优化算法是机器学习中的一个重要内容。
其主要包括梯度下降法(Gradient Descent),牛顿法(Newton),拟牛顿法(Quasi-Newton)。其中拟牛顿法又包括DFP,BFGS,LBFGS。
下面实现的优化算法实例主要参考https://blog.csdn.net/itplus/article/details/21896453。
选取的优化函数是Rosenbrock函数,它是一个用来测试最优化算法性能的非凸函数。参考https://baike.baidu.com/item/Rosenbrock%E5%87%BD%E6%95%B0/22781931?fr=aladdin。其图形如下所示:
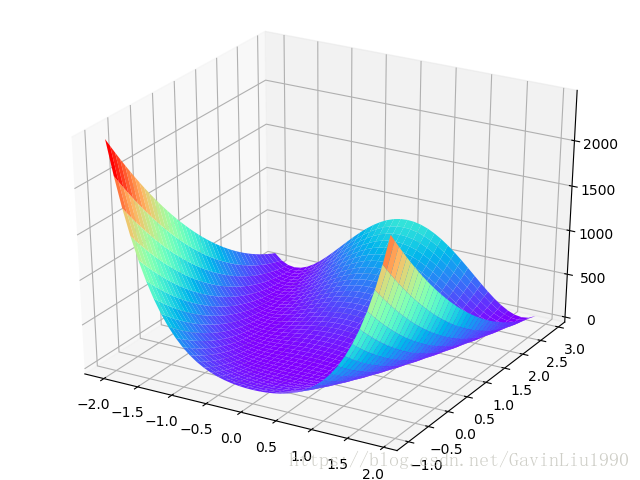
代码如下:
import os
import sys
import math
import numpy as np
####################################gd(梯度下降法)#################################################
lr = 0.001 #学习率
iteration = 0 #迭代次数
max_iteration = 100000 #最大迭代次数
x_old = np.zeros((2,1), dtype=np.float32) #x初始点的值,大小2*1
x_old = np.mat(x_old)
y_old = (1-x_old[0,0])**2 + 100*(x_old[1,0]-x_old[0,0]**2)**2 #y初始值,实数值
grad_old = [[-2*(1-x_old[0,0]) - 400*x_old[0,0]*(x_old[1,0]-x_old[0,0]**2)] ,
[200*(x_old[1,0]-x_old[0,0]**2)]] #x初始点的梯度值,大小2*1
grad_old = np.mat(grad_old)
while(1):
x_new = x_old - lr*grad_old #x更新点的值,大小2*1
y_new = (1-x_new[0,0])**2 + 100*(x_new[1,0]-x_new[0,0]**2)**2 #y更新值,实数值
grad_new = [[-2*(1-x_new[0,0]) - 400*x_new[0,0]*(x_new[1,0]-x_new[0,0]**2)] ,
[200*(x_new[1,0]-x_new[0,0]**2)]] #x更新点的梯度值,大小2*1
grad_new = np.mat(grad_new)
iteration += 1
if abs(y_new) < 0.001 or iteration > max_iteration: #停止迭代的条件
break
else:
x_old = x_new #把x当前点,作为旧点,来准备下一轮迭代
y_old = y_new
grad_old = grad_new #把x当前点的梯度值,作为旧点的梯度值,来准备下一轮迭代
print('梯度下降法')
print('x: ' + str(x_new.T))
print('y: ' + str(y_new))
print('迭代 ' + str(iteration) + ' 次')
print('\n')
###################################newton(牛顿法)#################################################
iteration = 0 #迭代次数
max_iteration = 100000 #最大迭代次数
x_old = np.zeros((2,1), dtype=np.float32)
x_old = np.mat(x_old) #x初始点的值,大小2*1
y_old = (1-x_old[0,0])**2 + 100*(x_old[1,0]-x_old[0,0]**2)**2 #y初始值,实数值
grad_old = [[-2*(1-x_old[0,0]) - 400*x_old[0,0]*(x_old[1,0]-x_old[0,0]**2)] ,
[200*(x_old[1,0]-x_old[0,0]**2)]] #x初始点的梯度值,大小2*1
grad_old = np.mat(grad_old)
hessian_old = [[2-400*x_old[1,0]+1200*x_old[0,0]**2 , -400*x_old[0,0]],
[-400*x_old[0,0] , 200]] #x初始点的海森矩阵,大小2*2
hessian_old = np.mat(hessian_old)
hessian_inverse_old = hessian_old.I #x初始点的海森矩阵的逆,大小2*2
while(1):
