why TVM
要让AI芯片支持深度学习架构(如TensorFlow, MXNet, Caffe, and PyTorch,芯片都有自己的指令集(例如汇编,C语言),要将深度学习架构等部署到芯片上就需要将深度学习架构中的这些代码编译成芯片支持的指令集,所以要从头到尾设计一套软件栈,做一套全栈的优化。
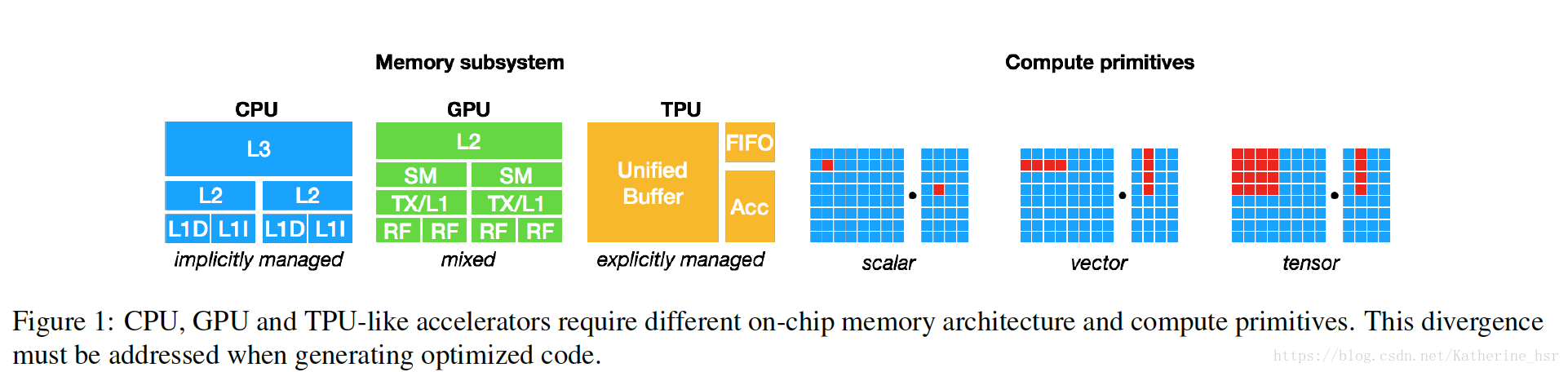
所以现在的许多深度学习的架构只能在某一些厂商的GPU设备上获得加速,这种支持依赖于特定的GPU库,当未来越来越多的加速器出现时,硬件设备的厂商对于深度学习架构的支持便会变得越来越困难。同时不同的硬件设备的内存构造和计算能力也有很大的差异,如图:
TVM的目标是很容易的将深度学习架构部署到不同内存结构、计算单元的所有的硬件设备中(包括GPU,FPGA 和 ASIC(如谷歌 TPU),也包括嵌入式设备),TVM架构图如下:
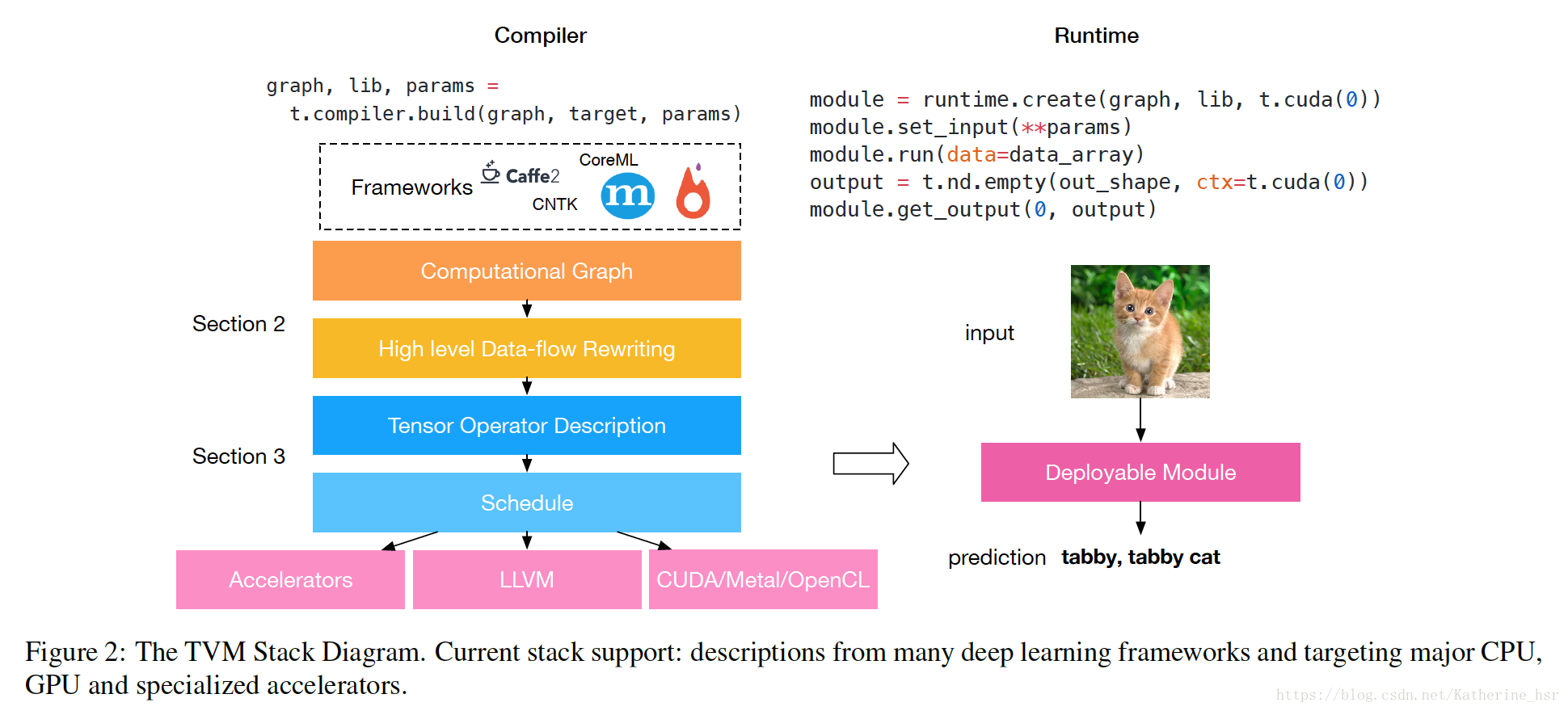
TVM是一个端到端优化堆栈,该端到端优化编译器堆栈可降低和调整深度学习工作负载,以适应多种硬件后端。TVM 的设计目的是分离算法描述、调度和硬件接口。通过将调度与目标硬件内部函数分开而进行了扩展。这一额外分离使支持新型专用加速器及其对应新型内部函数成为可能。
