【翻译】
【摘要】
这篇文章展示了一种高效、精确回归的人脸定位方法。包括了两个创新部分:1.一组局部二值特征,2.学习这些特征的一种局部原则。这个局部原则能够针对每一个脸部标记【独立】学习一组高判别度的局部二值特征。而这些局部二元特征又会联合学习一个结果的线性回归。
厉害的地方:1.针对目前的最具挑战的定位问题能达到一个最优结果;2.这些局部二元特征的获取和运用代价很低,所以速度会非常快。desktop能达到3000fps,手机能达到300fps。
【引言】
Discriminative shape regression【判别形状回归】这是有精确性和鲁棒性的一种人脸定位算法(是不是呢?还不知道)其特点:1).纯判别性;2).对形状约束具有适应性;3).能够有效地平衡大训练集。
形状回归方法通过迭代预测脸部形状S。初始形状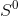
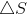

------(1)
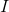
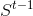
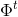
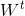
。
这个特征映射函数
从原理上讲,后一个基于学习的方法更好,因为他是针对性的特征学习。但是在已有文献的报告中,它的效果只是与使用手工设的SIFT特征的方法持平。我们认为这是由过度高自由度的
因此,我们提出了一种基于学习【学习的
我们提出两种学习![\Phi ^{t} = \left [ \phi _{1}^{t}, \phi _{2}^{t},...,\phi _{L}^{t}\right ]](https://img-blog.csdnimg.cn/20181220132744181)
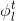
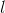
这个提出的正则化方法可以有效的筛选出主要的噪声和判别性较弱的特征,降低学习的复杂度,从而导致更好地泛化性能。
为学习每个

除了具有更好地准确性,我们的方法还更高效。因为局部二值特征是基于树的,并且高度稀疏,处理提取和回归这样的特征是十分迅速的。后面就是说到底有多快....
【相关工作】
Active Appearance Models(AAM)通过建立整体的外表和形状模型解决人脸对齐问题。很多基于AAM的改善方法被提出。相较于AAM,关注于局部的模型是学习一组局部检测器或者回归器,并限制其使用多形状模型。这样的方法有更好的泛化能力和鲁棒性。
我们的工作属于形状回归方法类,Xiong 通过基于SIFT特征的线性回归预测形状增量。Cao 和Burgos-Artizzu利用boosted ferns(树)来回归形状增量。我们注意到基于集成树的方法(包括boosted trees or random forest)也可以被视为使用由树诱导的二元特征的回归量的线性和,然而,我们的特征学习方法不同于先前基于树的方法。
集成树可作为有效编码或者学习更佳的描述符的码本。近来,它也被用于直接特征映射以处理非线性分类。 在这项工作中,我们证明了集合树诱导特征在形状回归中的有效性。
【局部二值特征回归】
等式(1)中,线性回归矩阵
【学习局部二值特征
特征映射函数是由一组局部特征映射函数组成,如: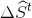
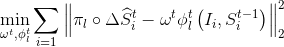
-迭代所有训练样本,
从
中提取两个元素
,
是第
个样本的第
个标记的2D偏移ground truth。
标准回归随机森林学习每个局部映射函数,由像素差异特征训练得到划分节点(split nodes),测试500个随机样本特征并从中挑选出有最大方差减少量的特征来训练每个划分节点,实验中测试越多的特征也仅仅是细微的改善。训练后,每一个叶节点存储2D偏移向量(叶上所有训练样本的平均值)
我们在被估计标记的局部区域仅仅以像素特征做样本,这样一个局部区域的应用对我们的方法来说是重要的。训练中,通过交叉验证在每一级中估计最佳区域大小。
测试中,一个样本遍历树到达叶节点。随机森林的输出是存储在这些叶节点中的输出的总和。假设叶节点的总数是D,输出可以重写为:

