卷积神经网络 3 经典的模型
经典的卷积神经网络模型是我们学习CNN的利器,不光是学习原理、架构、而且经典模型的超参数、参数,都是我们做迁移学习最好的源材料之一。
1. LeNet-5 [LeCun et al., 1998]
我们还是从CNN之父,LeCun大神在98年提出的模型看起。
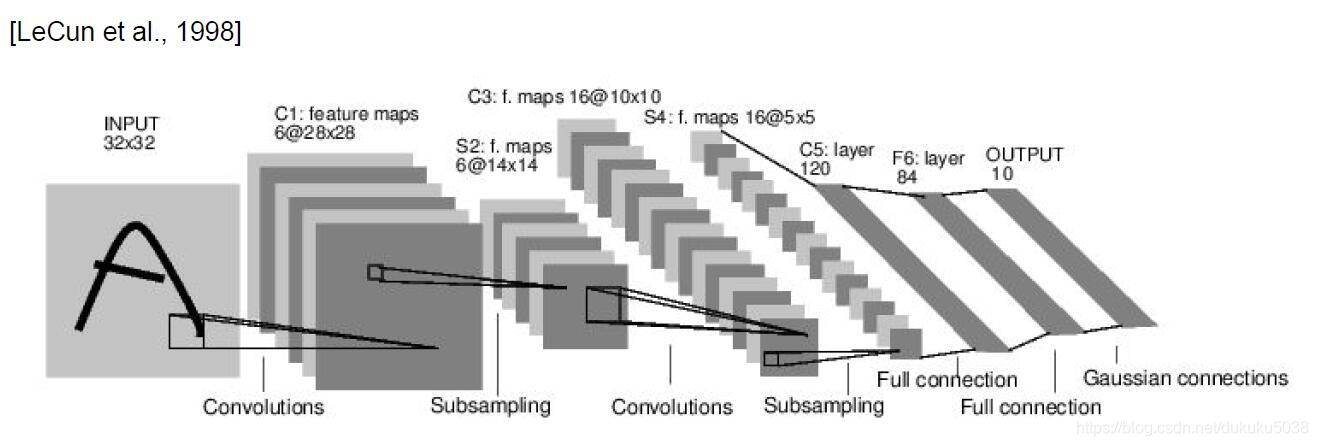
参数有:Conv filters were 5x5, applied at stride 1
Subsampling (Pooling) layers were 2x2 applied at stride 2
架构是:[CONV-POOL-CONV-POOL-CONV-FC]
2.AlexNet [Krizhevsky et al. 2012]
这个模型是2012年Imagenet 夺冠的模型,从这个模型开始,可以说,深度学习的大幕已经拉开!
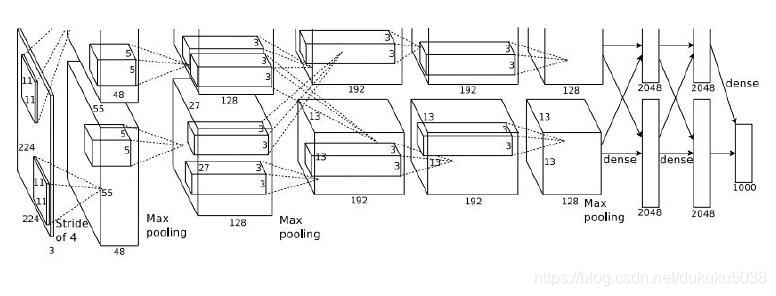
模型参数:
(1) First layer:
Input: 227x227x3 images
(CONV1): 96 11x11 filters applied at stride 4,
Output volume [55x55x96]
这一层的所有的参数是:(11113)*96 = 35K
(2) Second layer(Pooling):
3x3 filters applied at stride 2
Output volume: 27x27x96
这一层不需要参数
…
(3) 整个架构 (Pooling):
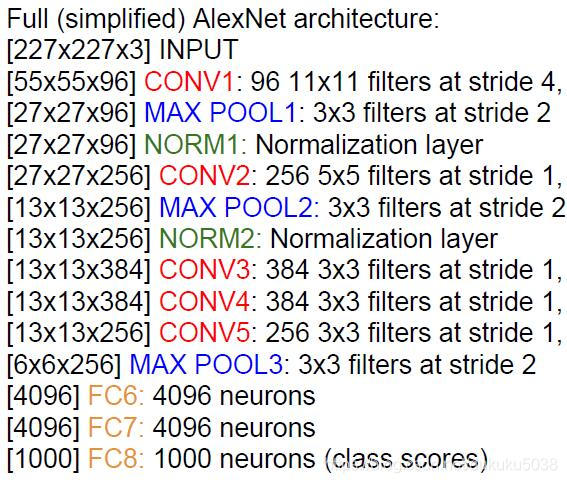
(4) 模型特征和超参数设置:
- first use of ReLU
- used Norm layers (not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Momentum 0.9
