梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正。
下面的h(x)是要拟合的函数,J(theta)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的记录条数,j是参数的个数。
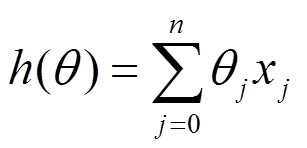
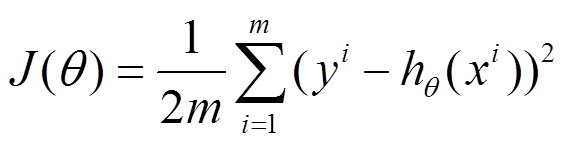
1、批量梯度下降的求解思路如下:
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度
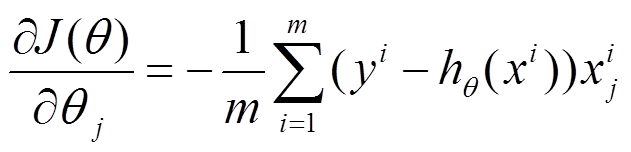
(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta
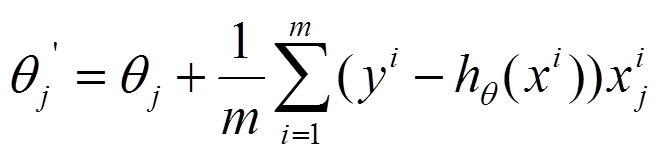
(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
2、随机梯度下降的求解思路如下:
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:
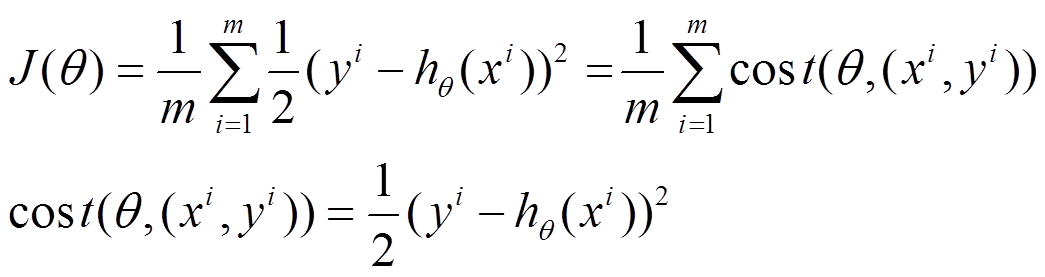
(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta
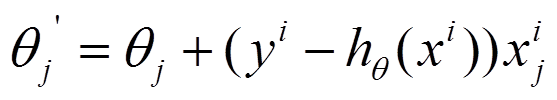
(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
3、对于上面的linear regression问题,与批量梯度下降对比,随机梯度下降求解的会是最优解吗?
(1)批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。
(2)随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
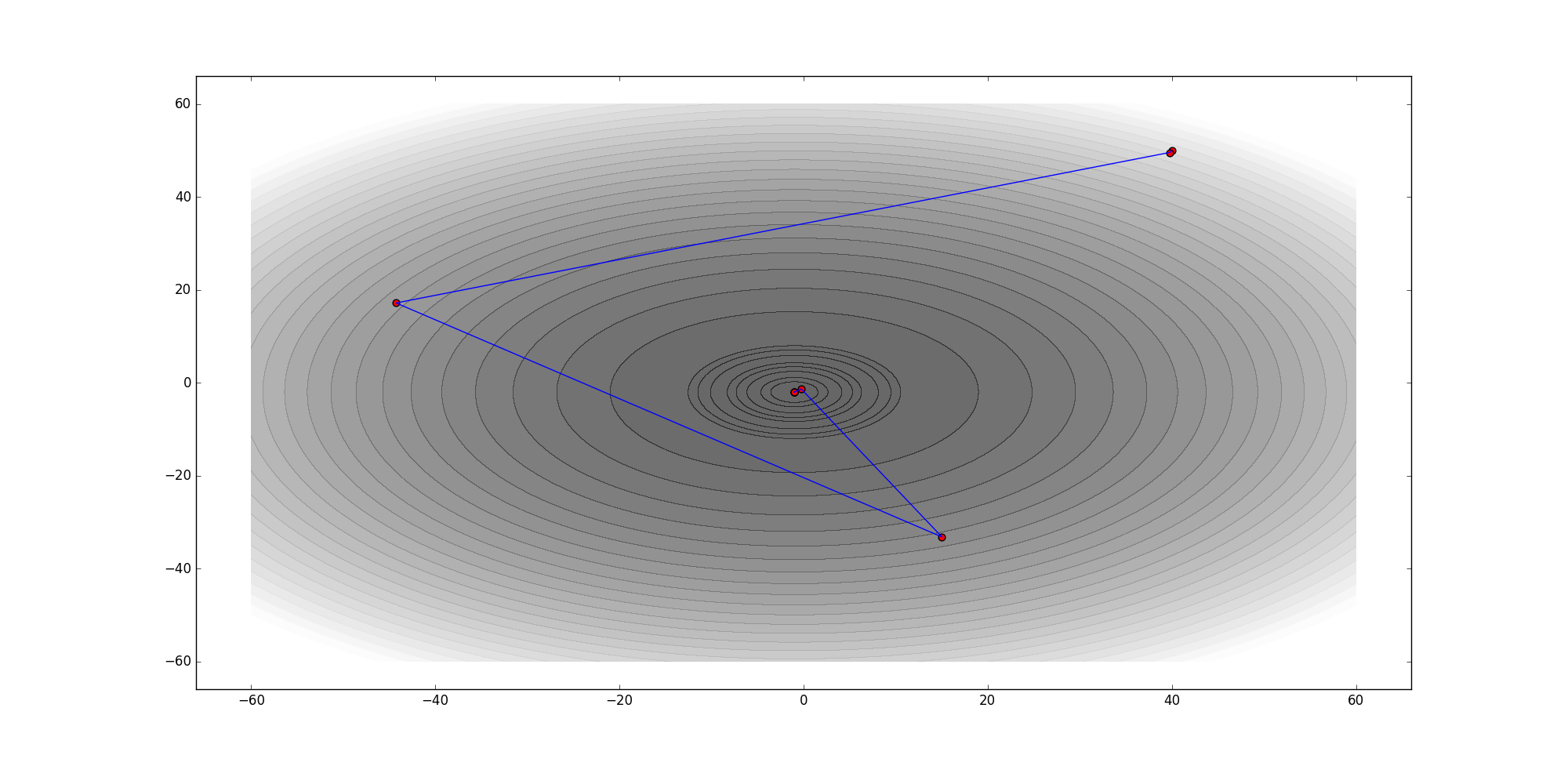
4、梯度下降用来求最优解,哪些问题可以求得全局最优?哪些问题可能局部最优解?
对于上面的linear regression问题,最优化问题对theta的分布是unimodal,即从图形上面看只有一个peak,所以梯度下降最终求得的是全局最优解。然而对于multimodal的问题,因为存在多个peak值,很有可能梯度下降的最终结果是局部最优。
5、随机梯度和批量梯度的实现差别
以前一篇博文中NMF实现为例,列出两者的实现差别(注:其实对应Python的代码要直观的多,以后要练习多写python!)
[java] view plain copy
- // 随机梯度下降,更新参数
- public void updatePQ_stochastic(double alpha, double beta) {
- for (int i = 0; i < M; i++) {
- ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
- for (Feature Rij : Ri) {
- // eij=Rij.weight-PQ for updating P and Q
- double PQ = 0;
- for (int k = 0; k < K; k++) {
- PQ += P[i][k] * Q[k][Rij.dim];
- }
- double eij = Rij.weight - PQ;
- // update Pik and Qkj
- for (int k = 0; k < K; k++) {
- double oldPik = P[i][k];
- P[i][k] += alpha
- * (2 * eij * Q[k][Rij.dim] - beta * P[i][k]);
- Q[k][Rij.dim] += alpha
- * (2 * eij * oldPik - beta * Q[k][Rij.dim]);
- }
- }
- }
- }
- // 批量梯度下降,更新参数
- public void updatePQ_batch(double alpha, double beta) {
- for (int i = 0; i < M; i++) {
- ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
- for (Feature Rij : Ri) {
- // Rij.error=Rij.weight-PQ for updating P and Q
- double PQ = 0;
- for (int k = 0; k < K; k++) {
- PQ += P[i][k] * Q[k][Rij.dim];
- }
- Rij.error = Rij.weight - PQ;
- }
- }
- for (int i = 0; i < M; i++) {
- ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
- for (Feature Rij : Ri) {
- for (int k = 0; k < K; k++) {
- // 对参数更新的累积项
- double eq_sum = 0;
- double ep_sum = 0;
- for (int ki = 0; ki < M; ki++) {// 固定k和j之后,对所有i项加和
- ArrayList<Feature> tmp = this.dataset.getDataAt(i).getAllFeature();
- for (Feature Rj : tmp) {
- if (Rj.dim == Rij.dim)
- ep_sum += P[ki][k] * Rj.error;
- }
- }
- for (Feature Rj : Ri) {// 固定k和i之后,对多有j项加和
- eq_sum += Rj.error * Q[k][Rj.dim];
- }
- // 对参数更新
