基础理解
不同于卷积网络专门处理网格化数据,循环神经网络主要处理序列数据。比如一个句子:‘I went to Nepal in 2009’。每个word可以为序列的一个x。由于序列的长短不同,如果对每个x都单独设置一个参数,那么当出现更长的序列时模型就无法处理,没有对应的权重参数。而且对于序列‘I went to Nepal in 2009.’和’In 2009, I went to Nepal.'我们希望模型不管时间2009出现在序列的哪个位置都能处理,如果单独设置参数由于序列时间2009处在序列的不同位置,权重参数也不好对不同位置进行处理。因此出现了共享参数的方法,使得模型可以处理不同长度序列并可泛化。一种简单方法是在一维时间序列上使用卷积操作,但该方法比较浅层。
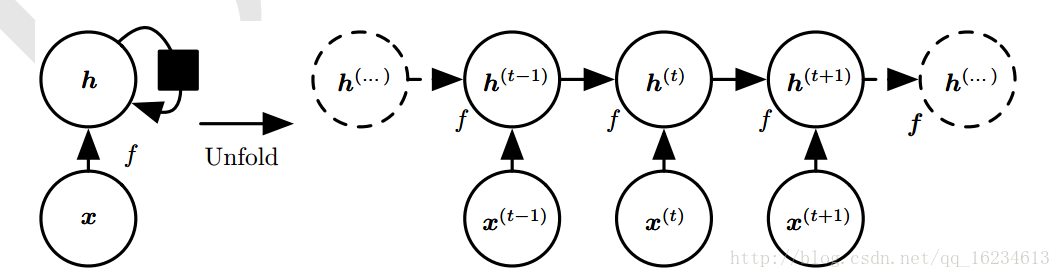
如上图,这是循环神经网络的简单形式。在不同时间段函数f的参数都相同,那我们不管在哪个时间t处将序列中的x时间2009输入,都会在原有状态h上新添加一个与x相关的相同输入。可以这样理解:
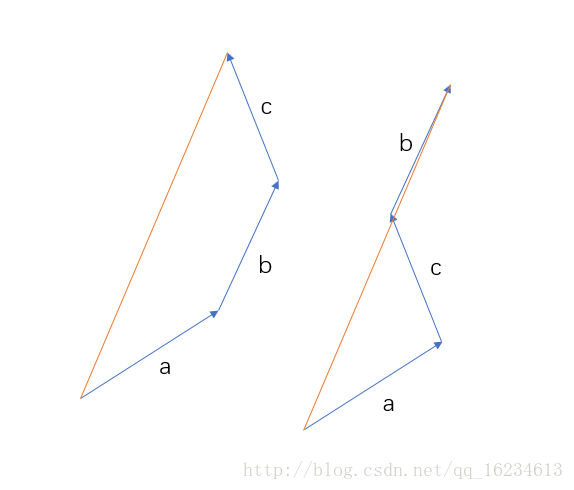
上图’a b c’和‘a c b’序列虽然排序不同,但最终产生的向量大小却是相同,在一定程度上表示’a b c’和‘a c b’二者含义近似。