- Learning rate 1e-2, reduced by 10
manually when val accuracy plateaus - L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% -> 15.4%
3.VGGNet [Simonyan and Zisserman, 2014]
模型的特点:
*Only 3x3 CONV stride 1, pad 1 and 2x2 MAX POOL stride 2;
将11.2% top 5 error in ILSVRC 2013降低到 7.3% top 5 error;
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~2 for bwd)
TOTAL params: 138M parameters
模型具体的设置和参数:

4.GoogLeNet[Szegedy et al., 2014]
ILSVRC 2014 冠军(6.7% top 5 error)
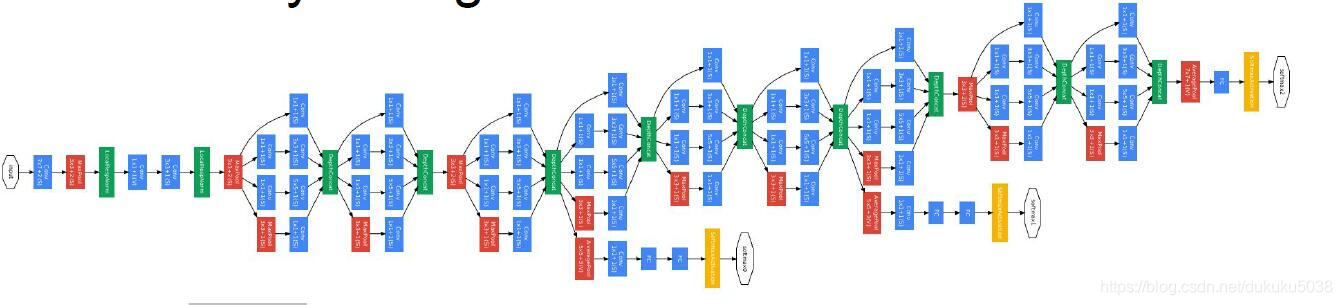
模型特点:
- Inception Model
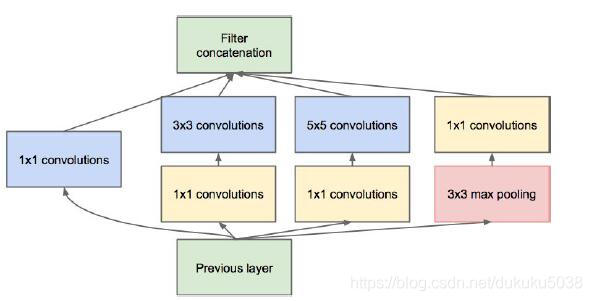
- No FC layer
- Only 5 million params!(Removes FC layers completely)
- Compared to AlexNet:
12X less params
2x more compute
6.67% (vs. 16.4%)
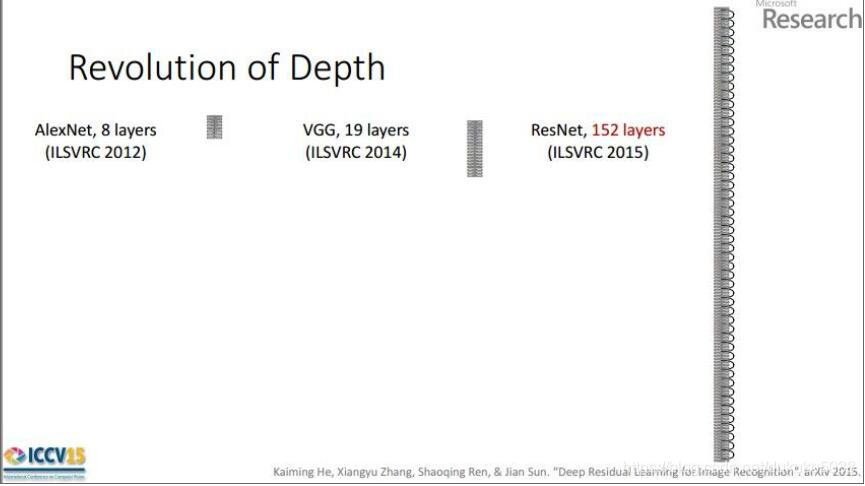
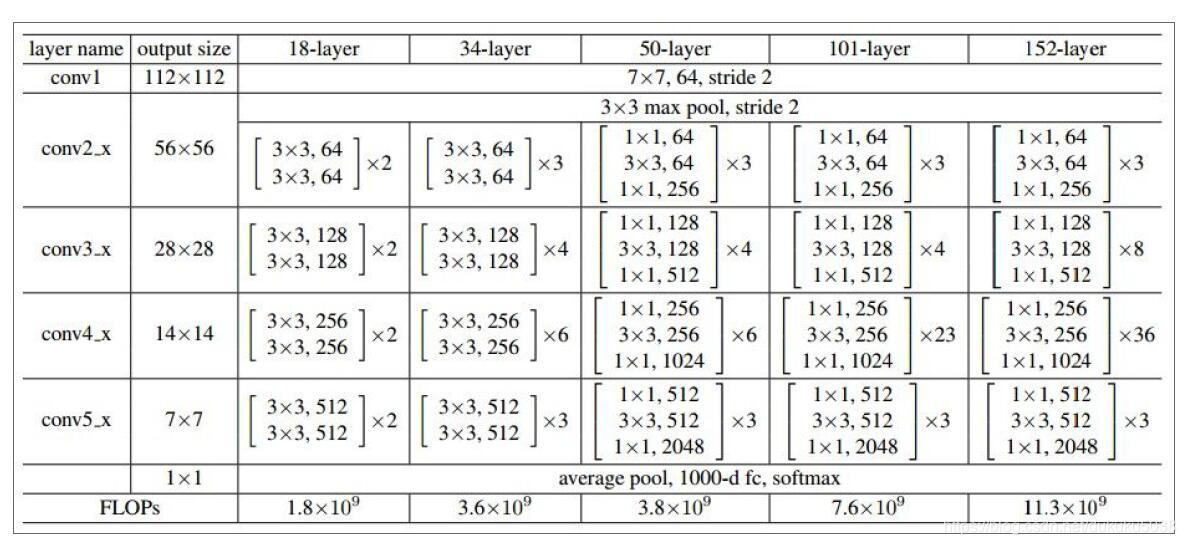
5. ResNet [He et al., 2015]
ILSVRC 2015 winner (3.6% top 5 error)
迄今为止,我见过的最深的模型!152层!!!!!!!!!!!
