胎一样。
在LeCun等人的文章中,作者使用了包含对偶项(dual terms)的对比能量函数(contrastive energy function)来降低相似对(like pairs)的能量,增加不同对(unlike pairs)的能量。
然而,在本文中,我们使用了两个特征向量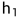 和
和 之间的加权
之间的加权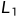 距离,并结合了一个sigmoid激活,它映射到区间[0,1]。因此,cross-entropy目标是训练网络的自然选择。请注意,在LeCun等人的论文中,他们直接学习了相似度量,这是由能量损失隐式定义的,而我们根据Facebook的DeepFace论文中的方法,按照上面指定的方法固定了度量。
距离,并结合了一个sigmoid激活,它映射到区间[0,1]。因此,cross-entropy目标是训练网络的自然选择。请注意,在LeCun等人的论文中,他们直接学习了相似度量,这是由能量损失隐式定义的,而我们根据Facebook的DeepFace论文中的方法,按照上面指定的方法固定了度量。
我们性能最好的模型在全连接层(fully-connected layers)和顶级能量函数(top-level energy function)之前使用多重卷积层(multiple convolutional)。卷积神经网络在许多大规模计算机视觉应用(large-scale computer vision applications)中,特别是在图像识别(image recognition)任务中取得了优异的效果。
有几个因素使得卷积网络(convolutional networks)特别有吸引力。局部连通性可以大大减少模型中的参数数量,这在本质上提供了一些内置正则化的形式,尽管卷积层在计算上比标准非线性(standard nonlinearities)更昂贵。
此外,这些网络中使用的卷积操作具有直接的过滤解释(direct filtering interpretation),其中每个特征映射都针对输入特征进行卷积,以将模式识别为像素组(identify patterns as groupings of pixels)。
因此,每个卷积层的输出对应于原始输入空间(original input space)中的重要空间特征(spatial features),并对简单的变换提供一些鲁棒性(robustness)。最后,非常快速的CUDA库现在可用来构建大型卷积网络,而不需要大量不可接受的训练时间。
我们现在详细介绍了siamese nets的结构和我们实验中使用的学习算法的细节。
3.1. Model
我们的标准模型是一个L层的siamese convolutional neural network,每个层有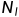 units,其中
units,其中 表示第一个双胞胎在l层中的隐藏向量,
表示第一个双胞胎在l层中的隐藏向量,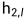 表示第二个双胞胎的隐藏向量。我们在第一个L-2层中只使用rectified linear(ReLU)units,在其余层中使用sigmoidal units。
表示第二个双胞胎的隐藏向量。我们在第一个L-2层中只使用rectified linear(ReLU)units,在其余层中使用sigmoidal units。
该模型由一系列卷积层组成,每个卷积层使用具有不同大小(size)的滤波器和固定步幅(fixed stride)为1的单通道(single channel)。卷积滤波器的数量指定为16的倍数以优化性能。网络对输出特征映射应用一个ReLU activation function,可选地跟随一个过滤器大小和步幅为2的maxpooling。因此每一层的第k个filter map的形式如下:
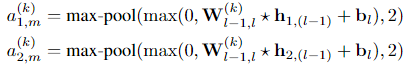
其中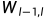 ,l是表示层l的特征映射的三维张量,我们采取了
,l是表示层l的特征映射的三维张量,我们采取了 为有效的卷积运算(valid convolutional operation),对应于只返回那些输出单元,这些输出单元是每个卷积滤波器(convolutional filter)与输入特征映射(input feature maps)之间完全重叠(complete overlap)的结果。
为有效的卷积运算(valid convolutional operation),对应于只返回那些输出单元,这些输出单元是每个卷积滤波器(convolutional filter)与输入特征映射(input feature maps)之间完全重叠(complete overlap)的结果。
最后卷积层中的units i被平化为单个向量(flattened into a single vector)。这个卷积层之后是一个全连接层,然后是另一层,计算每个siamese twin之间的诱导距离度量(induced distance metric),这是一个single sigmoidal output unit.。更准确地说,预测向量为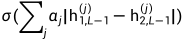 ,其中σ为sigmoidal activation function。最后一层在第(L−1)个隐层的学习特征空间上引入度量,并对两个特征向量之间的相似性进行评分。
,其中σ为sigmoidal activation function。最后一层在第(L−1)个隐层的学习特征空间上引入度量,并对两个特征向量之间的相似性进行评分。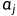 是模型在训练过程中学习到的附加参数,加权分量距离(component-wise distance)的重要性。这为连接两个siamese twins的网络定义了最后的第L个全连接层。
是模型在训练过程中学习到的附加参数,加权分量距离(component-wise distance)的重要性。这为连接两个siamese twins的网络定义了最后的第L个全连接层。
我们描述了一个例子(图4),它显示了我们所考虑的模型的最大版本。该网络在验证任务中也给出了最好的结果。
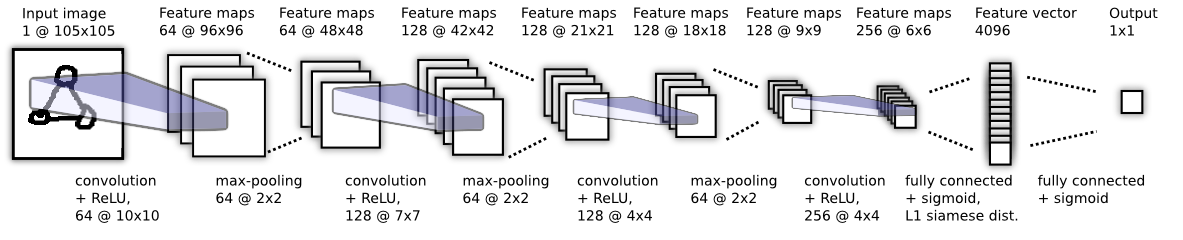
Figure4. 为验证任务选择的最佳卷积结构。没有描述Sianese twin,但在4096单元全连接层(fully-connected layer)后立即连接,其中向量之间的L1分量距离(L1 component-wise distance between vectors)被计算。
3.2. Learning
Loss function
M表示minibatch size,其中i索引第i个minibatch。
现在设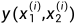 是一个长度为m的向量,其中包含minibatch的labels。我们假设当x1和x2来自同一个字符类(same character class)时