因此循环神经网络具有以下优点:
1、不管序列长短(指所有x个数总和),都能具有相同的输入大小x(指单独x输入),只是在每输入一个x后状态就从上一个状态转移到下一个状态(每个x的特征向量组合)。而且将任意长度序列映射到固定长度特征向量,其信息是由一定损失的。
2、每个时间步使用相同转移函数f,参数共享,且能处理序列的乱序。
个人理解,其实不管卷积网络还是神经网络,本质是都是对原始数据集分布进行特征映射,将原始比较乱的数据分布,根据标记映射到另一个比较易于区分的分布上。从而实现可分性。
类似模型公式如下:
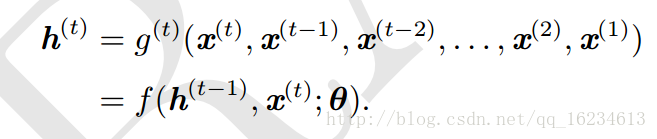
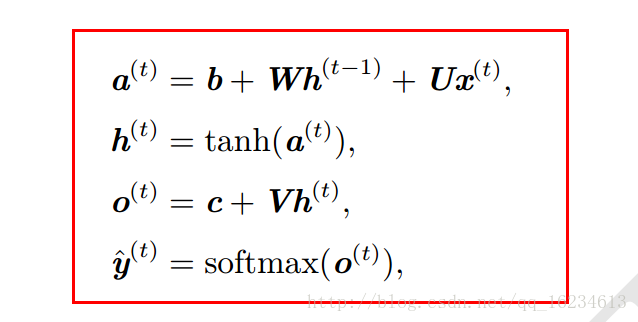

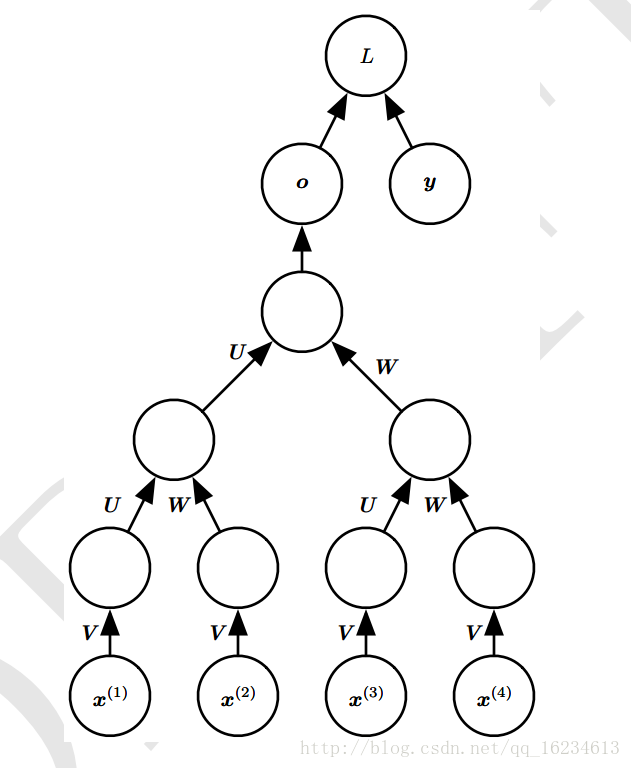
标准型
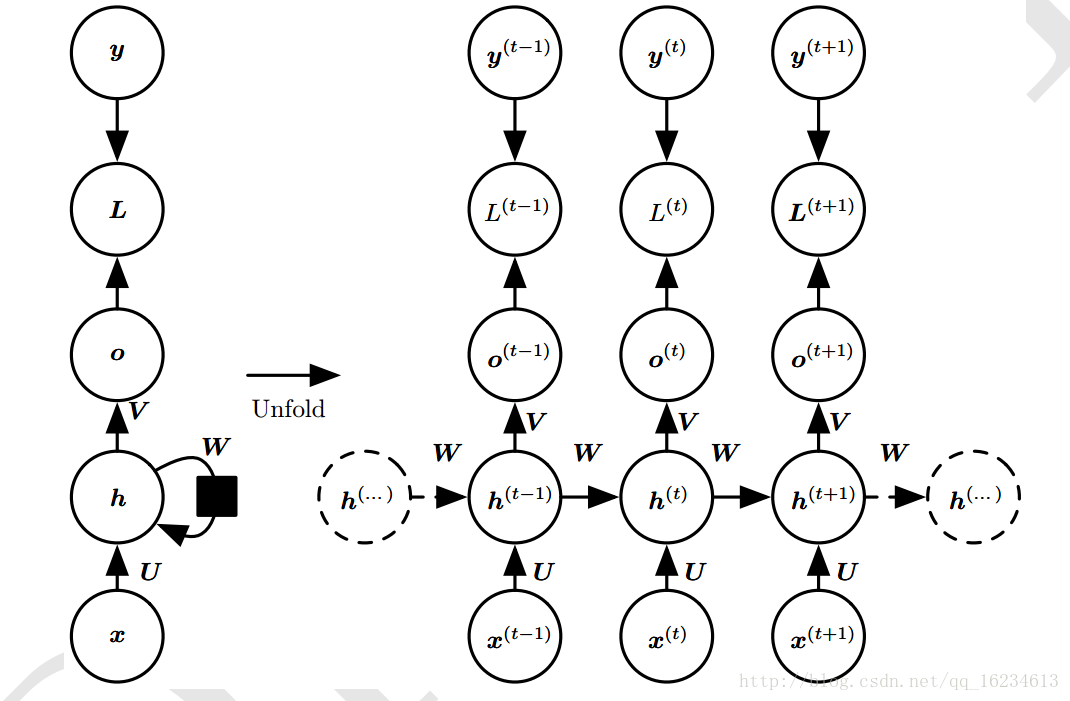
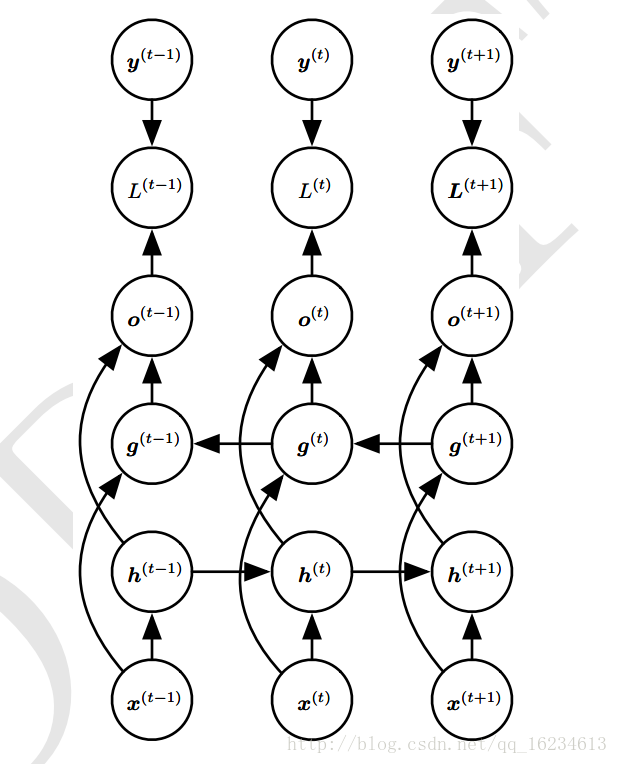
W V U为权重,o为输出,y为标记,x为输入,h为隐藏层状态。L为输入o与y的损失函数。上图每步都有输出o,且隐藏单元之间存在循环链接。
