人工神经网络介绍参考: https://blog.csdn.net/fengbingchun/article/details/50274471
卷积神经网络介绍参考: https://blog.csdn.net/fengbingchun/article/details/50529500
这里在以上两篇基础上整理介绍循环神经网络:
前馈网络可以分为若干”层”,各层按信号传输先后顺序依次排列,第i层的神经元只接受第(i-1)层神经元给出的信号,各神经元之间没有反馈。前馈型网络可用一有向无环路图表示。前馈神经网络用于处理有限的,定长的输入空间上的问题是很有优势的。使用越多的隐藏层节点就能学习到越多的信息,能更好的处理特定的任务。而循环神经网络(Recurrent Neural Networks, RNN)处理方式与前馈神经网络有着本质上的不同,循环神经网络只处理一个单一的输入单元和上一个时间点的隐藏层信息。这使得循环神经网络能够更加自由和动态的获取输入的信息,而不受到定长输入空间的限制。
传统神经网络对于声音类似的时间序列信号,由于网络的单向无反馈连接方式使得网络只能处理输入信号所包含时间段的信号,对于该信号所包含时间段以外的信号在处理本段信号时常没有任何参考,而常见时间序列信号都和它所在时间段前后时间区间的背景信号有着密切的联系。例如,对包含”早上好”语义的语音进行识别时,训练时同时用包含”早上好”的这段语音分别对传统神经网络和循环神经网络进行训练,在处理包含”好”所在的语音信号时,以往的神经网络不会参考包含”早”或者”上”的语音信号只能对网络输入语音信号”好”进行处理分析,而对于循环神经网络而言它会根据历史数据信息结合”好”语音所处的时间位置参考该时间位置前面的语音信号”早上”更加容易的识别出语义为”上”的语音信号。包含这种潜在能力的原因在于以往的前馈神经网络神经元仅为顺序连接,而循环神经网络存在神经元反馈连接,这种形式的连接使得网络能够以一种激励的形式存储最近时间段的输入数据信息(短时记忆),而网络的这种潜在意义在实际应用方面着广泛的意义。
RNN之所以称为循环神经网络,即”一个序列的当前输出与前面的输出也是有关的”。具体体现在后面层数的输入值要加入前面层的输出值,即隐藏层之间不再是不相连的而是有连接的。
一个多层感知机仅仅是将输入映射到输出向量,然而RNN原则上是将之前输入的整个历史映射到每个输出。所以与MLPs的全局逼近理论对应的是RNN拥有足够的隐藏节点个数可以以任意精度逼近任意可度量的序列到序列映射。环状连接最重要的特点是可以将之前的”记忆”保留在网络的中间状态,而这个状态会影响最终的网络输出。
RNN的前向传播和单个隐藏层的MLP基本是一样的,除了当前点的激活值是通过当前的输入和隐藏层在上一次激活值一起计算得到。
和标准的反向传播算法一样,循环神经网络中的反向传播算法(BackPropagation Through Time, BPTT)也需要不断的使用链式法则。微小的不同之处是对于循环网络,目标函数依赖的隐藏层激活值不仅将激活值传递到输出层,并且会影响下一个时间片段的隐藏层。
循环神经网络的定义:
循环神经网络的单个神经元模型如下图所示,与以往的神经元相比它包含了一个反馈输入,如果将其按照时间变化展开可以看到循环神经网络单个神经元类似一系列权值共享前馈神经元的依次连接,连接后同传统神经元相同随着时间的变化输入和输出会发生变化,但不同的是循环神经网络上一时刻神经元的”历史信息”会通过权值与下一时刻的神经元相连接,这样循环神经网络在t时刻的输入完成与输出的映射且参考了t之前所有输入数据对网络的影响,形成了反馈网络结构。虽然反馈结构的循环神经网络能够参考背景信号但常见的信号所需要参考的背景信息与目标信息时间相隔可能非常的宽泛,理论上循环神经网络可以参考距离背景信息任意范围的参考信息,但实际应用过程中对于较长时间间隔的参考信息通常无法参考。

