接上篇......
Optimization
之前提到Loss函数用于衡量估计值(scrore)和真实值(label, 如鸟, 猫啊)的差距(Loss),这个估计值是基于某个W(weight)然后代入score函数算出来的。而Optimization函数是用来寻找一个更好的W能让loss尽可能的低。
其实就是用于寻找一个更合理的W,目的是让Loss尽可能的低,这样就更接近真实值。对这种情形在deep learning里有一个广泛使用的比喻:
一个蒙着眼睛的探险者在山谷间探险,试图找到山谷的最低点,想想有点模糊,我们带入一个实际中的例子看一看:比如CIFAR-10数据集,每张图片是reshape成Single column dimension是3073x1(32x32x3+1), 一共有10个类型,那么可知W是一个10x3073的矩阵,那么以为这W有30730个可以影响到loss的参数,就好比蒙眼的登山者可以向30730个方向探索以期达到谷底。
一般来讲有3种办法,从笨到聪明:
1. 随机查找(Random Search)
看这段代码:
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)循环1000次,随机生成W,然后用W计算loss,最后选取1000次得到最少loss的W作为最佳选择,这个方式其实很无脑,没有什么技巧性,就是试。使用这个W最终预测的正确率(accuracy)是15.55%
好像还不错,比瞎猜的概率10%要好些。
2. Random local search
这种方法聪明了点,核心思想是如果我们无法直接找到一个完美的W让loss最低,我们可以一步一步来,先找一个比当前W好一点点的new W,然后在找比new W好一点点的new new W,这样一步一步总能找到最好的W。这个想法很重要,最终大家都采用了这种思想。 看代码:
W = np.random.randn(10, 3073) * 0.001 # generate random starting W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)先随机生成一个W,然后循环1000次在这个W的基础上进行试探,注意跟上一个方法显著不一样的地方是:Random Search是随机生成1000次W进行loss计算,而Random Local Search是随机生成一个W,然后基于这个W进行优化。
继续看,在循环内,又随机生成了一个跟W同样shape的矩阵Wtry然后跟一个非常小的数(step_size)相乘最后跟W相加得到一个新的W,是用此新的W计算loss,如果比之前的loss小,取代之前的W。
这到底是干啥,用蒙眼探险者来理解比较简单,新的矩阵跟W同样shape(30730)好比是在这30730个方向(参数)上都做出试探(改变)然后乘以探险者一步的长度(很小的数step_size),这样来确定到底这个方向上的地势是不是低了(是不是loss变小了)。这就很好理解了。
这个算法中两个事情要注意:
a. Step_size将会是一个重要的pyper-parameter,它不能太大,也不能太小。还是用蒙眼探险者的例子讲,要探索低的方向,步长太小,就会导致进展太慢。步长太大容易错过地势更低的方向(比如说一个侧方向的下山路离你10米,你在试探方向的时候一步跨过了15米,是不是错过了这个下山路)
b. 在循环中随机生成的Wtry,因为是随机生成,表明试探没有倾向性是瞎试,而且每次试探都是在30730个方向上同时有动作。
这个方法最终的预测正确率(accuracy)是21.4%,比上一个好了很多。
3. 跟随梯度(Following the Gradient)
如果有人能指出下降最快(陡峭)的方向,蒙眼探险者就不用在所有的方向(30730)上进行试探,这样就事半功倍了对吧。
这个算法就是依据这样的想法,为我们指出方向的是数学,Loss function的梯度(gradient)。 结论是梯度方向是在当前点loss函数变化率最大的方向,至于为什么,看看下面文章:
https://www.zhihu.com/question/36301367
现在我们的问题就变成了求出Loss函数在W中每个参数(30730个)处的偏导数,然后对W进行update,这个update会使用求出的偏导数x步长,并且循环进行很多次。
首先,我们看看偏导的定义:

不解释哈,注意一点如果是多个变量的函数,求的是偏导,方法是让一个变量改变,其他变量保持不变。
求偏导有两种方法,我们一一介绍:
a. Numerically
这种方法即是简单的遵守上图所示的偏导的定义,看代码:
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient at
"""
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad会逐个计算W的所有参数(30730个)的在当前点的偏导,然后生成一个偏导矩阵和W的shape是一样的。
看看update的代码:
# to use the generic code above we want a function that takes a single argument
# (the weights in our case) so we close over X_train and Y_train
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
step_size = 10 ** -6
W = np.random.rand(10, 3073) * 0.001 # random weight vector
df = eval_numerical_gradient(CIFAR10_loss_fun, W) # get the gradient
loss_original = CIFAR10_loss_fun(W) # the original loss
print 'original loss: %f' % (loss_original, )
W_new = W - step_size * df # new position in the weight space
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss: %f' % (step_size, loss_new)注意,W是减去步长(step_size)x 梯度。
这种方法的缺点是计算太多,我们对W进行一次update需要调用30731次loss函数(30730个参数+原始W的loss计算),但在实际中,像W这样的参数成千上万,这么算效率是非常低下的,
这就有了另外一种方法:
b. Calculus
就是用数学公式来求导数,一份求导公式表:

一份和差积商求导法则:

我们用svm这个Loss函数举例:
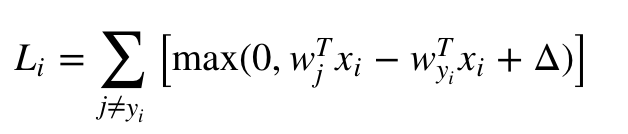
这是我们之前谈到过的,它主要部分是一个累加函数和一个max函数。分析下这个Loss函数:
首先是一个累加函数,展开就是L=y1+y2+y3, 那么对这个函数求导其实就是L’=y1’ + y2’ + y3’
再来观察里面max函数,max的求导就是max(a, 0), a>=0, 求导为1,否则为0。这个很好解释,导数其实就是函数(这个例子终究是loss函数)在此处的增长率,如果对函数结果的贡献率为0,那导数势必也是0,看看max(a, 0)如果a<0, max的结果就是0,没a什么事,所以说在此处a对输出的贡献率为0,那对它求导就是0了。至于为什么a>=0是导数为1,查下上面给出的公式。
好的,接下来我们看看max里面的部分:Wjtxi - Wyitxi + △,变量是Wj和Wyi, 为啥不是xi呢,记住我们是在努力寻找一个合适的W来降低Loss,所以变量是W。因为Wj和Wyi在函数中是不一样的形态,对函数结果的贡献率是不通的,所以求导的结果分成了两部分:
对Wyi的:
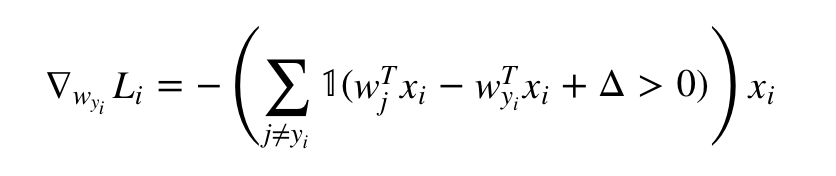
这个类似艺术字体1的符号表示如果括号内的计算结果为true,那么结果为1,如果为false,结果为0.
查查上面的公式,你会理解这个答案的。
对Wj的:
![]()
意义解释同上。
这下我们通过导数计算得到了所有W的导数,分为两类:Wyi(正确分类的W,一条 1 x 3072), Wj(错误分类的W,很多条 (n-1)x3072)
剩下的事情就简单了,update W啊, 记得是减不是加啊。
待续......
好像少讲了了链式法则,下回吧。