上图循环链接是从输出o到隐藏层h。没有上面的h到h模型强大。o作为输出,除非维度很高,否则会损失一部分h的信息。没有直接的循环链接,而只是间接的将h信息传递到下一层。但其易于训练,可以并行化训练。
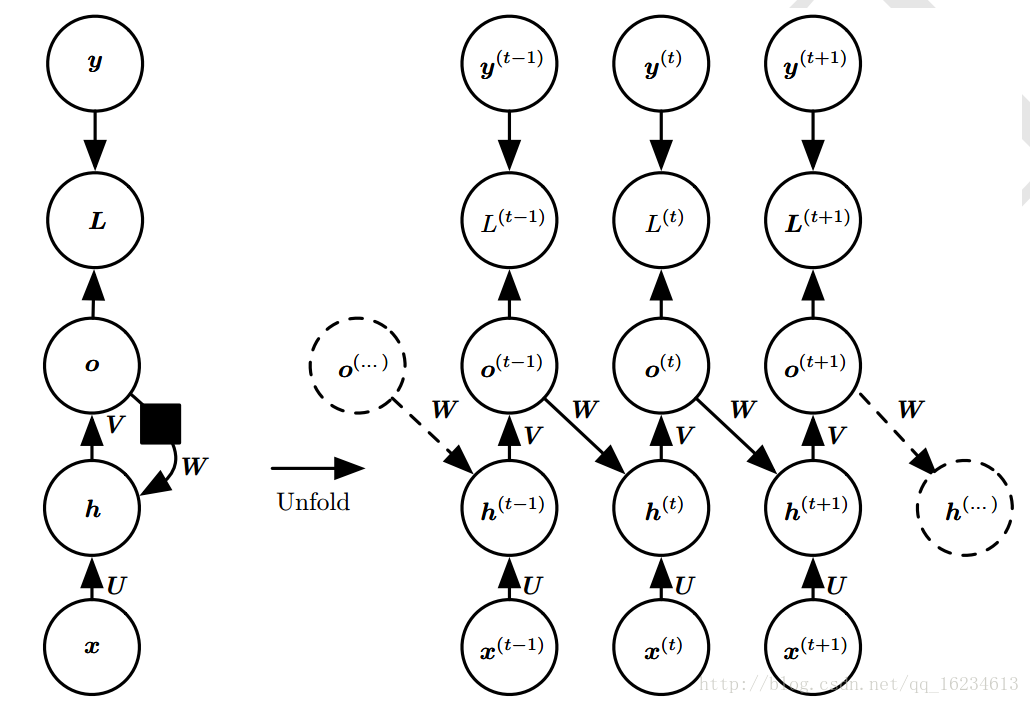
上模型只有一个固定长度的向量输出。而不像前面输出与输入序列相同长度输出序列。
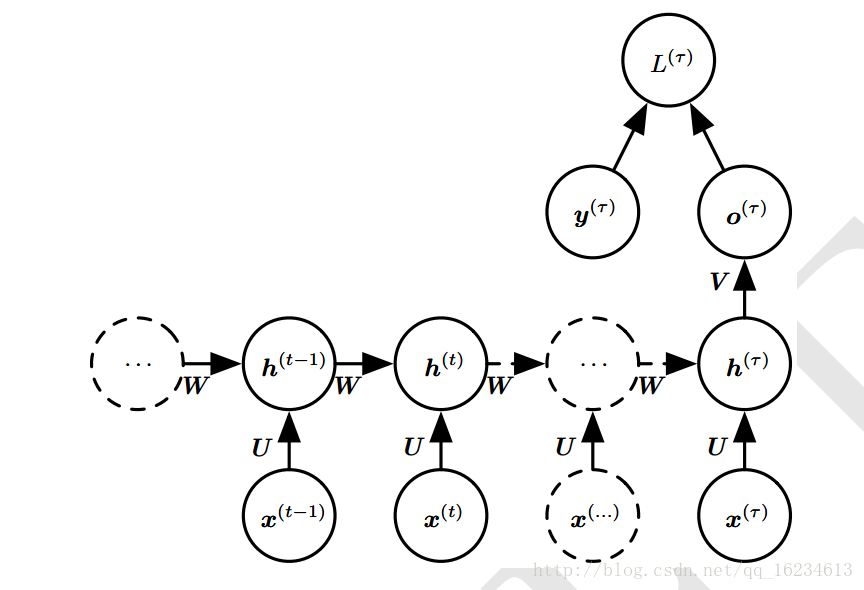
输出循环型
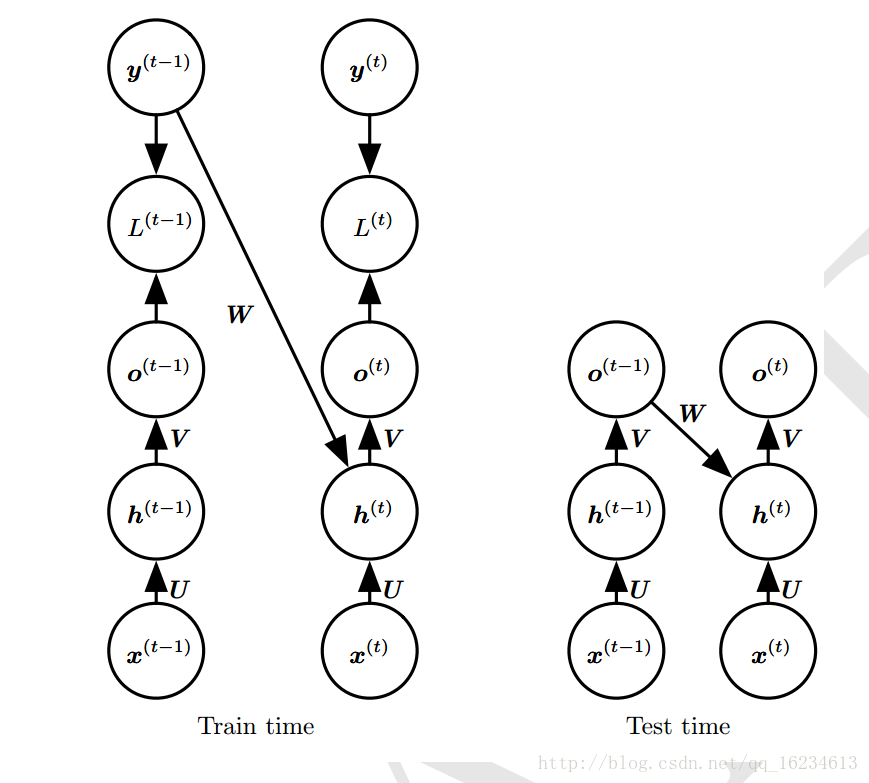
就是将输出作为循环链接。由于时间步的解耦,可以并行训练,使用导师驱动过程进行训练。
