Face alignment 实现方案及实现效果分析
1. Face Alignment 简介
在Face Alignment中,传统方法能够取得不错的效果。但是在大姿态、极端表情上效果并不是很好。人脸对齐可以看作在一张人脸图像搜索人脸预先定义的点(也叫人脸形状),通常从一个粗估计的形状开始,然后通过迭代来细化形状的估计。 其实现的大概框架如下:
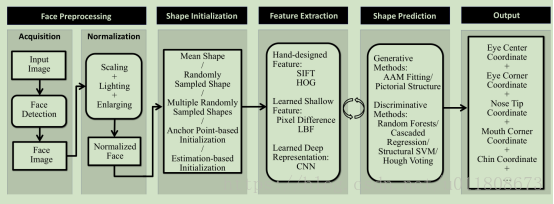
图1.1
人脸特征点检测问题需要关注两个方面:一是特征点处的局部特征提取方法,二是回归算法。特征点处的局部特征提取也可以看做是人脸的一种特征表示,现在的基于深度学习的方法可以看做是先使用神经网络得到人脸特征表示,然后使用线性回归得到点坐标。
2. 深度学习相关论文
2.1 Deep Convolutional Network Cascade for Facial Point Detection
香港中文大学唐晓鸥教授的课题组在CVPR 2013上提出3级卷积神经网络DCNN来实现人脸对齐的方法。该方法也可以统一在级联形状回归模型的大框架下,和CPR、RCPR、SDM、LBF等方法不一样的是,DCNN使用深度模型-卷积神经网络,来实现。第一级f1使用人脸图像的三块不同区域(整张人脸,眼睛和鼻子区域,鼻子和嘴唇区域)作为输入,分别训练3个卷积神经网络来预测特征点的位置,网络结构包含4个卷积层,3个Pooling层和2个全连接层,并融合三个网络的预测来得到更加稳定的定位结果。后面两级f2, f3在每个特征点附近抽取特征,针对每个特征点单独训练一个卷积神经网络(2个卷积层,2个Pooling层和1个全连接层)来修正定位的结果。该方法在LFPW数据集上取得当时最好的定位结果。

图2.1
2.2 Coarse-to-Fine Auto-Encoder Networks (CFAN) for Real-Time Face Alignment
一种由粗到精的自编码器网络(CFAN)来描述从人脸表观到人脸形状的复杂非线性映射过程。该方法级联了多个栈式自编码器网络,每一个刻画从人脸表观到人脸形状的部分非线性映射。具体来说,输入一个低分辨率的人脸图像I,第一层自编码器网络f1可以快速地估计大致的人脸形状,记作基于全局特征的栈式自编码网络。网络f1包含三个隐层,隐层节点数分别为1600,900,400。然后提高人脸图像的分辨率,并根据f1得到的初始人脸形状θ1,抽取联合局部特征,输入到下一层自编码器网络f2来同时优化、调整所有特征点的位置,记作基于局部特征的栈式自编码网络。该方法级联了3个局部栈式自编码网络{f2 , f3, f4}直到在训练集上收敛。每一个局部栈式自编码网络包含三个隐层,隐层节点数分别为1296,784,400。得益于深度模型强大的非线性刻画能力,该方法在XM2VTS,LFPW,HELEN数据集上取得比DRMF、SDM更好的结果。此外,CFAN可以实时地完成人脸人脸对齐(在I7的台式机上达到23毫秒/张),比DCNN(120毫秒/张)具有更快的处理速度。
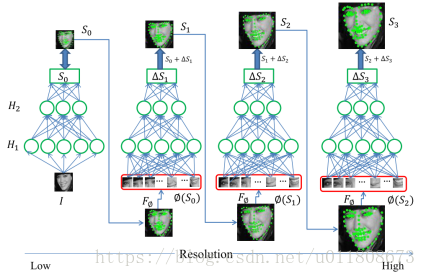
图2.2
3. 目前研究流程
3.1实现方案Pipline:

图3.1
3.2 流程解析
3.2.1 Stage One
a) Resize:将人脸图片resize到32*32的大小,landmark shape的位置同比例变换。
b) landmark选择:挑选出26个人脸的landmark(人脸边缘21个,剩余眼睛2个,鼻子1个,嘴巴两个,将26个位置信息展开就是26*2 = 52维)。 其效果图如图所示:

图3.2
c) landmark shape归一化:训练前可以对数据做简单处理,把图像的左上角看成坐标(-1,-1),右下角坐标看作(1,1),以此来重新计算 landmark shape 的位置信息。
注意:可能有些landmark并没有出现在图中,此时的位置信息用(-1,-1)表示,所以在测试阶段,应舍弃左上角的小区域位置信息。
舍弃规则: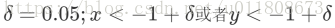
d) 激活函数的选择,为了更好的拟合我们的位置信息,我们采用tanh函数作为激活函数。因为我们的位置信息是[-1,1],采用tanh更容易收敛。 [当然此处也可使用sigmoid激活函数,那么对应的我们landmark shape 归一化时应将图片左上角看成(0,0),右下角看成(1,1))舍弃规则: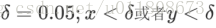
e) tanh 函数图像如下图所示:
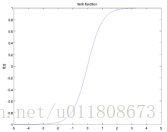
图3.3
f) Loss 采用的是EuclideanLoss,公式如下。

提示: 如果想提高边缘的精度可以通过给边缘点设置更大的误差比例,如 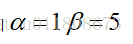
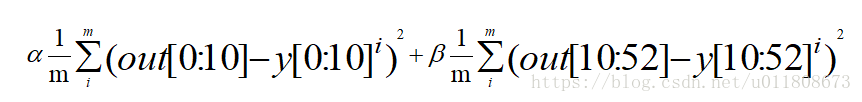
其中[0:10]表示的是眼睛鼻子嘴巴5个landmark, [10:52]表示的是人脸的边缘21个landmark
3.2.2 Stage two
a) Resize:将人脸图片resize到96*96的大小,landmark shape的位置同比例变换。
b)训练数据准备,训练数据分为4部分,分别为左眼,右眼,鼻子,嘴吧。第二阶段训练数据准备有以下几个方法。
l 基于第一阶段的5个输出结果作为中心进行区域剪裁,剪裁宽高为[48,36],剪裁后需要用 stage one 第c步的方式变换 landmark shape 位置信息。
l 基于标注好的数据,根据已经标注的信息进行区域剪裁,及landmark shape 位置信息变换。剪裁中心可做小范围变换以模拟真实的 stage one 结果。
c) landmark 归一化,激活函数,loss函数与 stage one 一致。
d)训练时首先将4个部分的patch图片通道融合,融合后的图片结果为:[48,36, 3*4],此处如果不对图片做通道融合而是分别使用4个CNN网络进行回归,理论上会有更精确的回归效果,但是考虑训练起来较麻烦,所以采用了融合的方法,这样只用训练一个CNN网络进行回归。
3.3检测结果
联合Stage One 和 Stage Two 的检测结果。

图3.4
由图可以看出侧脸人脸边缘检测的效果没有其他的landmark位置准确,主要是因为,为了加快回归,边缘信息只经过一次基于全局图片特征的回归。
4. 训练
4.1.训练配置
base_lr: 0.00001
lr_policy: "inv"
gamma: 0.0001
power: 0.75
regularization_type: "L2"
weight_decay: 0.0005
momentum: 0.9
max_iter: 20000
4.2 模型图
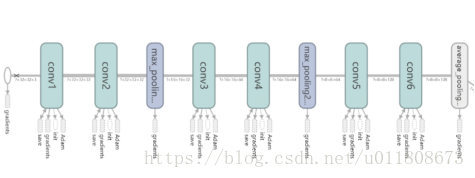
图4.1
5.误差分析
5.1误差loss计算
测试误差评价标准公式如下:
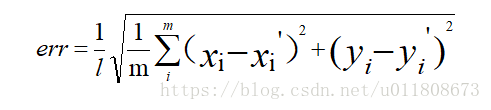
其中l是人脸框的长度,m是landmark的个数。
5.2 Loss函数收敛情况
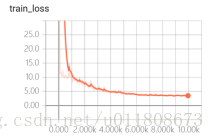
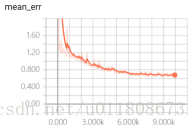
图5.1
这里 train_loss 加了一个5倍的权重参数,所以最后的值反而比test_loss的值大。