一、概述
本文提出了一个多任务的人脸检测模型,可以同时进行人脸检测和人脸特征点提取。这个框架主要由三个CNN级联的方式实现。
- stage1:通过一个浅的CNN来产生一些候选框
- stage2:通过一个较复杂的CNN,对候选框进一步删选得到更精细的区域
- stage3:通过一个强大的CNN,对结果进一步处理,输出人脸边框和5个特征点位置
二、实现细节

具体的实现过程如上图所示,总的来说分为四个部分
- 给定一张图片,首先更改图片的大小以建立图像金字塔,这作为模型的数据输入
- 通过一个全卷积网络(P-Net),生成候选框和bounding box regression vectors,使用bounding box regression vectors校准这些候选框,使用NMS合并重叠候选框
- 上层所有的候选框会被传给当前网络(R-Net),这会进一步筛选,再使用bounding box regression vectors和NMS
- 和上面类似,使用O-Net输出最终的人脸框和特征点位置
CNN结构:

三、训练
算法需要实现三个任务,分别是人脸与非人脸分类,bounding box 回归,人脸特征点定位
1.人脸与非人脸分类
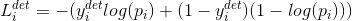
类似于交叉熵损失函数,这里的y表示ground_truth label,p表示网络结果输出是人脸的概率。
2.bounding box回归
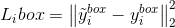
这里的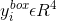
3.人脸特征点定位
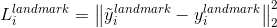
这里的
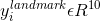
4.多目标训练

这里的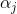
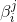
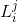
这里在P-Net和R-Net使用了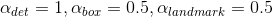
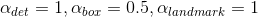
这里数据集分类以下四个类别
- Positive
- Negative
- Part faces
- Landmark face
其中Negative和Positive用于人脸分类,Positive和Part faces用于bounding box回归,Landmark用于特征点定位。