TVM做了两个优化层:计算图优化层和一个张量优化层。TVM将这些优化层结合,并且生成优化的代码去连接上层的深度学习框架和下层的硬件设备。通过结合这两种优化层,TVM 从大部分深度学习框架中获取模型描述,执行高级和低级优化,生成特定硬件的后端优化代码,如树莓派、GPU 和基于 FPGA 的专用加速器
Optimizing Computational Graphs
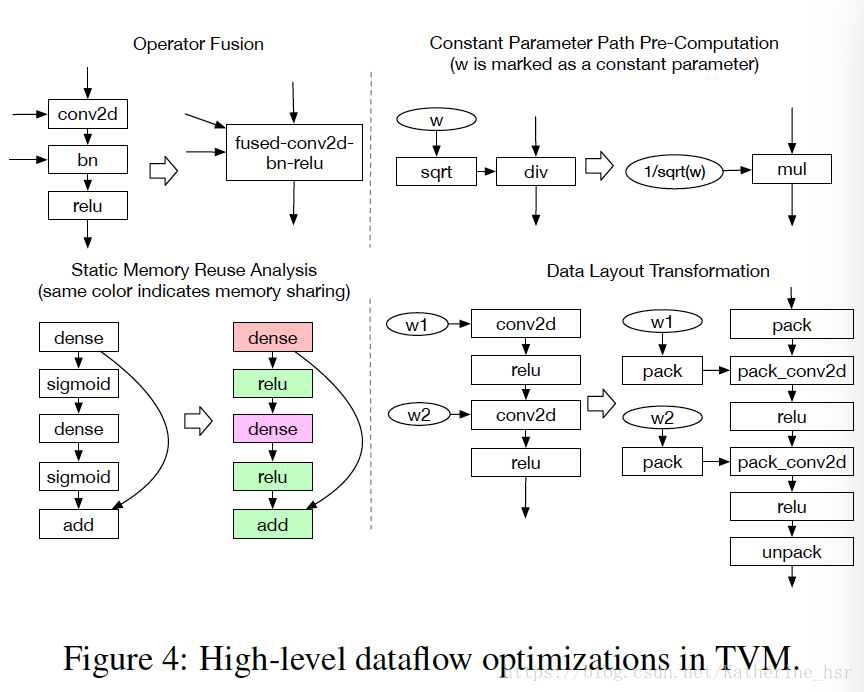
- Computational Graph:计算图,计算图用于描绘一个整体的计算任务,会根据图中的计算任务提前分配内存,所以在计算图中做优化,即将原来的计算图转换为相同效果的计算图。例如有些计算可以提前进行然后存储在内存中在需要用的时候直接调用,这样就可以节省一部分执行的时间。下图描述了一些计算图优化的例子:
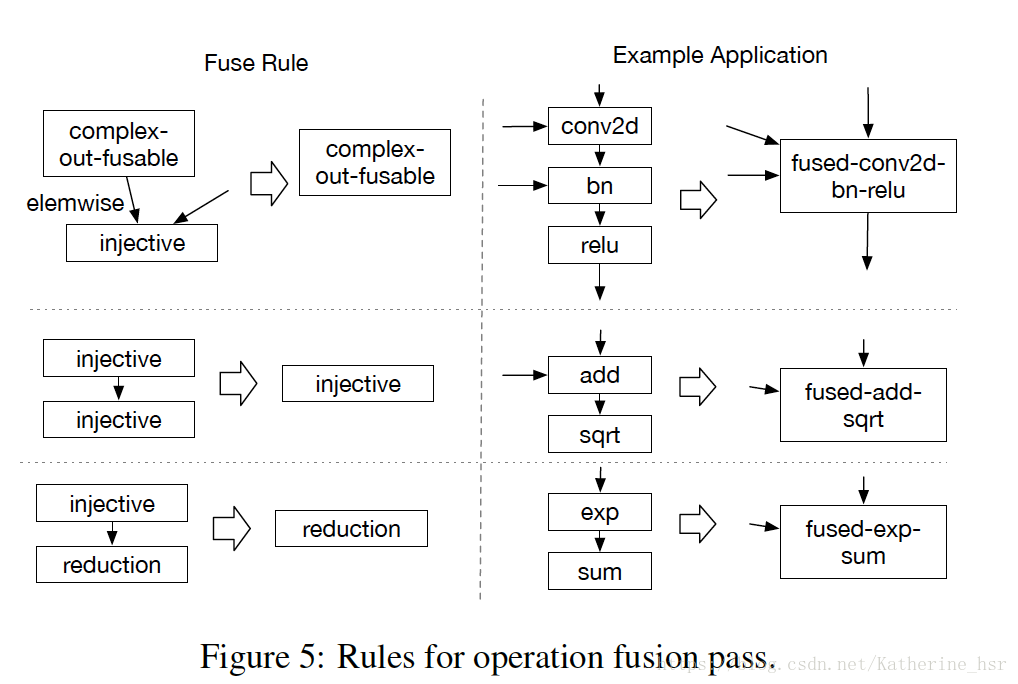
- Operator Fusion:操作符融合,将许多操作符放到一起进行计算免除了将中间结果写到全局内存中是另一个可以节省运算时间的优化,尤其是在GPU以及一些加速器中。
下图描述了一些操作符融合的示例:
- Data Layout Transformation:数据布局转换,Tensor操作是计算图的基本操作符,Tensor中涉及到的运算会根据不同的操作符拥有不同的数据布局需求。例如,一个深度学习加速器可能会使用4x4张量操作,所以需要数据切割成4x4的块来存储以优化局部访存效率。下图展示了一个矩阵如何布局,这种布局能够适应计算2x2张量操作。优化数据布局从指定每一个算子更好的数据布局开始,这些更好的数据布局决定了他们在硬件中的部署实现。
- Limitations of Graph-Level Optimizations:图级优化的局限性,虽然计算图优化可以提高计算效率,但是当前只有少量的深度学习框架支持操作符融合。随着越来越多支持正交基的操作符被引进,能够被融合的Kernel数量正在急剧增大。但是当出现越来越多的硬件后端时,为不同的数据布局方式、数据类型和硬件内联函数手动适配的方案已经变得不可行的。为此,TVM提出了一种代码生成的方案。

优化张量算子
- Tensor Expression Language:张量表达语言,下图描述的就是TVM中所使用的张量表达语言,每一个计算操作都包含输出张量的shape,每一个表达都描述了怎样去计算每一个输出张量的元素。
张量表达语言支持普通的编程语言(例如C)中的算法和数学操作符,同时在TVM中引入了一个可交换的简化算子使其运用在多线程的调度中。之后我们还会引进一个高层次的扫描操作符,这个操作符能够把基础计算操作符联合成循环计算。 - Schedule Space:调度空间,给定一个张量表达,部署到每一个硬件终端上使其实现本身的功能仍然是很困难的。下图描述了应用在CPU,GPU,和深度学习加速器上的优化。