对于上述问题主要在于网络训练时需要计算的网络代价函数梯度,而梯度计算与神经元之间连接的权值密切相关,在训练学习过程中很容易造成梯度爆炸或者梯度消失问题。常见的网络训练学习算法以反向传播算法或者实时递归学习算法为主,随着时间推移数据量逐步增大以及网络隐层神经元自身循环问题,这些算法的误差在按照时间反向传播时会产生指数增长或者消失问题。由于时间延迟越来越长从而需要参考的信号也越来越多,这样权值数量也会出现激增,最终,很小的误差经过大量的权值加和之后出现指数式增长,导致无法训练或者训练时间过长。而梯度消失问题指网络刚开始输入的具有参考价值的数据,随着时间变化新输入网络的数据会取代网络先前的隐层参数导致最初的有效信息逐步被”忘记”,如果以颜色深浅代表数据信息的有用程度,那么随着时间的推移数据信息的有用性将逐步被淡化。这两种问题都会导致网络的实际建模缺陷,无法参考时间间隔较远的序列状态,最终在与网络相关的分类识别类似的应用中仍旧无法获得好的实践效果。
一个最简单的循环神经网络如下图所示:这样的神经网络一共有3层,分别是输入层x,隐藏层h和输出层y。定义每一层的节点下标如下:k表示的是输出层的节点下标,j表示的是当前时间节点隐藏层的节点下标,l表示的是上一时间节点隐藏层的节点下标,i表示的是输入层的节点下标。
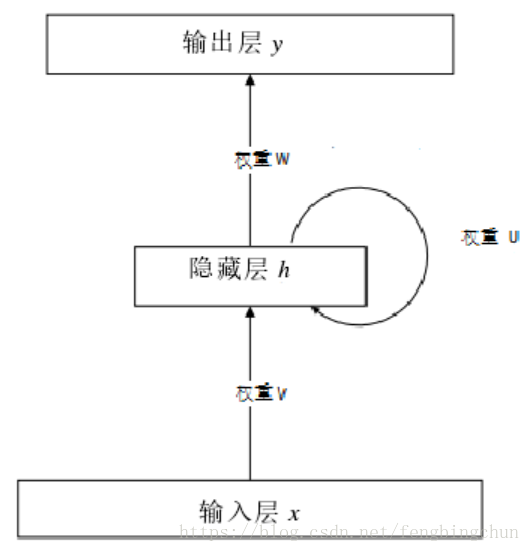
对于一个普通的单输入前馈神经网络来说,隐藏层某一时刻某一节点的激活netj(t)可以用公式表示:

其中,n表示的是输入层节点的个数,θj表示的是一个偏置参数,(t)表示的是t时间节点。但是在循环神经网络中,隐藏层在某一时刻某个节点的激活不再单单受到输入层的影响,也受到上一时刻的隐藏层状态的影响。隐藏层的节点状态被”循环”地利用与神经网络之中,这就组成了一个循环神经网络。如上图所示,这样隐藏层节点的激活netj(t)的计算方式被更新为:

其中,m表示的是隐藏层节点的总个数。f表示的是隐藏层节点的激活函数。对于一个神经网络来说,激活函数有多种选择,例如,sigmoid函数,tanh函数或者二值函数都是可选的激活函数。
对于输出层的激活计算循环神经网络与常见的前馈神经网络并没有太大的区别,都可以使用如下公式来计算:

其中g表示的是输出层节点的激活函数(可以与隐藏层节点的f是同一个激活函数)。
循环神经网络的训练:
当一个神经网络结构的每一个激活函数都是可导的并且整个网络的预先设计输出是可以获得时,该神经网络的训练可以通过反向传播算法(Back Propagation, BP)来学习。反向传播算法的基础是梯度下降优化法。对于任何一个需要优化的权重参数,计算它们关于优化目标函数的梯度并且根据梯度更新权重参数是反向传播算法的基本思想。
常用的优化目标函数有和方差函数(Summed Squard Error, SSE),交叉熵函数(Cross Entropy)等。这里以和方差函数为例,采用随机梯度下降法,分析循环神经网络的学习过程。和方差的目标函数一般形式如下所示:

随机梯度下降法是不处理所有的样本,每次只处理一个样本,针对一个样本就对这个神经网络进行一次更新,再读入下一个样本,依次循环来更新整个神经网络。
根据梯度下降算法的思想,所有的权重参数都需要被相应的负梯度乘以一个学习率(Learning Rate)的值更新,对于输出层与隐藏层之间的参数w,其更新值可以由以下公式表示:

其中α表示的是学习率。但是直接对于这个函数求导并不容易,在此我们先定义残差δ,来方便计算导数。对于输出层来说,残差的计算公式如下:

根据上述公式关于残差的计算,我们可以得到权重参数w中某一个节点的更新公式:

这样计算起来就会方便的多,同理对于隐藏层的节点,我们也可以计算它们的残差:

根据这个残差节点的公式,我们可以得到权重v的更新公式:

同理,对于循环部分的权重u,我们可以得到如下的更新公式:

一般而言,为了简化计算,会选择导数相对好求的函数作为激活函数以提升训练的效率。例如逻辑斯蒂函数(Logistic Function):

对于这样的一个激活函数,其求导就变得十分的方便,该函数的导数为g’(net)=g(net)(1-g(net))。
一般而言,训练之初循环神经网络是随机初始化的,而初始的输入隐藏层一般采用随机小实数向量或者是全相等小实数向量。
长短时间记忆单元:
为了解决循环神经网络在训练过程中的梯度问题,循环神经网络神经元在以往的循环神经元结构基础上进行改进,1997年由Hochreiter和Schmidhuber提出了一种称作长短时间记忆单元(Long Short-Term Memory,LSTM)的特殊结构循环神经网络,最终Graves对该结构进行了进一步改良和推广,获得了巨大成功。该网络结构基于梯度学习算法能够避免上述提及的梯度问题且对于存在噪声或不可压缩的输入序列数据依然可以参考时间间隔在1000 时间步长以上的数据信息。经过大量的实验结论证明LSTM网络已经解决了传统循环神经网络无法解决的问题,在蛋白质结构预测,语音识别及手写字符识别等常见研究方面取得了新的突破。
LSTM网络由一个一个的单元模块组成,每个单元模块一般包含一个或者多个反馈连接的神经元及三个乘法单元,正是由于这些乘法单元的存在我们可以用这些乘法单元实现数据是否输入、输出及遗忘摒弃。常用取值为’0’或’1’的输入门,输出门和遗忘门与对应数据相乘实现如下图所示,输入门控制是否允许输入信息输入到当前网络隐层节点中,如果门取值为’1’则输入门打开允许输入数据,相反若门取值为’0’,则输入门关闭不允许数据输入;输出门控制经过当前节点的数据是否传递给下一个节点,如果门取值为’1’,则当前节点的数据会传递给下一个节点,相反若门取值为’0’,则不传递该节点信息;遗忘门控制神经元是否摒弃当前节点所保存的历史时刻信息,该门通过一种称为”peephole”的连接方式和内部神经元相连这种连接方式可以提高LSTM在时间精度及计算内部状态相关研究的学习能力,若门取值为’1’则保留以往的历史信息,相反若门取值为’0’,则清除当前节点所保存的历史信息。除了多增加的三个信息输入控制门以外,模块内部的神经元连接方式也有所不同,线性性质的内部神经元以一个权值固定为1的循环自连接方式连接称为”Constant Error Carousel”(CEC),CEC连接保证了误差或梯度随着时间的传播不会发生消失现象。当没有新的输入或者误差信号进入神经元时,CEC的局部误差既不增长也不下降保持不变状态,最终能够在前向传播和反向传播时都能通过输入输出门保证不必要的信息进入到网络。对较远时间步长的信号参考而言,更远时间步长的有效数据信息可以通过各个门的组合开或关保存下来,而无效的数据信息可以被摒弃其对应的参数无需保存,最终前面提及的梯度消失问题得到遏制。例如,当有参考价值的有效信息出现时,我们打开输入门使有效数据可以输入,当有效数据输入网络后输入门再保持关闭状态,随着时间的推移如果输入门一直保持关闭状态,那么,网络新输入的数据将无法替换单元以前的激励输出,在任意时刻只要网络输出门打开该有效数据信息都可以随时参考,从而网络实现了时间距离步长更远的有效数据信息参考。

