版权声明:本文为博主原创文章,转载请注明出处 https://blog.csdn.net/King_key/article/details/79283482
1 特征降维是无监督学习的应用之一,主成分分析是最为经典和实用的特征将维技术,尤其是在辅助图像识别方面
实验数据:手写体数字图像 全集数据
2 实验代码及结果截图
#coding:utf-8
import numpy as npimport pandas as pd
#读取训练数据和测试数据
digits_train=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tra',header=None)
digits_test=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/optdigits/optdigits.tes',header=None)
#分割训练数据的特征向量和标记
x_digits=digits_train[np.arange(64)]
y_digits=digits_train[64]
#导入PCA
from sklearn.decomposition import PCA
#初始化一个可以将高维度特征向量压缩至2个维度的PCA
estimator=PCA(n_components=2)
x_pca=estimator.fit_transform(x_digits)
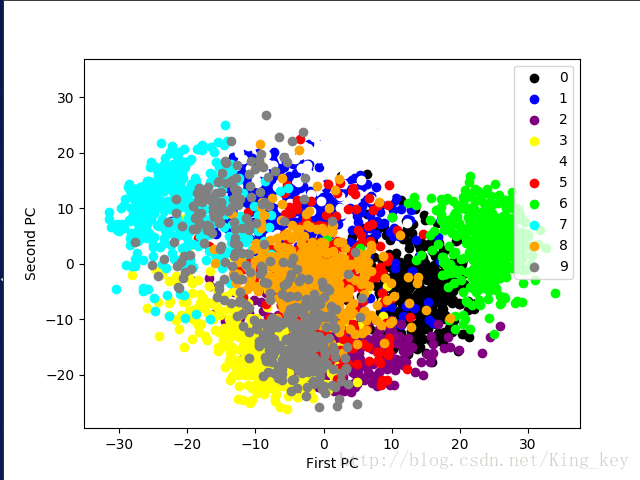
#显示10类手写体数字图片经PCA压缩后的二维空间分布
from matplotlib import pyplot as plt
def plot_pca_scatter():
colors=['black','blue','purple','yellow','white','red','lime','cyan','orange','gray']
for i in xrange(len(colors)):
px=x_pca[:,0][y_digits.as_matrix()==i]
py=x_pca[:,1][y_digits.as_matrix()==i]
plt.scatter(px,py,c=colors[i])
plt.legend(np.arange(0,10).astype(str))
plt.xlabel('First PC')
plt.ylabel('Second PC')
plt.show()
plot_pca_scatter()
#使用原始像素特征和经PCA压缩重建的低维特征,在相同配制的支持向量机模型上分别进行图像识别
x_train=digits_train[np.arange(64)]
y_train=digits_train[64]
x_test=digits_test[np.arange(64)]
y_test=digits_test[64]
#导入基于线性核的支持向量机分类器
from sklearn.svm import LinearSVC
from sklearn.decomposition import PCA
#使用PCA对原始像素特征的训练数据进行建模,并在测试数据上进行测试
svc=LinearSVC()
svc.fit(x_train,y_train)
y_predict=svc.predict(x_test)
#使用PCA将64维的数据图像压缩到20个维度
estimator=PCA(n_components=20)
#利用训练特征决定20个正交维度的方向,并转化原训练特征
pca_x_train=estimator.fit_transform(x_train)
#转化测试特征
pca_x_test=estimator.fit_transform(x_test)
#使用LinearSVC对压缩后的20维特征的训练数据进行建模,并进行预测
pca_svc=LinearSVC()
pca_svc.fit(pca_x_train,y_train)
pca_y_predict=pca_svc.predict(pca_x_test)
#原始像素特征与PCA压缩重建的低维特征,在相同配置的支持向量机模型上识别性能差异
from sklearn.metrics import classification_report
print '原始数据',svc.score(x_test,y_test)
print classification_report(y_test, y_predict,target_names=np.arange(10).astype(str))
#PCA
print 'PCA降维',pca_svc.score(pca_x_test,y_test)
print classification_report(y_test, pca_y_predict,target_names=np.arange(10).astype(str))