x_new = x_old - hessian_inverse_old*grad_old #x更新点的值,大小2*1
y_new = (1-x_new[0,0])**2 + 100*(x_new[1,0]-x_new[0,0]**2)**2 #y更新值,实数值
grad_new = [[-2*(1-x_new[0,0]) - 400*x_new[0,0]*(x_new[1,0]-x_new[0,0]**2)] ,
[200*(x_new[1,0]-x_new[0,0]**2)]] #x更新点的梯度值,大小2*1
grad_new = np.mat(grad_new)
hessian_new = [[2-400*x_new[1,0]+1200*x_new[0,0]**2 , -400*x_new[0,0]],
[-400*x_new[0,0] , 200]] #x更新点的海森矩阵,大小2*2
hessian_new = np.mat(hessian_new)
hessian_inverse_new = hessian_new.I #x更新点的海森矩阵的逆,大小2*2
iteration += 1
if abs(y_new) < 0.001 or iteration > max_iteration: #停止迭代的条件
break
else:
x_old = x_new #把x当前点,作为旧点,来准备下一轮迭代
y_old = y_new
grad_old = grad_new #把x当前点的梯度值,作为旧点的梯度值,来准备下一轮迭代
hessian_old = hessian_new
hessian_inverse_old = hessian_inverse_new #把x当前点的海森矩阵的逆,作为旧点的梯度值,来准备下一轮迭代
print('牛顿法')
print('x: ' + str(x_new.T))
print('y: ' + str(y_new))
print('迭代 ' + str(iteration) + ' 次')
print('\n')
#######################quasi_newton_dfp(拟牛顿法之DFP)#################################################
iteration = 0 #迭代次数
max_iteration = 100000 #最大迭代次数
x_old = np.zeros((2,1), dtype=np.float32)
x_old = np.mat(x_old) #x初始点的值,大小2*1
y_old = (1-x_old[0,0])**2 + 100*(x_old[1,0]-x_old[0,0]**2)**2 #y初始值,实数值
grad_old = [[-2*(1-x_old[0,0]) - 400*x_old[0,0]*(x_old[1,0]-x_old[0,0]**2)] ,
[200*(x_old[1,0]-x_old[0,0]**2)]] #x初始点的梯度值,大小2*1
grad_old = np.mat(grad_old)
D_old = np.eye(2, dtype=np.float32) #x初始点的D矩阵(海森矩阵的逆的近似矩阵),大小2*2的单位矩阵
D_old = np.mat(D_old)
d_old = - D_old * grad_old #x初始点的更新方向
while(1):
x_new = x_old + d_old #x更新点的值,大小2*1
y_new = (1-x_new[0,0])**2 + 100*(x_new[1,0]-x_new[0,0]**2)**2 #y更新值,实数值
grad_new = [[-2*(1-x_new[0,0]) - 400*x_new[0,0]*(x_new[1,0]-x_new[0,0]**2)] ,
[200*(x_new[1,0]-x_new[0,0]**2)]] #x更新点的梯度值,大小2*1
grad_new = np.mat(grad_new)
grad_delta = grad_new - grad_old #x更新点与旧点梯度值的差值,大小2*1
D_new = D_old + (d_old * d_old.T)/(d_old.T * grad_delta) - (D_old * grad_delta * grad_delta.T * D_old)/(grad_delta.T * D_old * grad_delta) #x更新点的D矩阵(海森矩阵的逆的近似矩阵),大小2*2
d_new = -D_new * grad_new #x更新点的更新方向
iteration += 1
if abs(y_new) < 0.001 or iteration > max_iteration: #停止迭代的条件
break
else:
x_old = x_new #把x当前点,作为旧点,来准备下一轮迭代
y_old = y_new
grad_old = grad_new #把x当前点的梯度值,作为旧点的梯度值,来准备下一轮迭代
D_old = D_new
d_old = d_new #把x当前点的更新方向,作为旧点的更新方向,来准备下一轮迭代
print('拟牛顿法之DFP')
print('x: ' + str(x_new.T))
print('y: ' + str(y_new))
print('迭代 ' + str(iteration) + ' 次')
print('\n')
#################################quasi_newton_bfgs(拟牛顿法之BFGS)#################################################
iteration = 0 #迭代次数
max_iteration = 100000 #最大迭代次数
danweijvzhen = np.eye(2, dtype=np.float32) #单位矩阵,大小2*2
danweijvzhen = np.mat(danweijvzhen)
x_old = np.zeros((2,1), dtype=np.float32) #x初始点的值,大小2*1
x_old = np.mat(x_old)
y_old = (1-x_old[0,0])**2 + 100*(x_old[1,0]-x_old[0,0]**2)**2 #y初始值,实数值
grad_old = [[-2*(1-x_old[0,0]) - 400*x_old[0,0]*(x_old[1,0]-x_old[0,0]**2)] ,
[200*(x_old[1,0]-x_old[0,0]**2)]] #x初始点的梯度值,大小2*1
grad_old = np.mat(grad_old)
D_old = np.eye(2, dtype=np.float32) #x初始点的D矩阵(海森矩阵的逆的近似矩阵),大小2*2的单位矩阵
D_old = np.mat(D_old)
d_old = - D_old * grad_old #x初始点的更新方向
while(1):
x_new = x_old + d_old #x更新点的值,大小2*1
y_new = (1-x_new[0,0])**2 + 100*(x_new[1,0]-x_new[0,0]**2)**2 #x更新点的值,大小2*1
grad_new = [[-2*(1-x_new[0,0]) - 400*x_new[0,0]*(x_new[1,0]-x_new[0,0]**2)] ,
[200*(x_new[1,0]-x_new[0,0]**2)]] #x更新点的梯度值,大小2*1
grad_new = np.mat(grad_new)
grad_delta = grad_new - grad_old #x更新点与旧点梯度值的差值,大小2*1
D_new = (danweijvzhen - (d_old * grad_delta.T)/(grad_delta.T * d_old)) * D_old * (danweijvzhen - (grad_delta * d_old.T)/(grad_delta.T * d_old)) + (d_old * d_old.T)/(grad_delta.T * d_old) #x更新点的D矩阵(海森矩阵的逆的近似矩阵),大小2*2
d_new = -D_new * grad_new #x初始点的更新方向
iteration += 1
if abs(y_new) < 0.001 or iteration > max_iteration:
break
else:
x_old = x_new #把x当前点,作为旧点,来准备下一轮迭代
y_old = y_new
grad_old = grad_new #把x当前点的梯度值,作为旧点的梯度值,来准备下一轮迭代
D_old = D_new
d_old = d_new #把x当前点的更新方向,作为旧点的更新方向,来准备下一轮迭代
print('拟牛顿法之BFGS')
print('x: ' + str(x_new.T))
print('y: ' + str(y_new))
print('迭代 ' + str(iteration) + ' 次')
print('\n')
##################################################################################################
结果如下:
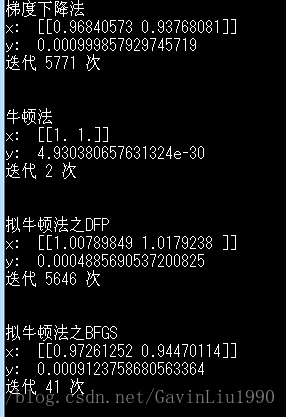
- Tips
-
代码是面向过程的风格,更有助于理解优化算法的核心思想。
- 上述优化算法的核心思想都是根据x旧点的信息来迭代得到x新点,直到满足迭代停止条件。