文章目录
神经网络与深度学习-浅层神经网络
神经网络概述
神经网络概述
计算神经网络的输出
多样本向量化
向量化实现
激活函数
为什么需要非线性激活函数
激活函数的导数
神经网络的梯度下降
直观理解反向传播
随机初始化
-
神经网络模型中的参数权重W是不能全部初始化为零的,原因如下:
如果在初始时,两个隐藏神经元的参数设置为相同的大小,那么两个隐藏神经元正向传播时对输出单元的影响也是相同的,通过反向梯度下降去进会得到同样的梯度大小,所以在经过多次迭代后,两个隐藏层单位仍然是对称的。无论设置多少个隐藏单元,其最终的影响都是相同的,那么多个隐藏神经元就没有了意义。所以,在初始化的时候,W参数要进行随机初始化,b则不存在对称性的 问题它可以设置为0。
举例来说明:若一个浅层神经网络包含两个输入,隐藏层包含两个神经元,如果2个权重都初始化为零,即:
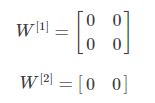
这样使得隐藏层第一个神经元的输出等于第二个神经元的输出,即正向传播a相同;经过反向传播推导,Z相同,dW也相同。因此,这样的结果是隐藏层两个神经元对应的权重行向量W每次迭代更新都会得到完全相同的结果,完全对称。这样隐藏层设置多个神经元就没有任何意义了。

我们把这种权重W全部初始化为零带来的问题称为symmetry breaking problem。解决方法也很简单,就是将W进行随机初始化(b可初始化为零)。
W_1 = np.random.randn((2,2))*0.01
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0
这里我们将W乘以0.01的目的是尽量使得权重W初始化比较小的值。之所以让W比较小,是因为如果使用sigmoid函数或者tanh函数作为激活函数的话,W比较小,得到的|z|也比较小(靠近零点),而零点区域的梯度比较大,这样能大大提高梯度下降算法的更新速度,尽快找到全局最优解。如果W较大,得到的|z|也比较大,附近曲线平缓,梯度较小,训练过程会慢很多。
当然,如果激活函数是ReLU或者Leaky ReLU函数,则不需要考虑这个问题。但是,如果输出层是sigmoid函数,则对应的权重W最好初始化到比较小的值。