每个经过底层优化的程序针对不同硬件后端采用不同的调度策略的联合,这也为Kernel设计者带来了很大的负担。所以通过借鉴Halide,我们采用了解耦计算描述和调度器优化两个过程。调度器会根据硬件后端采用特定的规则将计算描述向下转换成已优化的硬件实现。
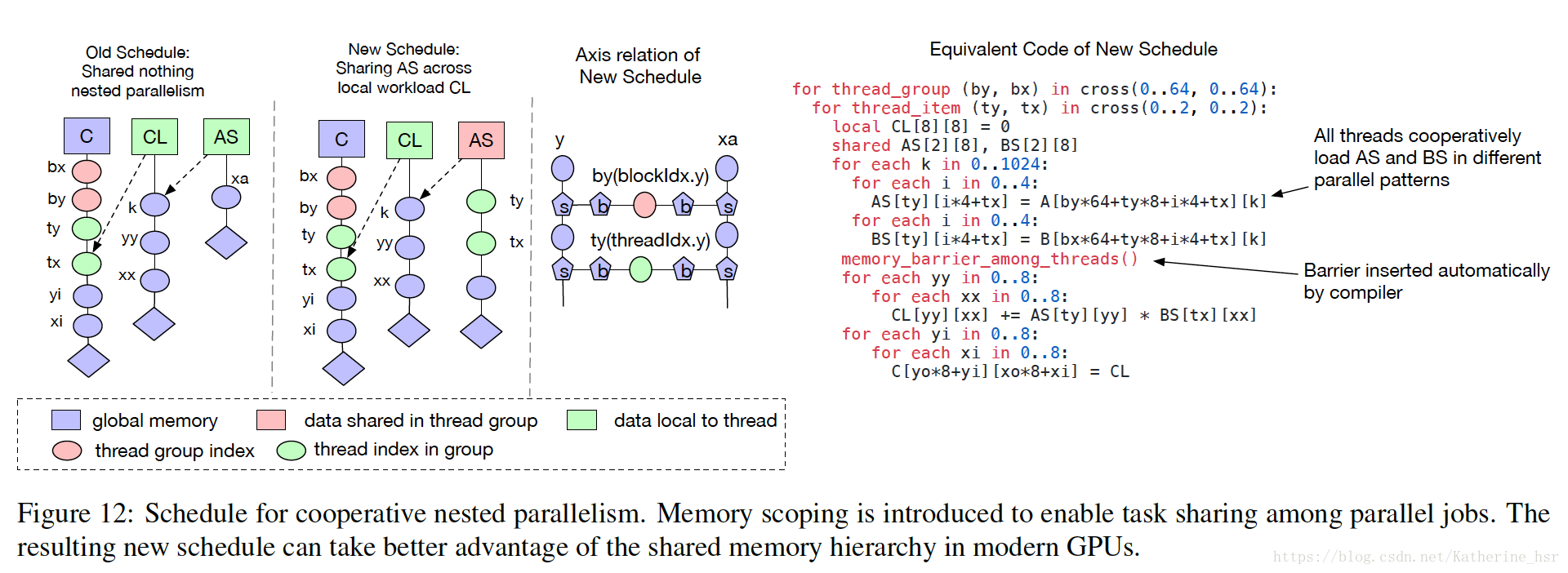
TVM中优化了调度算法,提供了有效的调度基元,使其较原来的优化过的调度算法的计算量减小了很多。 Nested Parallelism with Cooperation,协作式嵌套并行化,并行运算是对于提升在深度学习工作负载中计算密集型工作效率的关键。现在大部分的GPU都提供了并行运行,所以需要我们使用在编程中使用并行的方式去提高工作效率。在TVM中使用并行调度基元去并行计算一个任务,每个并行任务都能够被递归地细分到一个子任务以实现多级线程。在计算过程中一个工作线程不能观察到相同计算阶段内的相邻线程的数据。这些并行的线程在join阶段(就是当一个子任务完成了并且下一个阶段需要之前阶段所产生的数据的时候)才发生交互,这种编程模型禁止线程在相同计算阶段内进行协作,下图提供了一个矩阵乘法操作的例子来说明这种局限性:
为了解决这种操作带来的局限性,一个更好的替代方案是线程在获取数据时采用shared-nothing的方式。这种模式在很多GPU语言(CUDA, OpenCL and Metal)中广泛的使用,但是还没有在调度基元中使用,TVM在调度中引入了memory scopes使得一个阶段就能够被标记为shared;没有memory scopes,这个阶段就会被标记为本地线程。Tensorization: Generalizing the Hardware Interface,张量化:生成硬件接口。深度学习的工作任务中有高强度的算法运算,这些运算可以分解为张量运算(例如矩阵和矩阵的乘法,一维卷积操作),所以近些年来越来越多的使用张量来进行运算。但是这些计算本质上是很不相同的,例如矩阵与矩阵的乘法,矩阵和向量的product以及一维的卷积操作,这些不同的计算都使张量算子调度更加困难。
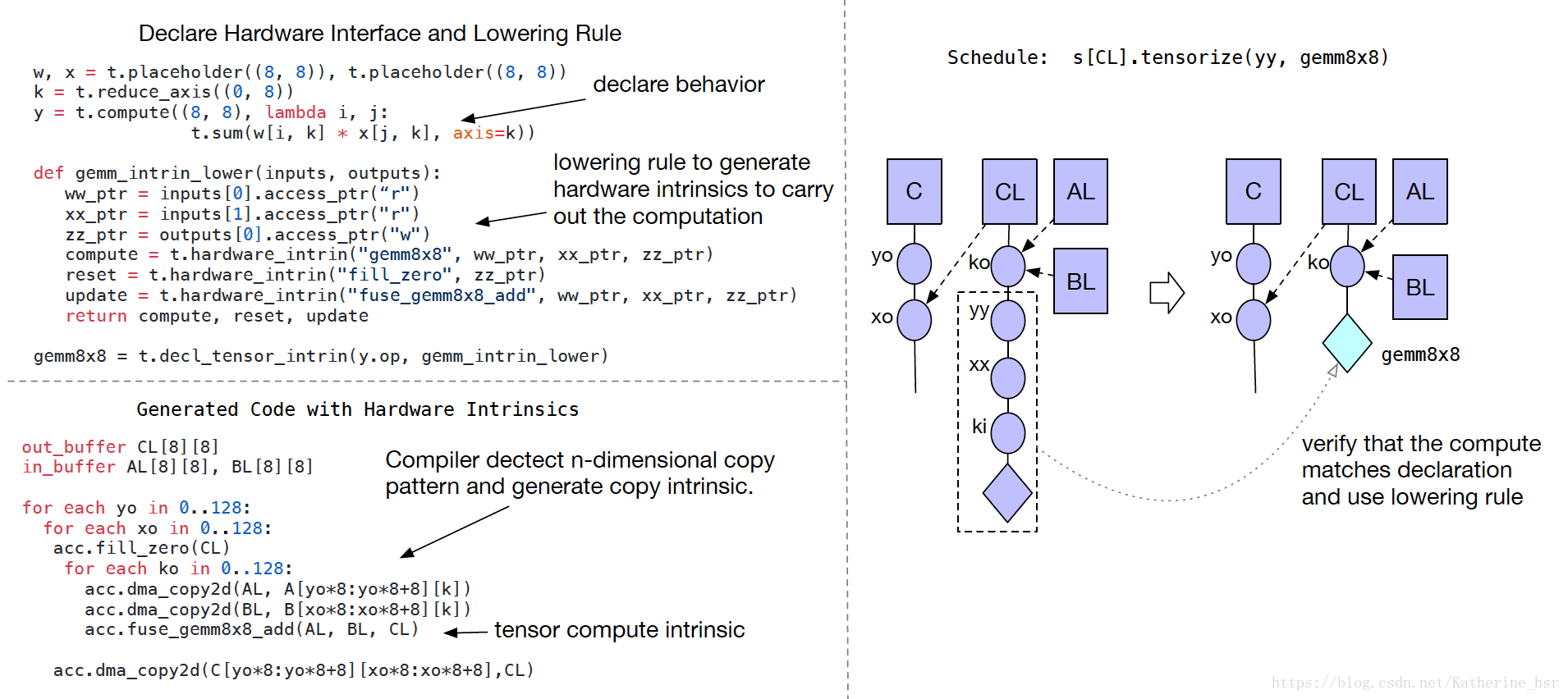
张量的形式与向量的形式特别不同,张量计算的输入是多维的、固定的或者是可变的长度,并且有不同的数据布局。所以我们不能借助于一系列固定的算法就不适用了,因为新的深度学习加速器采用特殊的Tensor指令。为了解决上面的问题,我们从调度器中分离了硬件接口。TVM引进了一套Tensor内联声明机制。可以使用Tensor表达式语言来声明每个新的硬件内联的行为,和给他分配底层原语是一样的。另外TVM引进了一个调度器基元Tensorization来作为基元的计算单元
