来看看这篇号称要替代BP算法的文章到底在讲啥吧!!!!
论文地址
摘要
随着神经网络向着更深更广的方向发展,学习硬阈值的神经网络变得越来越重要。一方面为了神经网络的量化(quantization),可以大幅度的减少时间和能量消耗;另一方面为了构建大型的深度神经网络的集成系统,里面存在着不可导的组件,因而为了有效的学习,必须避免梯度在传递过程中消减至零或者发散至无穷。然而,梯度下降法并不适用于硬阈值的神经网络,所以我们并不知道该怎么学习这样的网络。我们提出,为硬阈值神经网络的隐藏层设置学习目标(target)来减小损失函数,这样一个问题实质上是一个离散优化问题,因而是可解的。给定了每一层的学习目标,神经网络就分解成了一层一层独立的感知机(perceptron),便可以用标准的凸优化方法来解决。据此,我们提出了递归小批算法(recursive mini-batch algorithm)来解决硬阈值深度神经网络的学习问题,并指出STE(straight-through estimator)可以看作本算法的一个特例。在实验中,我们展示了,新算法和STE相比,在经过一些设定之后提高了AlexNet、ResNet-18在ImageNet上的分类准确率。
关于神经网络最初的研究工作,是用单层的硬阈值神经网络做分类任务,即感知机模型。所谓硬阈值就是指激活函数是一个阶梯型函数,比如符号函数sign(x)。硬阈值函数的毛病在于它的导数处处为零,只在函数跳跃的地方有个无穷大的导数,这样的性质是没有办法使用BP算法的。于是人们后来想到用软阈值函数,比如sigmoid,tanh,relu等方便求导的函数,在此基础上运用误差反向传播算法,神经网络便如鱼得水风靡当下。
但是随着神经网络越来越深越来越臃肿,于是出于为神经网络量化(quantization)的考虑(暂时不懂何谓量化,可能是用低精度代替高精度的轻量化?),便开始研究硬阈值深度网络的可行性。选用硬阈值的理由很直接,硬阈值函数只有两个离散的输出结果,计算起来非常省时省力,而软阈值的输出是连续的,甚至还要做指数运算。出于省时节能的考虑,在牺牲部分精度的前提下节省时间和能源是非常合理的。而且硬阈值函数的输出大小和输入是独立的,因为输出就是两个离散值,所以可以有效避免软阈值神经网络的梯度耗散或发散的问题,解决了低精度的网络在训练中出现的问题。这对于构建大型的神经网络是至关重要的。
相关数学定义
给定数据集
其中输入
一个
其中
定义1:
一个数据集

这是一个很强的条件,以至于简单的XOR函数都不是线性可分的,使得感知机不能用来学习XOR函数。
定义2:
对于数据集
命题1:
对于数据集
命题2:
对于数据集
命题3:
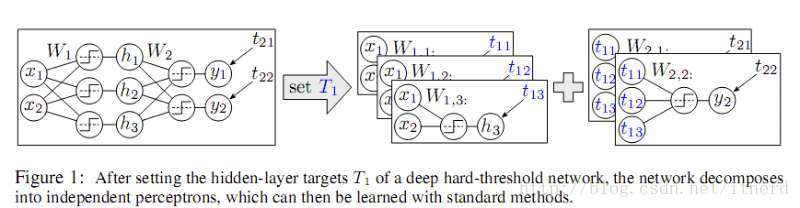
硬阈值神经网络在设置逐层学习目标
未完待续。。