3000fps和之前的[ESR][1]使用了同样的cascade的方式,把整个alignment过程分几个stage来做,每一个stage的alignment都依赖上一个stage得到的alignment shape.
每个stage所做的工作一样,可以分为三个过程
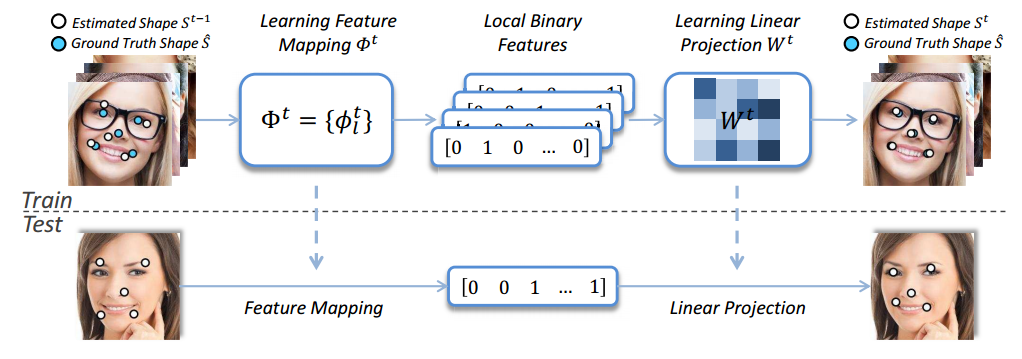
- 提取特征(shape index feature)
- LBF编码(learning local binary feature)
- 获取shape 增量(learning global linear regression)
shape index feature
shape index feature 也就是特征和现有的一系列标定点是相关的,3000fps的做法是在landmark周围随机出两个偏移量,形成两个点,用这两个点的像素差作为特征。 
红色的点表示landmark,蓝色的框框表示随机取样特征的半径,两个绿色的点表示随机出来的特征点位置,用两个绿色的点的差值作为特征。
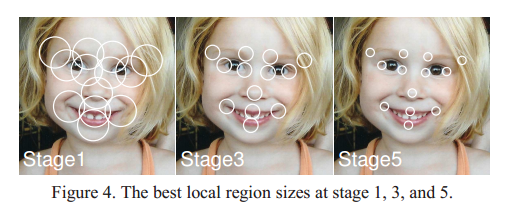
刚开始的时候,shape和ground truth差距太大,因此需要取样特征的半径大一些,最后的shape和ground truth已经很接近了,半径要小一些。
learning local binary feature
3000fps使用随机森林来做回归,每个Stage 有K棵树,每棵树的深度为D,内部节点分裂准则是最大方差减小。
内部结点的分裂过程如下:
input: 特征矩阵X,大小m*n(由于是像素差值特征,因此X中所有元素取值范围为[-255, 255]);regression target ΔSΔS
output: 最佳分裂属性(id,val)
- 随机p组属性(id, val)
- 每个样本id位置的属性值都和val比较,小于val的样本划到左子结点,大于val的样本划归右子结点。然后计算,按该属性划分的方差减小(在这里用到了target ΔSΔS)
- 从P组属性中选出方差减小最多的属性(id, val)作为分裂属性
依照这样的方法建立一棵深度为D的树,然后再重复K次,建立起完成的森林
3000fps并没有使用随机森林的输出作为shape的增量,而是进行了编码: 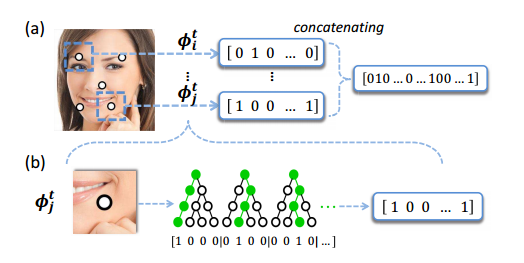
如果每棵树有leafNum个叶子结点,所有叶子结点形成一个leafNum维的向量;
训练样本通过一棵树,最终总会落在其中一个叶子结点,样本落在那个叶子结点就把相应的位置置1,其它位置置0;待训练样本通过所有的k棵树后,把K个leafNum维的向量连接起来,形成最终的K*leafNum维的特征向量,可以看到,这样的特征向量是非常稀疏的,只有很少的位置是1.