从以上的分析来看单个LSTM网络与最初的循环神经网络除了隐层的非线性单元被替换成为了记忆模块以外别的方面都非常相似,但LSTM网络内部隐层连接方面却有了非常大的变化。LSTM网络隐层由一系列具有循环连接的记忆单元模块所构成,这些记忆单元模块类似于计算机的内存芯片可以存储对应的状态信息,如下图所示,网络输入层和输出层节点个数都为3,图中各个记忆单元所包含的神经元个数取2,神经元输出与所有的控制门、所有的神经元输入及网络所有输出节点都保持全连接状态,网络输入层各个节点与各个神经元的输入及状态控制门都为全连接形式,此外网络输出层节点和输入层节点也有附加的快捷连接。网络各个单元通过如上所述的连接方式基本就可以构建成对应的LSTM网络,但是,各个网络之间因为应用范围不同还是有部分连接差异。

双向LSTM网络:
虽然以上提及的网络能够对数据点所在时刻的”历史”信息进行参考,但同时参考数据点所在时刻的”未来”信息更有利于我们分析数据。为了能对输入数据的背景信息更加有效的利用,一种沿着时间刻度前进和倒退的双向分离式网络结构被提出。假设每一层的网络都是一位专家,那么要合并两个专家的意见意味着他们的意见是相互关联的。实践证明Graves团队所改进的双方向结构LSTM网络输出确实与背景信息存在密切联系,且通过简单的线性或者对数合并算法就可以获得网络识别率的提高。
如下图所示,双向循环神经网络前向传播层和后向传播层相互分离,如果没有后向传播层那么该网络结构和我们最早提到的前馈网络结构完全相同。网络输入节点同时和前向后向传播单元连接,对于前向传播层而言,上一时刻的输出状态作为下一时刻的输入状态;对于后向传播层而言,上一时刻的输入为下一时刻的输出状态,最终,前向传播输出和输入同时输出到网络输出节点。对于这样的网络组成形式,我们在同一网络结构中,可以直接用两个相反时间方向的输入信息来减少代价函数的误差而不需要额外的算法处理”未来”数据信息,较前面提及的传统循环神经网络方法更为简便。虽然双向循环神经网络结构发生了很大的变化,但是网络隐层中的两个传播层之间仍然互不连接,单个隐层网络完全可以看作是前馈网络结构,若仍旧采用传统网络训练时的反向传播算法,由于传播方向不同,前向传播层和后向传播层的神经元状态及输出与以往相比将不能同时进行。此外,对于t = 1时的前向层和t = T时的后向传播层它们的初始状态必须在训练之前给出。所以,网络训练方面我们可以参考部分以往循环神经网络的训练算法,只是训练算法因网络结构改变有所增加。

2005年经过Graves等人的努力,完全参考双向循环神经网络结构的双向LSTM网络被引入到了语音识别领域,在TIMIT语音库相关的识别实验中超越了双向循环神经网络,多层感知机等传统网络的识别效果。除了识别效果有所提高外,相同结构下以LSTM替换循环网络神经元后,即使在普通配置的电脑运行环境下,双向LSTM网络仍然可以超越以往的网络训练时间达到最快的收敛速度,而前后背景信息参考后的充分权值微调是取得如此快训练时间的根本原因。
以传统语音识别中音素(声音的最小组成单位)分类识别为例,受识别方式的影响网络训练必须要对训练数据进行初步处理:在标签数据中将语音中每个音素所在语音中的具体位置范围给出(如:标签0 230 d,数字0和230代表音素d存在于语音的起始位置为0,结束位置为230的区间位置),必须声音和标签必须严格对齐才能进行训练,然而包含音素位置范围的语音数据常通过人工方式处理得到。为此我们引入与概率相关的CTC(Connectionist Temporal Classification)声音分类识别,其中Temporal Classification指的是对序列长度大于或等于其对应标签的信号进行分类。CTC解决声音和标签严格对应问题的方法为引入新标签,在识别输出时除了样本类别标签外,在标签集加入代表空白输出的空白标签类别。
CTC预测作为循环神经网络的最终输出部分主要包含softmax概率输出及概率解码两个部分,softmax概率输出部分用来计算每次网络输入信号所属标签的归属概率;概率解码用来计算所有信号输出标签的组合概率并结合该概率给出最终的输入信号的标签。
以上整理的内容主要摘自:
1. 《基于神经网络的篇章一致性建模》,2015年,硕论,哈尔滨工业大学
2. 《基于循环神经网络的声学车型识别研究》,2015年,硕论,西安电子科技大学
3. 《最少门结构的循环神经网络及其应用》,2016年,硕论,南京大学