上图训练时标记y作为循环链接输入,测试时使用输出o作为循环链接输入。
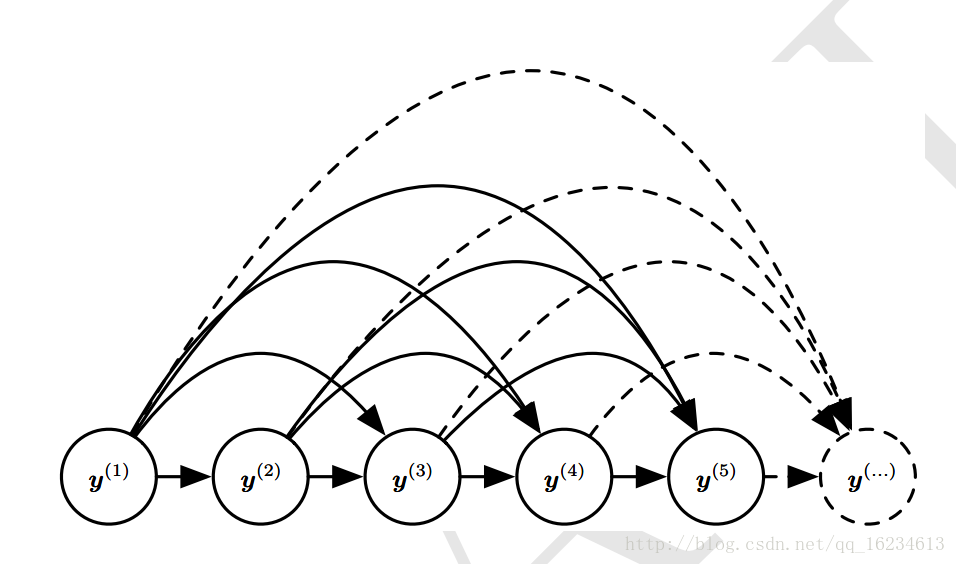
有向图型
没有x输入,只有y序列
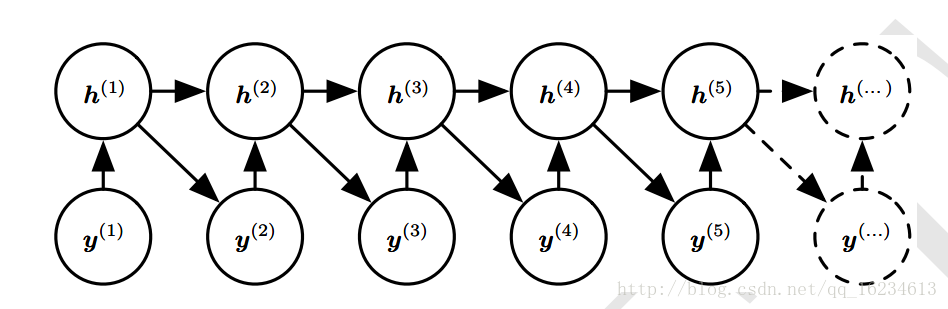
上下文型
依我理解,此处上下文指的是输出序列的上下文信息
上图主要用于图注,也就是x为图像,y为词序。通过输入图像x产生输出词序列。
将x作为一个额外输入方法:
1、作为初始状态h0
2、每个时间步输入一次
3、结合两种方式
在前面的基础上,添加一个输出y到h的链接。表明在给定x的序列后相同长度y序列上的分布建模。