是一个长度为m的向量,其中包含minibatch的labels。我们假设当x1和x2来自同一个字符类(same character class)时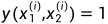 ,否则
,否则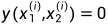 。我们在二元分类器(binary classifier)上施加一个正则化的交叉熵目标(regularized cross-entropy objective),其形式如下:
。我们在二元分类器(binary classifier)上施加一个正则化的交叉熵目标(regularized cross-entropy objective),其形式如下:
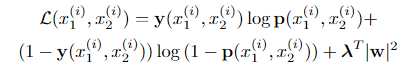
*此处为深度学习常见损失函数设置方法,不同点为确定的示例为两个事物的比较对,标签为是否为同一类,同一类为1,不同类为0。
*需要了解交叉熵损失函数的计算公式,以及正则化项的添加。
Optimization
该目标与标准反向传播算法(standard backpropagation algorithm)相结合,其中由tied weights,梯度在twin networks上是加性的(additive)。我们用学习率 ,动量
,动量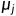 和
和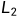 正则化权值
正则化权值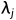 按层定义(layer-wise),确定minibatch size为128,因此我们在epoch T的更新规则如下:
按层定义(layer-wise),确定minibatch size为128,因此我们在epoch T的更新规则如下:

其中▽ 为某层第j个神经元与上一层第k个神经元之间权值的偏导数(partial derivative)。
为某层第j个神经元与上一层第k个神经元之间权值的偏导数(partial derivative)。
*此处为标准反向传播算法,通过训练完成参数的更新。
Weight initialization
我们将卷积层中的所有网络权重初始化为零均值和标准偏差为10^-2的正态分布。偏差也从正态分布初始化,但均值为0.5,标准差为10^-2。在全连接层中,偏差以与卷积层相同的方式初始化,但权重是从一个更宽的正态分布中提取的,其均值为零,标准差为2*10^-1。
*此处为网络权重和偏差的初始化设置,包括卷积层和全连接层中的权重和偏差。
Learning schedule
尽管我们允许每一层有不同的学习率,但学习率在整个网络中以每个epoch 1%的速度均匀衰减(decayed uniformly)
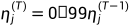 。
。
我们发现,通过退火学习率(annealing the learning rate),网络能够更容易地收敛到局部极小值(converge to local minima),而不会陷入误差曲面(getting stuck in the error surface)。我们固定动量从每一层的0.5开始,increasing linearly each epoch,直到达到值,第j层的单个动量项。
*此处涉及到学习率的理解,以及添加动量的意义。
我们训练每个网络最多200个epochs,但在一组320个oneshot learning tasks上监测one-shot validation error,这些任务是由验证集中的alphabets and drawers随机生成的。
当validation error在20个epochs内没有下降时,我们停止并根据one-shot validation error在最佳epoch使用模型参数。如果validation error在整个学习计划(entire learning schedule)中持续减少,我们将保存此过程生成的模型的最终状态(final state of the model)。
*需掌握一些训练的技巧。
Hyperparameter optimization
我们使用了beta version of Whetlab,一个贝叶斯优化框架(Bayesian optimization framework),执行超参数选择。
*Whetlab用来进行超参数选择。
1) 对于学习进度和正则化超参数,我们设置了layerwise learning rate 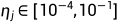 ,layer-wise momentum
,layer-wise momentum 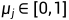 和layer-wise regularization penalty
和layer-wise regularization penalty 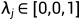 。
。
2) 对于网络超参数(network hyperparameters),我们让卷积滤波器(convolutional filters)的size从3x3变化到20x20,而每层卷积滤波器(convolutional filters)的number使用16的倍数从16变化到256。
3) 全连接层(Fully-connected layers)的范围从128到4096 units,也是16的倍数。
我们将优化器(optimizer)设置为最大化一次验证集(one-shot validation set)的准确性。分配给single Whetlab iteration的score是在任何epoch发现的该指标(metric)的最高值。
Affine distortions
*此处主要是对原始图像进行变化操作(常用的有旋转,翻转等),以增强数据,提高识别效果。
此外,我们用small affine distortions增强训练集(图5)

Figure 5. 为Omniglot数据集中的单个字符生成的随机affine distortions示例。
对于每一对图像 ,我们生成一对affine transformations
,我们生成一对affine transformations  ,
, 得到
得到 ,
,  ),其中,由多维均匀分布(multidimensional uniform distribution)随机确定(determined stochastically)。
),其中,由多维均匀分布(multidimensional uniform distribution)随机确定(determined stochastically)。
对于任意变换T,我们有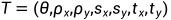 ,其中
,其中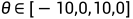 ,
, ,
,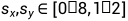 ,
,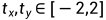 。转换的每一个组成部分的概率都是0.5。
。转换的每一个组成部分的概率都是0.5。
参考文献
Koch, Gregory R.. “Siamese Neural Networks for One-Shot Image Recognition.” (2015).