train.py调用provider和tf_util包。作用是完成基于数据集的训练,并且log了训练结果。
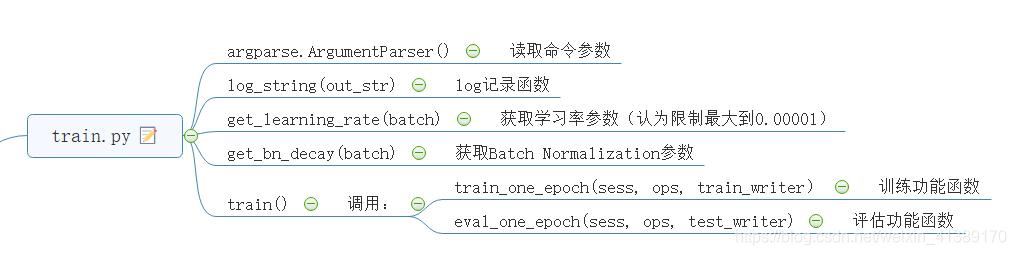
结构图如图所示
个人理解的注释:
import argparse# 程序使用端口指令
import math
import h5py
import numpy as np
import tensorflow as tf
import socket# 通信
import importlib
import os
import sys
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
sys.path.append(BASE_DIR)
sys.path.append(os.path.join(BASE_DIR, 'models'))
sys.path.append(os.path.join(BASE_DIR, 'utils'))
import provider
import tf_util
parser = argparse.ArgumentParser()
#值令参数读取
parser.add_argument('--gpu', type=int, default=0, help='GPU to use [default: GPU 0]')
parser.add_argument('--model', default='pointnet_cls', help='Model name: pointnet_cls or pointnet_cls_basic [default: pointnet_cls]')
parser.add_argument('--log_dir', default='log', help='Log dir [default: log]')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number [256/512/1024/2048] [default: 1024]')
parser.add_argument('--max_epoch', type=int, default=250, help='Epoch to run [default: 250]')
parser.add_argument('--batch_size', type=int, default=32, help='Batch Size during training [default: 32]')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Initial learning rate [default: 0.001]')
parser.add_argument('--momentum', type=float, default=0.9, help='Initial learning rate [default: 0.9]')
parser.add_argument('--optimizer', default='adam', help='adam or momentum [default: adam]')
parser.add_argument('--decay_step', type=int, default=200000, help='Decay step for lr decay [default: 200000]')
parser.add_argument('--decay_rate', type=float, default=0.7, help='Decay rate for lr decay [default: 0.8]')
FLAGS = parser.parse_args()
BATCH_SIZE = FLAGS.batch_size
NUM_POINT = FLAGS.num_point
MAX_EPOCH = FLAGS.max_epoch
BASE_LEARNING_RATE = FLAGS.learning_rate
GPU_INDEX = FLAGS.gpu
MOMENTUM = FLAGS.momentum
OPTIMIZER = FLAGS.optimizer
DECAY_STEP = FLAGS.decay_step
DECAY_RATE = FLAGS.decay_rate
MODEL = importlib.import_module(FLAGS.model) # import network module
MODEL_FILE = os.path.join(BASE_DIR, 'models', FLAGS.model+'.py')
LOG_DIR = FLAGS.log_dir
if not os.path.exists(LOG_DIR): os.mkdir(LOG_DIR)
os.system('cp %s %s' % (MODEL_FILE, LOG_DIR)) # bkp of model def
os.system('cp train.py %s' % (LOG_DIR)) # bkp of train procedure
LOG_FOUT = open(os.path.join(LOG_DIR, 'log_train.txt'), 'w')
LOG_FOUT.write(str(FLAGS)+'\n')
MAX_NUM_POINT = 2048
NUM_CLASSES = 40
BN_INIT_DECAY = 0.5
BN_DECAY_DECAY_RATE = 0.5
BN_DECAY_DECAY_STEP = float(DECAY_STEP)
BN_DECAY_CLIP = 0.99
HOSTNAME = socket.gethostname()
# ModelNet40 official train/test split
TRAIN_FILES = provider.getDataFiles( \
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/train_files.txt'))
TEST_FILES = provider.getDataFiles(\
os.path.join(BASE_DIR, 'data/modelnet40_ply_hdf5_2048/test_files.txt'))
def log_string(out_str):
LOG_FOUT.write(out_str+'\n')
LOG_FOUT.flush()
print(out_str)
#日志记录函数
def get_learning_rate(batch):
learning_rate = tf.train.exponential_decay(
BASE_LEARNING_RATE, # Base learning rate.
batch * BATCH_SIZE, # Current index into the dataset.
DECAY_STEP, # Decay step.
DECAY_RATE, # Decay rate.
staircase=True)
learning_rate = tf.maximum(learning_rate, 0.00001) # CLIP THE LEARNING RATE!