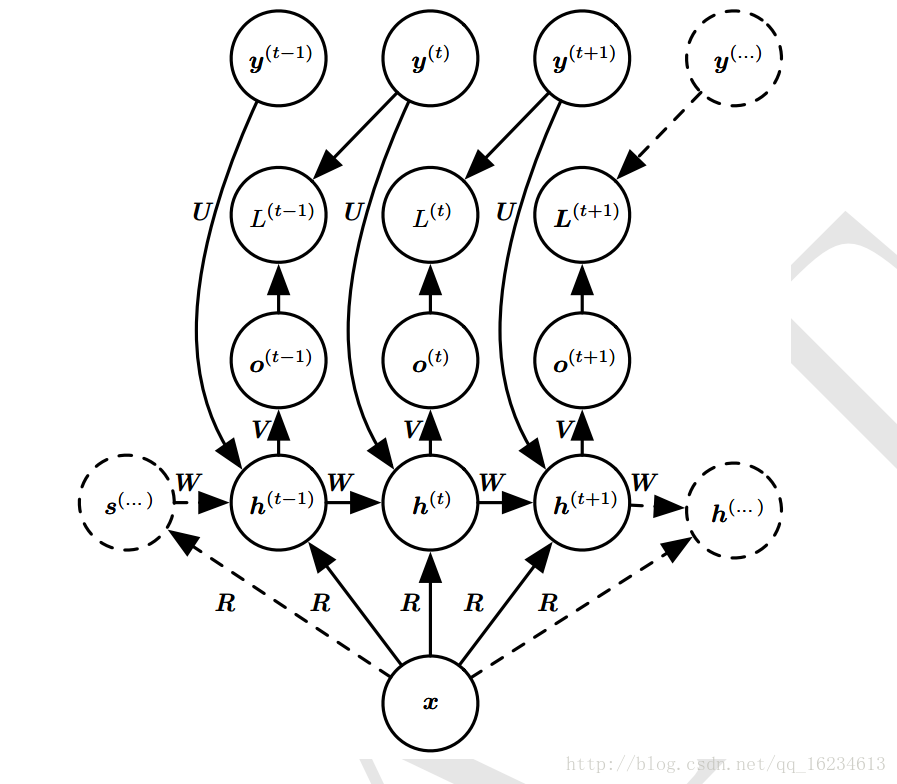
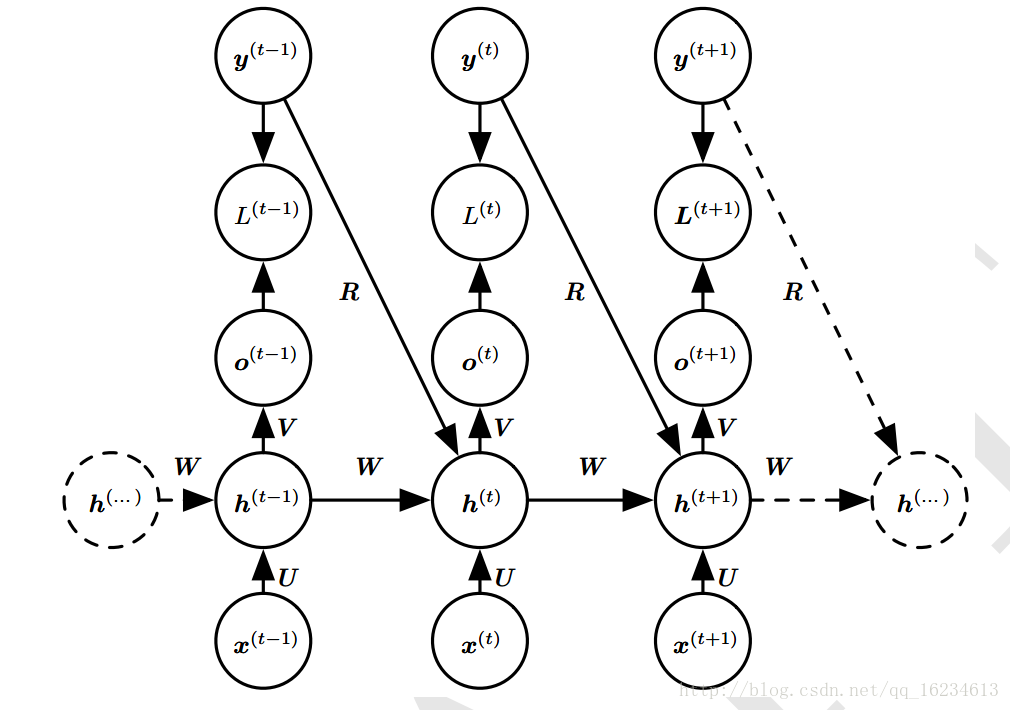
双向型
h状态不仅依赖过去信息,还依赖未来与之有关的敏感信息。常用于手写识别和语音识别。
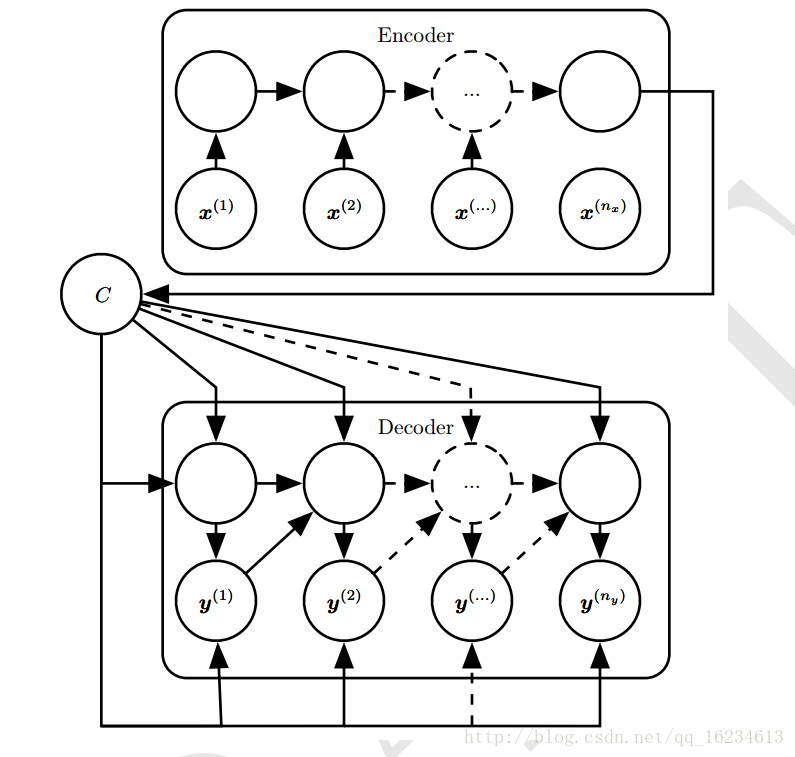
编码解码型
将输入序列x映射成不等长输出序列y。常用于语音识别,机器翻译,问答系统等。
C为上下文变量,编码器将输入序列编码成一个摘要C(其是就是将输入序列映射到了向量C上),再由解码器根据变量C输出输出序列。注意C的维度大小代表能够包含的信息量。
