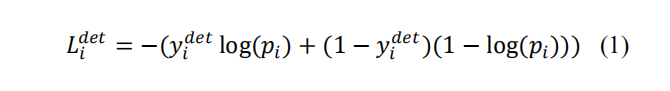二. APPROACH
In this section, we will describe our approach towards joint
face detection and alignment.
A. Overall Framework
The overall pipeline of our approach is shown in Fig. 1.
Given an image, we initially resize it to different scales to build
an image pyramid, which is the input of the following
three-stage cascaded framework:
Stage 1
: We exploit a fully convolutional network[?], called
Proposal Network (P-Net), to obtain the candidate windows
and their bounding box regression vectors in a similar manner
as [29]. Then we use the estimated bounding box regression
vectors to calibrate the candidates. After that, we employ
non-maximum suppression (NMS) to merge highly overlapped
candidates.
Stage 2
: all candidates are fed to another CNN, called Refine
Network (R-Net), which further rejects a large number of false
candidates, performs calibration with bounding box regression,
and NMS candidate merge.
Stage 3
: This stage is similar to the second stage, but in this
stage we aim to describe the face in more details. In particular,
the network will output five facial landmarks’ positions.
在这一部分,我们将描述把人脸检测和关键点对准结合起来的方法。
A.整体框架
总体的过程正如fig1 中所给出的图片那样,首先初始化不同大小的图片来构造一个图片金字塔,并把这个金字塔作为接下来三个阶段级联框架的输入。
第一阶段:使用一个全卷积的网络,叫做Proposal Network(P-Net),来得到候选窗口,和他们的边界区域向量,这个方法和【29】的方法类似。然后我们使用这些估算的边界回归向量 来校准候选窗口。之后,使用NMS 无上限的压制?来合并高度重叠的窗口。
第二阶段:所有的窗口都被送到另一个卷积神经网络中,它叫做Refine network(R-Net),可以把大部分错误的窗口给去除掉,用边界框回归进行校准,并使用了NMS(非最大抑制?)
第三阶段:和第二阶段类似,但是在这个阶段我们要用更多的细节描述面部,尤其是,网络将会输出五个面部标记。
B. CNN Architectures
In [19], multiple CNNs have been designed for face detec
tion. However, we noticed its performance might be limited by
the following facts: (1) Some filters lack diversity of weights
that may limit them to produce discriminative description. (2)
Compared to other multi-class objection detection and classi
fication tasks, face detection is a challenge binary classification
task, so it may need less numbers of filters but more discrimi
nation of them. To this end, we reduce the number of filters and
change the 5×5 filter to a 3×3 filter to reduce the computing
while increase the depth to get better performance. With these
improvements, compared to the previous architecture in [19],
we can get better performance with less runtime (the result is
shown in Table 1. For fair comparison, we use the same data for
both methods). Our CNN architectures are showed in Fig. 2.

B.卷积神经网络的结构
在【19】中,多个CNNs被设计出来用于人脸检测。然而它的表现可能是被以下几点限制:(1)一些滤波器缺乏多样性,这限制了他们产生有区别的结果。(2)与其他很多种类目标检测和分类任务相比,人脸检测是一项很有挑战的二值分类任务,所以可能需要更少的滤波器但是同时需要更有区分能力。所以,我们减少滤波器的数量,并把5x5的滤波器改为3x3的来减少计算量,同时增加深度从而获得更好的结果。
通过这些改进,与先前【19】中的结构相比较,我们可以用更少的运行时间来获得更好的性能。(结果在Table 1 中展示,为了公平比较,我们给两种方法使用相同的数据集。)我们的CNN结构在Fig 2中展示。
C. Training
We leverage three tasks to train our CNN detectors:
face/non-face classification, bounding box regression, and
facial landmark localization.
1) Face classification:
The learning objective is formulated as
a two-class classification problem. For each sample , we use
the cross-entropy loss:
C.训练
使用三项任务来训练CNN检测器: 人脸/非人脸的分类,边界回归,面部标志定位。
1)面部分类:
学习的任务是关于一个两点分类的问题,对于每个样本xi,使用交叉熵损失函数
(cross-entroy loss):
pi是有网络产生的描述一个样本是一张脸的可能性,符号yi【0-1】是ground-truth label
机器学习包括有监督学习(supervised learning),无监督学习(unsupervised learning),和半监督学习(semi-supervised learning).