learning global linear regression
上边求出的lbf特征为所有的landmark公用,通过求解下边的式子,得到weight W: 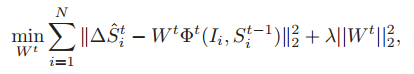
以求解其中一个landmark的ΔxΔx为例:
input: lbf特征,所有样本的ΔxΔx组成的regression target vector
output: w
借助LibLinear求解系数向量w;
测试的时候,先对一幅图像提取shape index feature, 然后使用随机森林进行编码,最后使用w估计shape 增量。
求解ΔyΔy的过程一样,只是regression target vector换了而已
按照上边的方法对所有landmark进行global regression
最后得到权重矩阵W。
C++实现代码的error和论文一致 github链接
以下是论文解读:效果见最后
1.Framework
整个流程基于Cascade Pose Regression(CVPR 2010),分为T个stage,在训练时步骤如下(testing也类似)
- 每个stage先抽取local binary features,
- 然后根据真实的ΔS^iΔS^i 用linear regression训练一个regressor,
- 最后用训练出来的regressor得到ΔSiΔSi(是ΔS^iΔS^i的近似)去更新前一个stage的shape,得到更加精确的shape
1.1 Training Phase:
Input: Image set {II}(N samples), ground truth shapes {S^S^}, initial shapes set {S0S0}
For t=1:T do
featuresi=ϕt(Ii,St−1i)featuresi=ϕt(Ii,Sit−1)
ΔSi^=Si^−Si−1ΔSi^=Si^−Si−1
E=∑∥Si^−Rt(featuresi)∥2E=∑‖Si^−Rt(featuresi)‖2
ΔSi=Rt(featuresi)ΔSi=Rt(featuresi)
Sti=St−1i+ΔSiSit=Sit−1+ΔSi
End For
1.2 Testing phase
Input: Image I, initial shape S0S0
Output: refined shape SS
For t=1:T do #总共有T个stage
features=ϕt(I,St−1)features=ϕt(I,St−1)
ΔS=Rt(features)ΔS=Rt(features)
St=St−1+ΔSSt=St−1+ΔS
End For
2. 抽取Local Binary Features
- 先random产生500个pixel difference features
- 选取最具有分辨力的pixel difference features作为Random Forest中每棵树中的非叶子结点
- 输入图片得到Local Binary Features
2.1 Pixel Difference Features
Pixel Difference Features源自CVPR 2012的一篇叫face alignment by explicity shape regression的文章。