#训练时学习率最好随着训练衰减,learning_rate最大取0.00001
return learning_rate
def get_bn_decay(batch):#Batch Normalization
bn_momentum = tf.train.exponential_decay(
BN_INIT_DECAY,
batch*BATCH_SIZE,
BN_DECAY_DECAY_STEP,
BN_DECAY_DECAY_RATE,
staircase=True)
bn_decay = tf.minimum(BN_DECAY_CLIP, 1 - bn_momentum)
return bn_decay
def train():
with tf.Graph().as_default():
with tf.device('/gpu:'+str(GPU_INDEX)):
pointclouds_pl, labels_pl = MODEL.placeholder_inputs(BATCH_SIZE, NUM_POINT)
is_training_pl = tf.placeholder(tf.bool, shape=())
print(is_training_pl)
# Note the global_step=batch parameter to minimize.
# That tells the optimizer to helpfully increment the 'batch' parameter for you every time it trains.
batch = tf.Variable(0)
bn_decay = get_bn_decay(batch)
tf.summary.scalar('bn_decay', bn_decay)#衰减
# Get model and loss
pred, end_points = MODEL.get_model(pointclouds_pl, is_training_pl, bn_decay=bn_decay)
loss = MODEL.get_loss(pred, labels_pl, end_points)
tf.summary.scalar('loss', loss)#代价
correct = tf.equal(tf.argmax(pred, 1), tf.to_int64(labels_pl))
accuracy = tf.reduce_sum(tf.cast(correct, tf.float32)) / float(BATCH_SIZE)
tf.summary.scalar('accuracy', accuracy)#精度
# Get training operator
learning_rate = get_learning_rate(batch)
tf.summary.scalar('learning_rate', learning_rate)
if OPTIMIZER == 'momentum':
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=MOMENTUM)
elif OPTIMIZER == 'adam':
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.minimize(loss, global_step=batch)
# Add ops to save and restore all the variables.
saver = tf.train.Saver()
# Create a session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.allow_soft_placement = True
config.log_device_placement = False
sess = tf.Session(config=config)
# Add summary writers
#merged = tf.merge_all_summaries()
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'train'),
sess.graph)
test_writer = tf.summary.FileWriter(os.path.join(LOG_DIR, 'test'))
# Init variables
init = tf.global_variables_initializer()
# To fix the bug introduced in TF 0.12.1 as in
# http://stackoverflow.com/questions/41543774/invalidargumenterror-for-tensor-bool-tensorflow-0-12-1
#sess.run(init)
sess.run(init, {is_training_pl: True})
ops = {'pointclouds_pl': pointclouds_pl,
'labels_pl': labels_pl,
'is_training_pl': is_training_pl,
'pred': pred,
'loss': loss,
'train_op': train_op,
'merged': merged,
'step': batch}
for epoch in range(MAX_EPOCH):
log_string('**** EPOCH %03d ****' % (epoch))
sys.stdout.flush()
train_one_epoch(sess, ops, train_writer)
eval_one_epoch(sess, ops, test_writer)
# Save the variables to disk.
if epoch % 10 == 0:
save_path = saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"))
log_string("Model saved in file: %s" % save_path)
#10个EPOCH一次save
def train_one_epoch(sess, ops, train_writer):
""" ops: dict mapping from string to tf ops """
is_training = True
# Shuffle train files
train_file_idxs = np.arange(0, len(TRAIN_FILES))
np.random.shuffle(train_file_idxs)
for fn in range(len(TRAIN_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TRAIN_FILES[train_file_idxs[fn]])
current_data = current_data[:,0:NUM_POINT,:]
#[楼层,行,列]
#所有楼层 num行 所有列元素传给current_data
current_data, current_label, _ = provider.shuffle_data(current_data, np.squeeze(current_label))
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
total_correct = 0
total_seen = 0
loss_sum = 0
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
# Augment batched point clouds by rotation and jittering
rotated_data = provider.rotate_point_cloud(current_data[start_idx:end_idx, :, :])
#调用provider中rotate_point_cloud
jittered_data = provider.jitter_point_cloud(rotated_data)
#调用provider中jitter_point_cloud
feed_dict = {ops['pointclouds_pl']: jittered_data,
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training,}
summary, step, _, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['train_op'], ops['loss'], ops['pred']], feed_dict=feed_dict)
#训练
train_writer.add_summary(summary, step)
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += loss_val
#log训练结果
log_string('mean loss: %f' % (loss_sum / float(num_batches)))
log_string('accuracy: %f' % (total_correct / float(total_seen)))
def eval_one_epoch(sess, ops, test_writer):
""" ops: dict mapping from string to tf ops """
is_training = False
total_correct = 0
total_seen = 0
loss_sum = 0
total_seen_class = [0 for _ in range(NUM_CLASSES)]
total_correct_class = [0 for _ in range(NUM_CLASSES)]
for fn in range(len(TEST_FILES)):
log_string('----' + str(fn) + '-----')
current_data, current_label = provider.loadDataFile(TEST_FILES[fn])
current_data = current_data[:,0:NUM_POINT,:]
current_label = np.squeeze(current_label)
file_size = current_data.shape[0]
num_batches = file_size // BATCH_SIZE
for batch_idx in range(num_batches):
start_idx = batch_idx * BATCH_SIZE
end_idx = (batch_idx+1) * BATCH_SIZE
feed_dict = {ops['pointclouds_pl']: current_data[start_idx:end_idx, :, :],
ops['labels_pl']: current_label[start_idx:end_idx],
ops['is_training_pl']: is_training}
summary, step, loss_val, pred_val = sess.run([ops['merged'], ops['step'],
ops['loss'], ops['pred']], feed_dict=feed_dict)
#估计
pred_val = np.argmax(pred_val, 1)
correct = np.sum(pred_val == current_label[start_idx:end_idx])
total_correct += correct
total_seen += BATCH_SIZE
loss_sum += (loss_val*BATCH_SIZE)
for i in range(start_idx, end_idx):
l = current_label[i]
total_seen_class[l] += 1
total_correct_class[l] += (pred_val[i-start_idx] == l)
#log估计结果
log_string('eval mean loss: %f' % (loss_sum / float(total_seen)))
log_string('eval accuracy: %f'% (total_correct / float(total_seen)))
log_string('eval avg class acc: %f' % (np.mean(np.array(total_correct_class)/np.array(total_seen_class,dtype=np.float))))
if __name__ == "__main__":
train()
LOG_FOUT.close()