在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注.正确的t标注是ground truth,* 错误的标记则不是。(也有人将所有标注数据都叫做ground truth)
作者:小明大白
链接:https://www.jianshu.com/p/7487d85246a0
来源:简书
2) Bounding box regression:
For each candidate window, we
predict the offset between it and the nearest ground truth (i.e.,
the bounding boxes’ left top, height, and width). The learning
objective is formulated as a regression problem, and we employ
the Euclidean loss for each sample
:
where y
̂
regression target obtained from the network and
y is the ground-truth coordinate. There are four coordinates,
including left top, height and width, and thus
.
2) 边界框回归:对于每一个候选窗口,都预测出它和最近窗口的抵消。(例如边界框的左上角坐标,高度和宽度)。学习目标被定为为一个回归问题,使用Euclidean loss(欧氏损失)来记录每个样本xi:
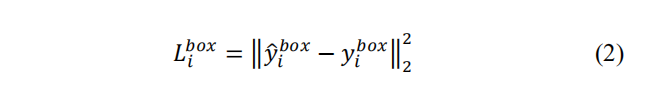
y尖是从网络得到的回归目标,yi是坐标标注。有四个坐标标注分别是左上,高度,宽度。所以yi是一个四维变量
3) Facial landmark localization:
Similar to the bounding box
regression task, facial landmark detection is formulated as a
regression problem and we minimize the Euclidean loss:
3)面部标志的定位:类似于边界框回归的任务,面部标志检测是 一个回归问题,我们最小化欧氏损失:
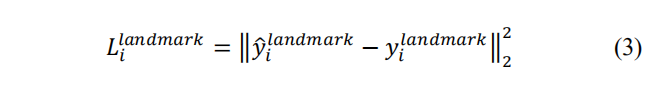
Y尖是通过网络获得的面部坐标,yi是标注坐标。有五个面部标志:左右眼,鼻子,左右嘴角。因此yi是一个10维向量。
4) Multi-source training:
Since we employ different tasks in
each CNNs, there are different types of training images in the
learning process, such as face, non-face and partially aligned
face. In this case, some of the loss functions (i.e., Eq. (1)-(3) )
are not used. For example, for the sample of background region,
we only compute
, and the other two losses are set as 0.
This can be implemented directly with a sample type indicator.
Then the overall learning target can be formulated as:
4)多来源训练:在每个CNN结构中执行不同的任务,在学习过程中训练不同类型的图片,比如人脸,非人脸,还有一部分是整齐的脸。在这种情况下,一些损失函数比如在1)-3)中提到的,就不被使用了。例如,对于一些背景区域的样本,我们只计算Li,另外两个损失就直接设置为0.这个过程可以用一个样本类型指示器直接执行。然后整体的学习目标就可以被描述为:
N是训练样本的总数,αj表示任务的重要性,在P-net和R-net中α det =1,α box=0.5,α landmark =0.5 ,在O-net中是 1,0.5,1,在O-net中使用更精确的面部标志定位, β【0-1】是样本类型指示器,很显然要使用随机梯度下降法来训练这个CNNs(stochastic gradient descent)。
5) Online Hard sample mining:
Different from conducting
traditional hard sample mining after original classifier had been
trained, we do online hard sample mining in face classification
task to be adaptive to the training process.
In particular, in each mini-batch, we sort the loss computed
in the forward propagation phase from all samples and select
the top 70% of them as hard samples. Then we only compute
the gradient from the hard samples in the backward propagation
phase. That means we ignore the easy samples that are less
helpful to strengthen the detector while training. Experiments
show that this strategy yields better performance without
manual sample selection. Its effectiveness is demonstrated in
the Section III.
5)在线的困难识别样本采集:不同于在原始分类器被训练完成后再采集困难样本的传统方式,我们在面部分类任务过程中在线采集困难样本。特别的,在每一批次采集中,我们把所有样本中使用向前传播方式计算出的损失排序,把他们之中的前70%作为困难样本。然后我们就只计算困难样本的向后传播的梯度?这意味着我们忽视掉了那些对加强训练分类器有很小帮助的简单样本,实验证明这种方法在没有手工样本选择的时候会产生更好的结果。它的效率在第三部分表明。