局部二元函数 (a)局部特征映射函数φt1将对应的局部区域编码为二元特征; 整合所有局部二元特征以形成高维二元特征。 (b)我们使用随机森林作为本地映射函数。 每个提取的二元特征指示输入图像是否包含一些局部模式。
是2×D矩阵,其中每列是存储在相应叶节点中的2D矢量,并且
是D维二元矢量。 对于
中的每个维度,如果测试样本到达相应的叶节点,则其值为1,否则为0。 因此,
是非常稀疏的二元矢量。
中非零元素的数量与森林中树木的数量相同,远远小于D.我们称之
为“局部二元函数”。 图2说明了提取局部二元特征的过程。
【全局线性回归学习】
局部随机森林学习后,不仅获得了二元特征,还有局部回归输出
。舍掉
,联合二元特征组成一个全局特征映射函数
并最小化下面的函数来学习线性投影
:
第一部分是回归目标,第二部分是的L2正则化,
控制正则化力度。由于特征维度大,所以正则化是必须的。实验中,68个标记,
的维度可以100k+。没有正则化,我们观察到大量过拟合。因为二元特征是高稀疏的。我们利用双坐标下降法来处理这样的高稀疏线性系统。由于目标函数相对于
是二次方,我们总能达到其全局最优。
我们发现这样全局再学习或者转换学习对于性能改善是重要的。认为有两个原因:由于训练集在一个叶节点的不充分性,随机森林局部学习结果是有噪声的;另外就是全局回归可以有效地强制执行全局形状约束,并减少由遮挡和模糊局部外观引起的局部错误。

横轴表示局部区域半径。 垂直轴代表测试装置上的对准误差。 从左到右,Δs分布的标准偏差为0.05,0.1,0.2。 这里,局部区域半径和对准误差都由面矩形的大小归一化。
【局部原则】
如前面描述,特征训练中两种重要的正则方法由局部原则指导,1)每个标记独立学习一个森林;2)我们仅仅考虑在标记的局部区域中的像素特征。下面解释为什么这样选择。
为什么局部区域?
假设我们想要预测一个单独标记的偏移量,从半径r的局部区域选择特征。起初,最优半径应该依赖于
的分布。如果所有样本的
广泛分布,我们应该使用大r,否则用小r。
为了研究的分布与最佳半径r之间的关系,对于标记我们合成训练和测试样本区域,其
遵循具有不同标准偏差的高斯分布。 对于每个分布,我们通过在各种半径上训练回归森林来实验地确定最佳区域半径(在测试误差方面)。 我们使用与我们的级联训练相同的森林参数(树深度和树木数量)。 我们对所有标记重复此实验,并取最佳区域半径的平均值。
上图显示了标准0.05,0.1和0.2(面部矩形尺寸的归一化距离)的三个分布结果。 最佳半径为0.12,0.21和0.39。 结果表明,最佳区域半径几乎与Δs的标准偏差呈线性关系。 因此,我们可以得出结论,鉴于有限的计算预算(在训练森林中测试的特征的数量),仅考虑局部区域中的候选特征而不是全局面部图像更有效。

我们的级联训练中,在每个阶段,我们通过保持验证集上的交叉验证来搜索最佳区域半径(来自10个离散值)。 上图显示了在第1,3和5阶段发现的最佳区域半径。正如预期的那样,半径从早期逐渐收缩到后期,因为在级联期间回归面形状的变化减小。
为什么单个标记回归?
似乎每个标记独立回归是次优的。例如,我们可能错过了在多标记下的高特征。然后,我们局部回归也有一些全局回归没有的优势。
第一,局部特征池是少噪声的。可能在全局学习中有更多有用特征,但是全局中的信噪比可能会低一些,这会使特征选择更加困难。
第二,运用局部回归不代表局部预测,在第二步中,做线性回归时利用所有学习的局部特征去做一个全局预测。因为标记的局部学习是独立的。产生的特征也自然也是多样且互补的。这些特征更适合第二步的全局学习。
最后,在每一级中,局部学习具有适应性。早期的阶段中,局部区域大小相对大且一个局部区域会覆盖多个标记。从一个标记中学到的特征可以帮助邻近标记。最后阶段,区域大小是小的且局部回归微调每个标记,因此局部学习更合适与最后阶段。
请注意,我们并未声称全球学习本质上不如我们的本地学习。 我们认为,由于实际原因,本地学习主要提供更好的表现。 考虑到有限的训练能力(训练数据量,可负担的训练时间,可用的计算资源和学习算法的能力),本地方法可以更好地抵抗全局特征池中的噪声特征,这非常大并且可能导致过度拟合。 我们希望我们在这项工作中的实证研究结果可以鼓励未来进行更多类似的调查。