- Pixel Indexed Features
如上图,作者认为对于特定的一个landmrk,它周围的有些点是几何不变的,比如我们有一个landmark是左眼的右眼角P(x,y)P(x,y),在它的上方某个地方ΔP(Δx,Δy)ΔP(Δx,Δy)具有不变的性质,比如附近的眉毛某点 P(x+Δx,y+Δy)P(x+Δx,y+Δy) 就是黑色的,这个对每个人来说都是一样,当然由于光照等其他因素的原因,这个颜色还是有很大差异的,那么作者就提出了 Pixel Difference Features - Pixel Difference Features
其实很简单,就是将附近某两个点的值相减得到一个差值,而这个值很大程度上在一个阈值内浮动,而且还可以剔除光照等因素的影响,即feature=I(x+Δx1,y+Δy1)−I(x+Δx2,y+Δy2)feature=I(x+Δx1,y+Δy1)−I(x+Δx2,y+Δy2)
2.2 创建Random Forest
Random Forest维基链接。Random Forest由很多tree组成,相比于单棵tree能够防止模型的over fitting。Random Forest能用于regression(本文用到的功能)和classification。
那么如何建立Random Forest,主要是如何选择split node,下面以如何构建一颗regression tree为例。
- 首先我们确定一个landmark l,随机产生在l附近的500个pixel difference features的位置,然后对training中的所有images抽取这500个features,
- 确定要构建l的第几个棵树(其他树一样,只是训练数据不一样而已)
- 从树根节点开始 (节点分裂代码)
var = variance of landmark l of traing images,
var_red = -INFINITY, fea = -1, left_child = NULL, right_child = NULL
For each feature f:
threshold = random choose from all images’s feature f
// 比如现在所有图的f的值是2,2,2,4,5,3(假设有5张图),那么随机选择threshold可能是3
tmp_left_child = images with f < threshold
// 左子节点为所有f小于threshold的图片
tmp_right_child = images with f >= threshold
tmp_var_red = var - |left_child|/|root|*var_tmp_left_child - |right_child|/|root|*var_tmp_right_child
// var_tmp_left_child是左子节点landmark l的variance
if ( tmp_var_red > var_red) {
var_red = tmp_var_red
fea = f
left_child = tmp_left_child
right_child = tmp_right_child
}
End For - 实际上var是固定的,所以不用算,|left_child|是当前left_child所包含的图片数,|root|表示root包含的图片数,实际计算的时候可以省去,因为是定的。