经典seq2seq模型:
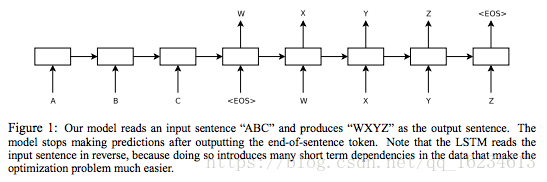
深度型
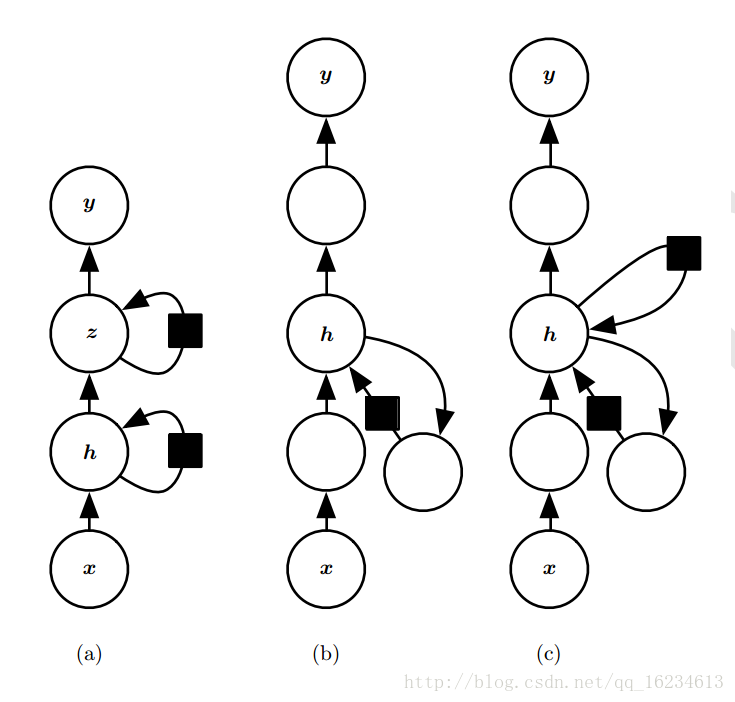
浅变换一般指MLP的单层(一个放射变换+一个非线性变化)。深度型增加模型深度,但增加深度有可能会因优化困难而影响模型效果。
图中第一个方法是增加循化组数量。第二个中空白圆圈表示增加更深的MLP层。第三个引入跳跃连接来缓解深度路径延长问题。
递归型
不再构造成RNN的链状结构,而是深的树状结构。一定程度避免长期依赖问题。对于固定长度L的序列,将深度由L低至logL。可用于学习推论。