- P[i][k] += alpha * (2 * eq_sum - beta * P[i][k]);
- Q[k][Rij.dim] += alpha * (2 * ep_sum - beta * Q[k][Rij.dim]);
- }
- }
- }
- }
1.牛顿法
在上一节中我们发现,如果在移动的步长中考虑了误差函数的二阶导数,误差函数收敛的速度非常快。其实已经不能看做步长了,因为梯度下降法中的步长指的是沿着梯度方向走多远的距离,而那个神奇的方法的迭代公式是:
只不过我们令罢了。我们发现自变量的移动方向已经不是梯度方向了,而是一个“修正”的梯度方向——牛顿方向。
这一公式的严格推导是这样的:若误差函数在二阶导数连续,将在处作Talor展开:
令,得到: 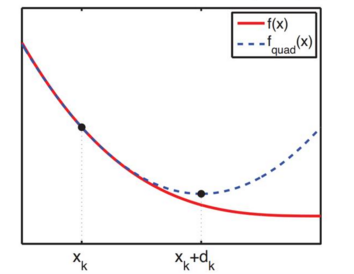
牛顿法的实质是在当前位置,使用二次函数来逼近拟合误差函数,认为二次函数的最低点就是误差函数的最低点,在误差函数为严格凹的条件下,,保证向误差下降的方向移动,这样反复迭代,就是在逼近真实的最低点。
上面的公式描述的是一维情况,推广到高维情况公式如下:
即用梯度代替一阶导数,Hessian阵代替二阶导数。
2.牛顿法的问题
一旦出现了Hessian阵的逆,一个随之而来的问题就是当前的Hessian阵是否是可逆的。这是牛顿法一个很大的问题。
另一个不容易注意到的问题是,Hessian阵是否是一个正定阵,如果Hessian阵是一个负定阵,算法就是在向一个错误的方向收敛。
第三个问题是求解矩阵的逆是一个时间复杂度的问题,所以这会成为一个限制求解速度的瓶颈。
由于这三个问题的存在,牛顿法并不是一个好的优化方法,那么大家自然想到了能不能找到一个严格正定且可逆的阵来近似这个Hessian阵的逆矩阵呢?
3.拟牛顿方法:DFP
我们再来写一次上面Talor展开的高维版本。记误差函数的梯度为,海森阵为,那么在处的Talor展开如下:
等式两边求导得:
令,即上一轮迭代的点,得:
这里的简写记号代表。
我们把最后一个式子简写为:
我们之前谈过,计算一个矩阵的逆是非常耗费时间的,我们不想去计算,而想找到它的一个迭代公式,可以猜想这个公式如下:
其中是上次迭代使用的矩阵,是两个列向量,是两个未知的比例系数。
结合上一个公式,构造一个方程组:
如果说下面两个等式成立:
等式(1)就肯定成立。
通过在方程组(2)中比对系数发现,如果令:
系数就必须等于:
该等式中可以写成分数形式且可消去的原因是是一个实数。
经过这个推导发现,只要按照(3)(4)来设置列向量和系数,方程组(0)就一定成立。有矩阵的迭代公式如下:
有了迭代公式,我们把初始的设置成单位阵,把每次的迭代值作为该点处Hessian矩阵逆矩阵的近似,如此就不需要计算矩阵的逆,所以这就是一个不错的近似方法。
4.拟牛顿方法:BFGS
由DFP的迭代公式:
互换和,得:
接下来如何求海森阵的逆呢?
根据公式:若是阶可逆矩阵,和是维列向量,且,则:
在(5)式中应用两次公式,便可以得到方法矩阵的迭代公式
下面是DFP方法的Python代码:
梯度下降和拟牛顿法是近似计算中非常重要的两种优化方法,在机器学习中有非常广泛的应用,可以在不丧失太多精确性的条件下快速得到最优解。