fea就是最后选择的feature - 对子节点left_child和right_child做跟3一样的操作,直到达到tree的最大depth,或者对于某一个根节点根据maximum variance reduction找到的feature是恰好一个child包含了所有的图,而另一个child没有图(事实上这个情况基本上不太可能出现),所以训练的时候基本上能够达到定义的max_depth,经我个人验证max_depth=5,6就可以了,在深很容易出现overfitting的问题
- landmark l的其他树也一样如上,对其他landmark和对l的操作一样
2.3 Local Binary Features
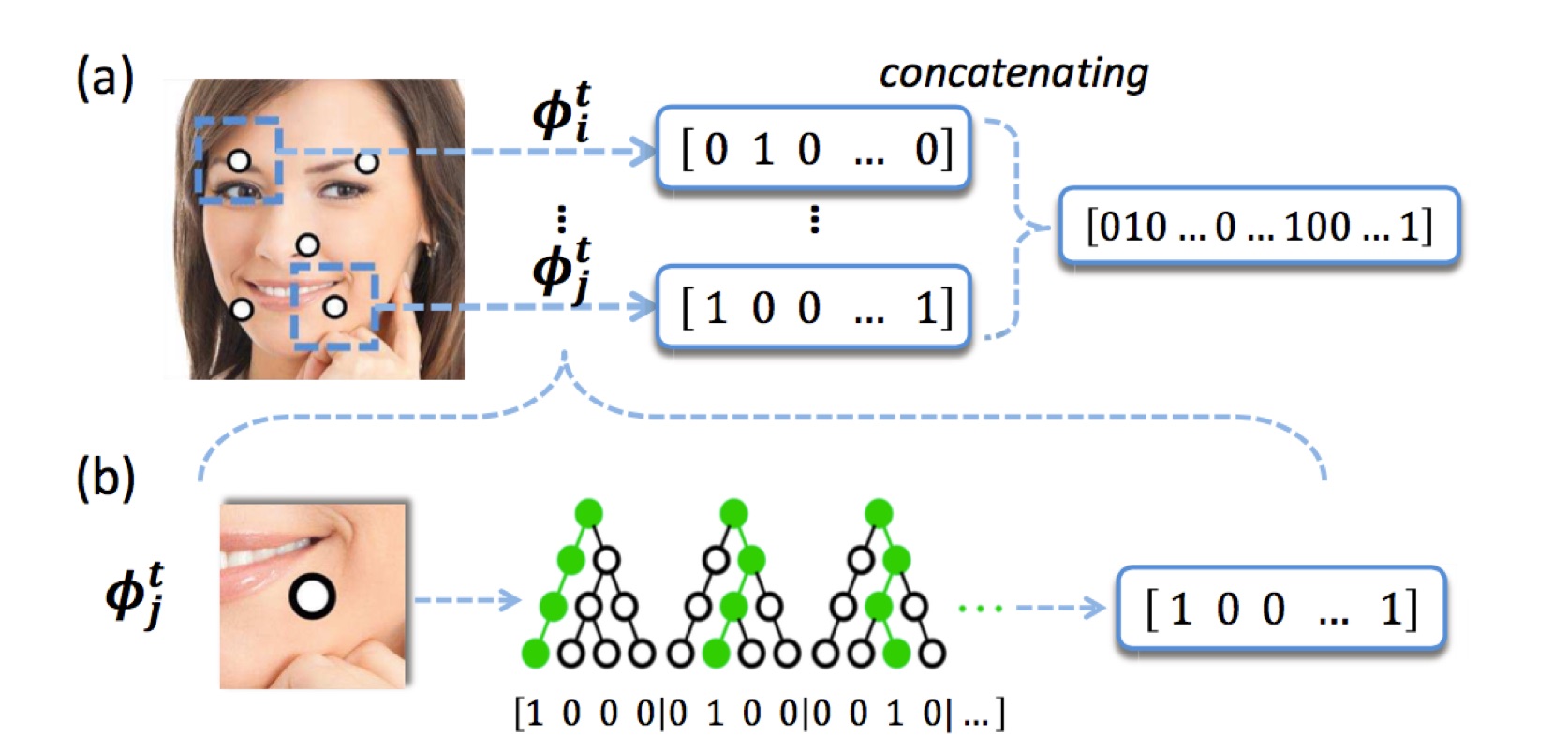
那么对于每一张图的每一个landmark的每一棵树最后都会输出一个值,如上图下方,第一棵树遍历后来到了最左边的子节点所以记为[1, 0, 0, 0],对于每一棵树访问到的叶子节点记为1,其他的记为0,然后一个landmark拥有一个forest即有多棵树,那么把所有的结果连起来就是ϕtl=[1,0,0,0,0,1,0,0,0,0,1,0,…]ϕlt=[1,0,0,0,0,1,0,0,0,0,1,0,…],真正的Local Binary Features是将所有的landmark的这些feature都连起来。
ϕt=[ϕt1,ϕt2,…,ϕtL]ϕt=[ϕ1t,ϕ2t,…,ϕLt]
所以我们可以看出这是一个很稀疏的向量,中间为1的个数是所有landmark中tree的总个数,其余的为0。然后就是要训练一个global linear regression了
3. Learning Global Linear Regression
minWt∑Ni=1∥ΔSti^−Wtϕt(Ii,St−1i)∥22+λ∥Wt∥22minWt∑i=1N‖ΔSit^−Wtϕt(Ii,Sit−1)‖22+λ‖Wt‖22
对每一个landmark训练时用的都是同一个local binary features.
- 比如对于第一个landmark的ΔxΔx坐标进行regression,输入就是所有图片的local binary feature矩阵,所有ΔxΔx坐标组成的vector作为regression target,最后可以得到一个权重向量w,然后有了新的图片,抽取它的local binary feature后,乘以w就可以得到预测的ΔxΔx值,最后加到上一个stage的xx上面得到新的xx
- 对于第一个landmark的ΔyΔy也是一样,这里的local binary feature矩阵和上面ΔxΔx矩阵的一样,只是要regression的target ΔyΔy不一样,
- 其他的landmark同上
- 上面的公式,是将所有的landmark的w都合在一起了,求一个整体的W
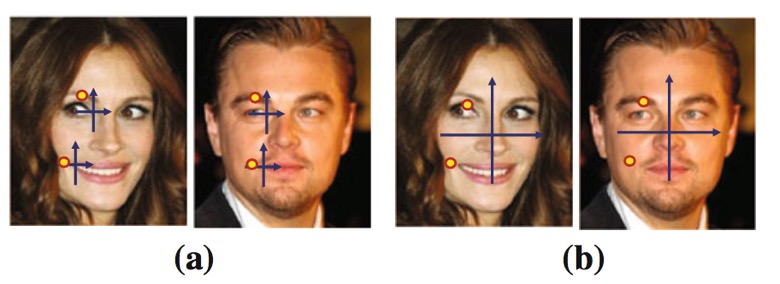
4. 效果如图:还是很不错的
initial shape

final shape

http://freesouls.github.io/2015/06/07/face-alignment-local-binary-feature/index.html