- 2-3 weeks of training on 8 GPU machine
- at runtime: faster than a VGGNet! (even though it has 8x more layers)
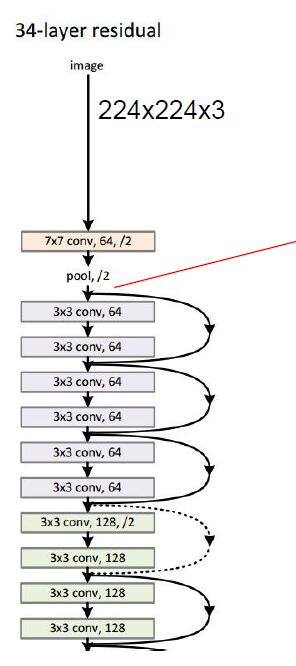
(1) 系统结构
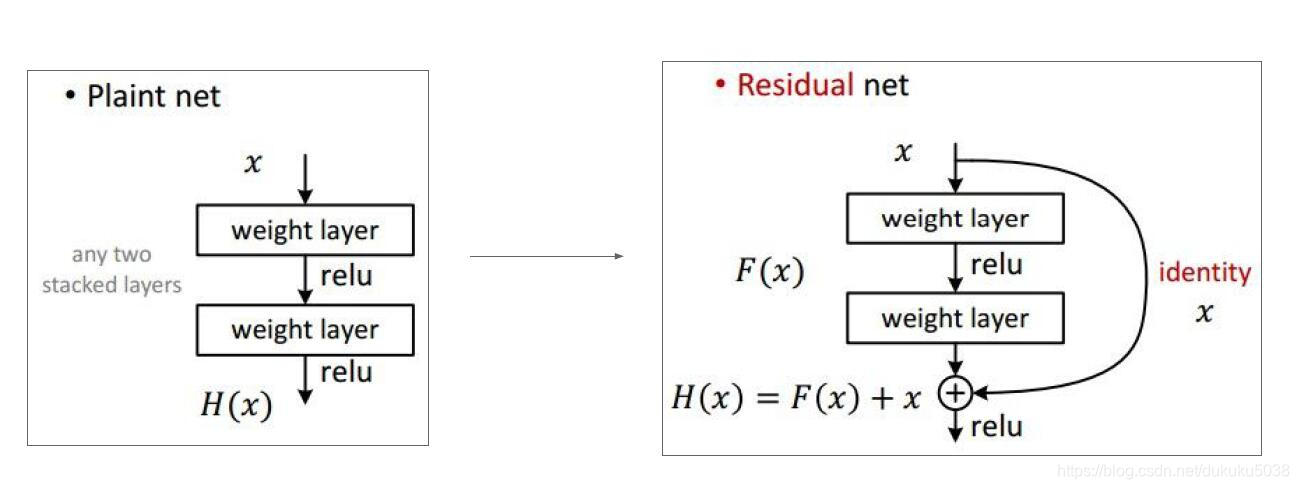
(2) Res 残差的概念
(3) 超参数设置 - Batch Normalization after every CONV layer
- Xavier/2 initialization from He et al.
- SGD + Momentum (0.9)
- Learning rate: 0.1, divided by 10 when validation error plateaus
- Mini-batch size 256
- Weight decay of 1e-5
- No dropout used
(4) 层详情
本专栏图片、公式很多来自台湾大学李弘毅老师、斯坦福大学cs229,斯坦福大学cs231n 、斯坦福大学cs224n课程。在这里,感谢这些经典课程,向他们致敬!