之前学习了卷积神经网络(CNN),在这里再简单介绍一下卷积神经网络的原理。

一个典型的卷积神经网络为:
输入 -> 卷积 -> RelU -> 池化 -> RelU -> 卷积 -> ... -> 池化 -> 全连接层 -> 输出
对于CNN来说,并不是所有上下层神经元都能直接相连,而是通过“卷积核”作为中介。而通过max pooling等操作可以进一步提高鲁棒性。CNN不仅可以用于图像识别,也可以用于语音识别等领域。
在CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立,因此又被称为前向神经网络(Feed-forward Neural Networks)。CNN和DNN的缺陷在于,仅适合处理固定维度的输入及输出。DNN和CDD不适合解决不固定长度的序列问题。例如:机器翻译就是一个序列问题。RNN的优势在于,适合处理序列问题。
RNN
在RNN中,神经元的输出可以在下一时刻直接作用到自身,即第i层神经元在m时刻的输入,除了(i-1)层神经元在该时刻的输入外,还包括其自身在(m-1)时刻的输出。将RNN展开,我们得到如下图所示的关系:
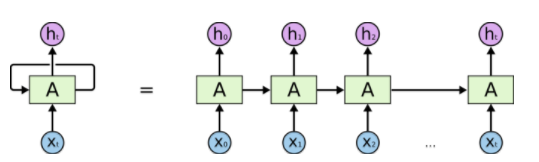
循环神经网络的这种结构非常适合处理前后有依赖关系的数据样本。由于这种链式的结构,循环神经网络与序列和列表紧密相连。因此,RNN适合处理基于时间的序列,例如:一段连续的语音,一段连续的手写文字。以语言模型为例,根据给定句子中的前t个字符,然后预测第t+1个字符。假设我们的句子是“你好世界”,使用前馈神经网络来预测:在时间1输入“你”,预测“好”,时间2向同一个网络输入“好”预测“世”。整个过程如下图所示:

我们可以根据前n个字符预测第t+1个字符。在这里,n=1。我们可以增大n来使得输入含有更多信息。但是我们不能任意增大n,因为这样通常会增在模型的复杂度,从而导致需要大量数据和计算来训练模型。

LSTM
RNN也有梯度消失的问题,因此很难处理长序列的序列。LSTM是一种特殊的RNN,能够解决长期依赖的问题,避免常规RNN的梯度消失。LSTM是长短时记忆单元,具有长期记住信息的特性。
在标准RNN中,重复模块具有简单的结构,例如单tanh层,如下图所示:
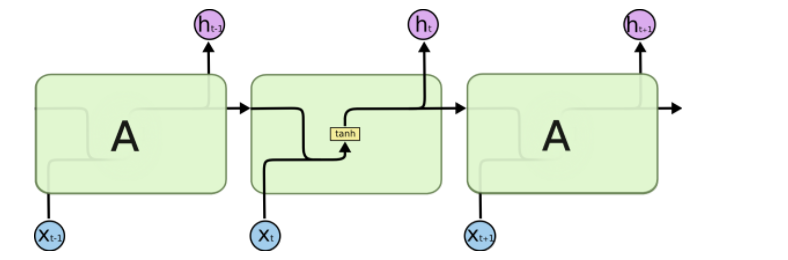
h(t)一方面用于当前层的模型损失计算,一方面用于下一层h(t+1)计算。
LSTM的结构比RNN的复杂得多,如下图所示:
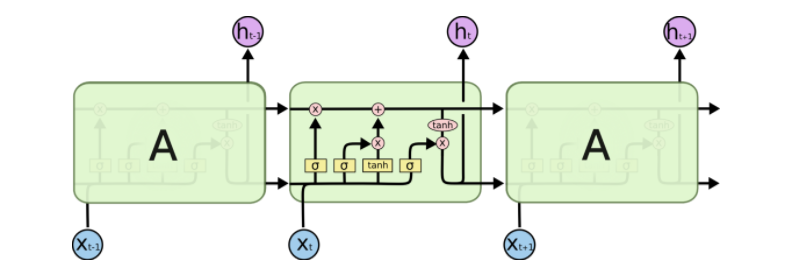
LSTM的关键是细胞状态,即贯穿图表顶部的水平线。

LSTM为细胞状态移除或者增加信息,这种精心设计的结构叫做门。LSTM有三种门结构。
1、遗忘门
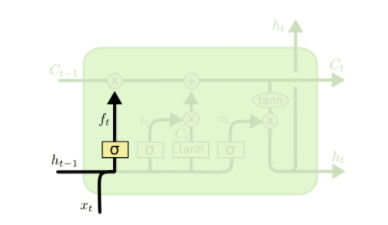
顾名思义,遗忘门决定丢掉细胞状态的哪些信息。根据h(t-1)和x(t),遗忘门为状态C(t-1)输出一个介于0到1之间的数字,0表示“完全丢弃”,1表示”完全接受“。数学表达式为:

2、输入门
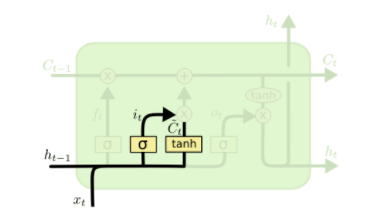
输入门由两个部分构成:第一部分为sigmoid激活函数,输出为i(t),决定更新哪些值;第二部分为tanh激活函数,输出为~C(t)。i(t)与~C(t)相乘后的结果用于更新细胞状态,数学表达式为:

3、输出门
经过遗忘门和输入门,细胞状态更新为:
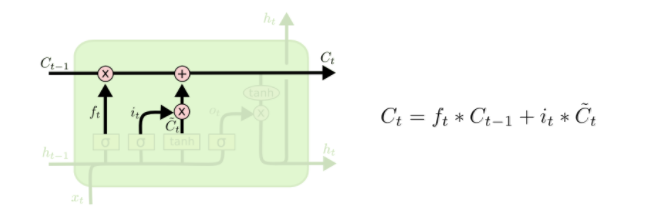
最后,我们应该决定输出是什么。输出基于上述细胞状态,但是需要过滤。输出门如下图所示:

首先,我们使用sigmoid层决定输出细胞状态的哪些部分。然后,我们令细胞状态通过tanh层,输出结果与sigmoid层的输出结果相乘。数学公式为:

LSTM的前向传播算法
(1)更新遗忘门输出:
(2)更新输入门输出:
(3)更新细胞状态:
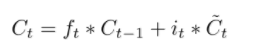
(4)更新输出门输出:
其他参考
有一篇博客具体讨论了LSTM的详细过程【深度学习】包教包会LSTM