如图所示:
Tensor表达式语言能够同时描述用户准备的计算描述信息和硬件暴露接口的抽象信息。Tensorization把调度器从硬件基元中解耦出来,这样能够使TVM更容易扩展新的硬件架构。Tensorization调度器生成的代码经过实践具有很高的计算性能:将复杂的操作分解成一系列重复的微型Kernel调用。因此能够使用Tensorization基元来发挥手工制作的汇编微型Kernel的性能优势,这种方法在一些硬件平台上是非常有益的。- Compiler Support for Latency Hiding:编译器支持延迟隐藏。延迟隐藏是通过重叠内存计算操作去使内存利用率和计算效率最大化。针对不同的硬件终端它需要不同的策略。在CPU中通过同步多线程来实现延迟隐藏,在GPU中通过快速的切换线程去最大化利用功能单元,在某些深度学习加速器中经常将延迟隐藏转移到堆栈编译器中去完成。在硬件设备上实现延迟隐藏的一种方式是直接控制硬件任务的执行,就是当一个任务完成时另一个独立的任务可以进行的时候,便会在pipeline stages中同步指令或者重写数据。但是这种与硬件直接交互的形式的开销是很大的。为了减少这种开销,TVM提供了一种虚拟的线程调度形式,编程者可以指定一个数据并行程序,然后TVM可以自动的转换成底层的数据依赖程序,转移过程如下图:
上图的算法开始是一个high-level parallel program,然后插入了必要的同步指令去确保每一个算子每一个在线程中的正确的执行顺序,最后这些虚拟线程的操作融合成一个单独的线程。



Code Generation and Runtime Support
对图和调度进行优化后,剩下的任务就是产生能在目标平台以及能够部署在硬件设备上的代码了。
1. Code Generation:TVM通过对前端框架的硬件如所用到的CPU,GPU进行分析,将高级语言转换成硬件设备可以支持的C语言。
对于一个特定的多元数据流声明,坐标系相关的超图和调度树,我们可以通过迭代遍历调度树的方案生成Lowered代码,并且推断出输入Tensor的依赖范围(使用坐标系相关的超图),接下来生成循环嵌套的low-level代码。low-level代码是通过类C的循环程序具象化而来,在这个过程中使用了一个Halide循环程序数据结构的变体,我们也使用了Halide常用的lowering primitives,像是storage flattening,循环展开,对于GPU和特定深度学习加速器而言,则使用了同步点检测、虚拟线程注入、模块化生成机制。最终,循环程序被翻译成LLVM/CUDA/Metal/OpenCL源代码
2. Runtime Support For GPU programs: TVM会独立的构建host端和device端的模块并且提供一个运行时模块系统来启动Kernel。代码生成算法然后将加速器程序翻译成一系列Runtime API。
3. Autotuning:TVM提供一套新颖的优化框架,这套框架能够为深度学习系统编译高性能底层实现,使得像高维卷积、矩阵乘法和深度卷积这样的复杂操作可以被一套调度器模板进行自动调优。
4. Remote Deployment Profiling:为了嵌入式设备,TVM设计了一套方便性能分析和自动调优的基础设施。传统情况下,嵌入式开发一般是在主机上进行交叉编译然后复制可执行文件到目标设备上执行,上述编译、运行和性能分析的工作都需要手动进行。在编译器堆栈中我们提供了一个远程程序调用:通过RPC接口,我们能够完全在host端完成上面的所有步骤,这样的方式可以极大地加快在嵌入式设备和基于FPGA的加速器上的优化工作。如下图:

Evaluation
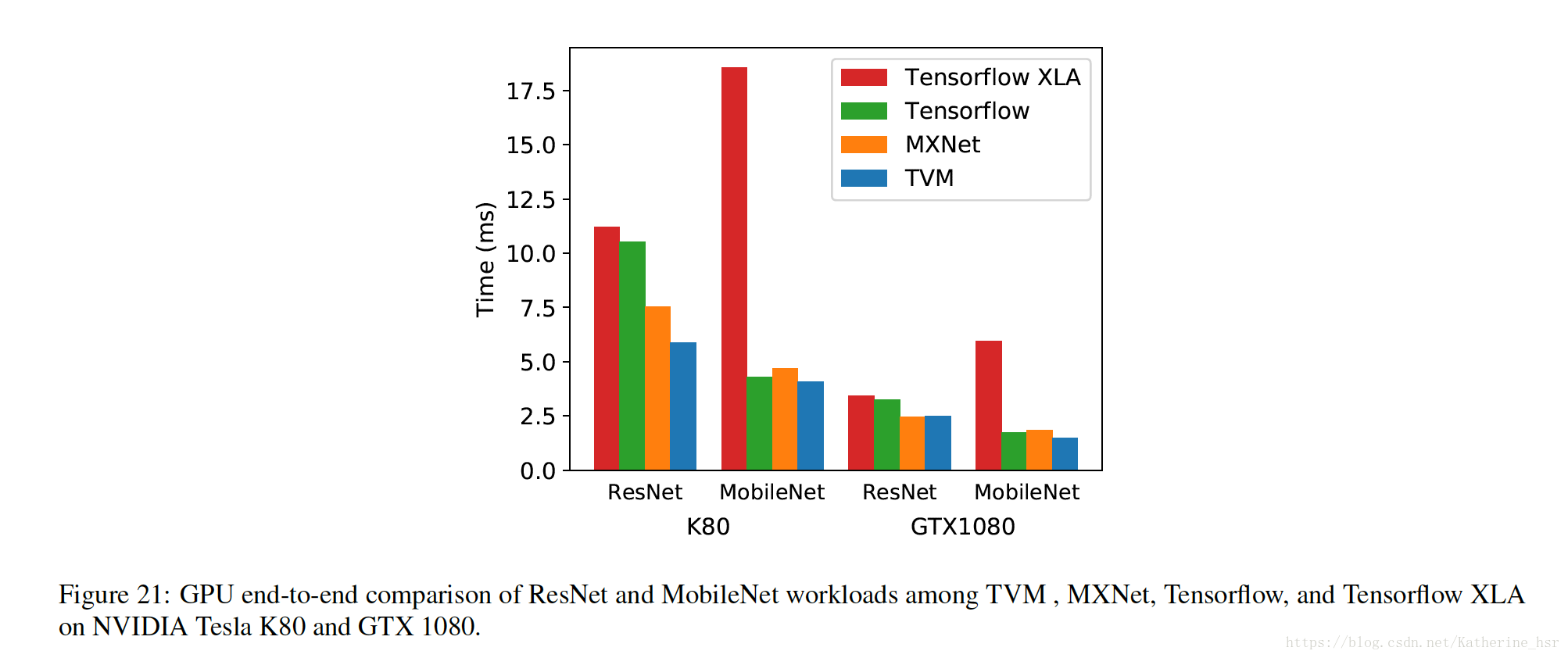
下图为GPU Evaluation
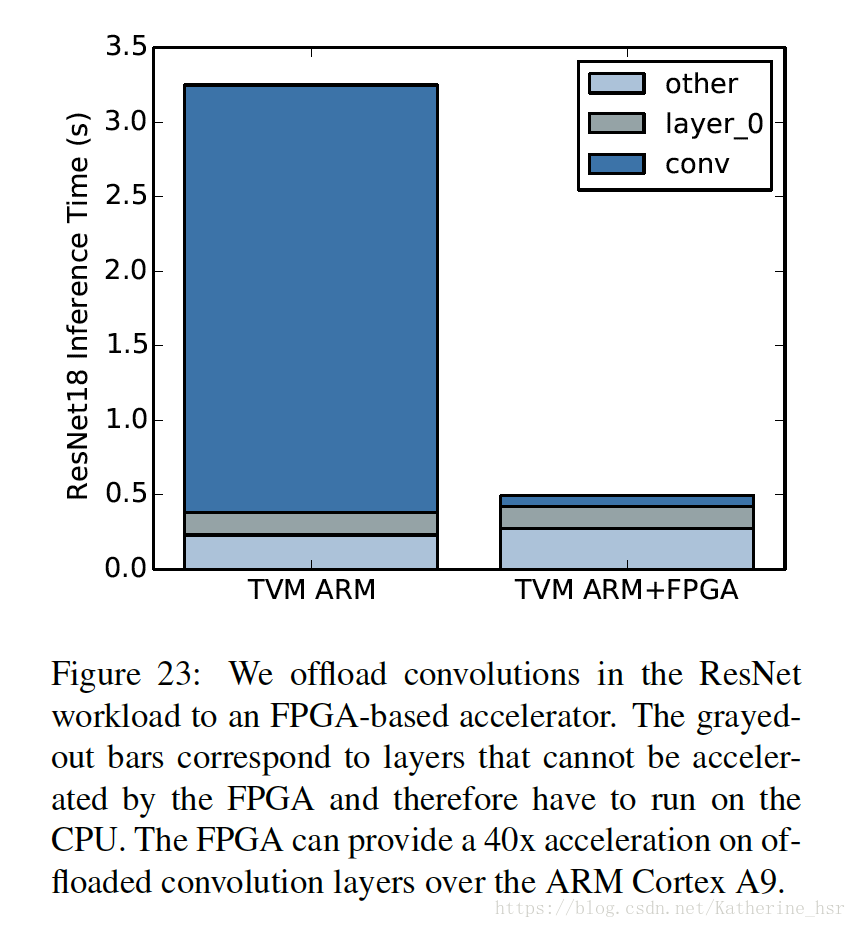
下图为FPGA Accelerator Evaluation