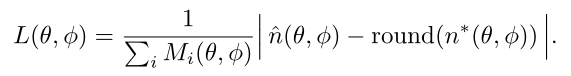图像来源
- wide field-of-view (FOV) cameras on an omnidirectional rig
- 文中具体为4个刚耦合的鱼眼相机
方法
- 1.将输入的鱼眼图像提取为unary feature maps
- 通过2D CNN实现
- 文中使用SegNet+dilated convolution
- 通过2D CNN实现
- 2.利用feature maps和内外参建立4D feature volume
- 通过 calibration + spherical sweeping实现
- 文中使用multi-fisheye camera rig模型 和 spherical sweeping方法
- 通过 calibration + spherical sweeping实现
- 3.计算matching cost volume
- 通过3D CNN正则化
- 4.depth estimate
- 使用softargmin完成
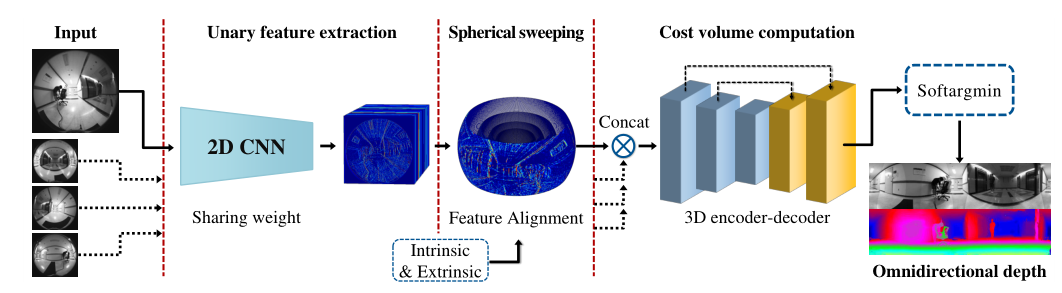
Multi-fisheye camera rig
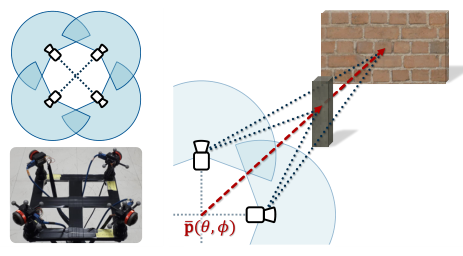
在多相机的中心,使用单位向量 p ⃗ \vec{p} p 表示整个rig的朝向: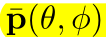
- 单位向量 p ⃗ \vec{p} p 指向的空间点X可以表示为:
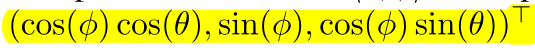
rig向量 p ⃗ \vec{p} p 指向的点集构成一个球体
- 当球半径为ρ,空间点X到像素坐标系x的映射表示为:
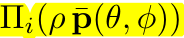
Spherical sweeping
通过设置camera rig模型中 p ⃗ \vec{p} p 的长度ρ(球半径),可以获得不同大小的球体
- ρ具体是通过逆深度 d n d_n dn来设置的
- 当逆深度为0到 d m a x d_{max} dmax,对应的深度范围为 1 d m a x \frac{1}{d_{max}} dmax1到无限远
设置N个球体,与鱼眼图(实际用的是对应的feature map)有映射关系:
Feature Learning and Alignment
2D CNN 获取的unary feature map表示为: U = F C N N ( I ) U=F_{CNN}(I) U=FCNN(I)
- 分辨率为 1 r H I × 1 r W I × C \frac{1}{r}H_{I}×\frac{1}{r}W_{I}×C r1HI×r1WI×C
- H I H_{I} HI和 W I W_{I} WI是输入图像的高度和宽度, r r r是缩小系数, C C C是通道数
Feature maps 通过上述的spherical sweeping方法warp到球上: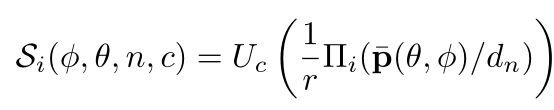
warping the feature maps具体使用:
- calibrated intrinsic and extrinsic parameters
- coordinate lookup table
- 2D bilinear interpolation i
对N个球体,为了确保相邻warped feature maps有足够的disparities,并减少运算开销
- 球体隔着用,即 n ∈ [ 0 , 2 , … , N − 1 ] n∈ [0,2,…,N− 1] n∈[0,2,…,N−1]
- the warped 4D feature volume S i S_{i} Si的大小为 H × W × N 2 × C H×W×\frac{N} {2}×C H×W×2N×C
此外
- 在反向传播过程中反向分布梯度。
- 计算每个输入图像的Mask M i M_i Mi,在wrap和反向传播中忽略有效区域之外的像素。
Network Architecture
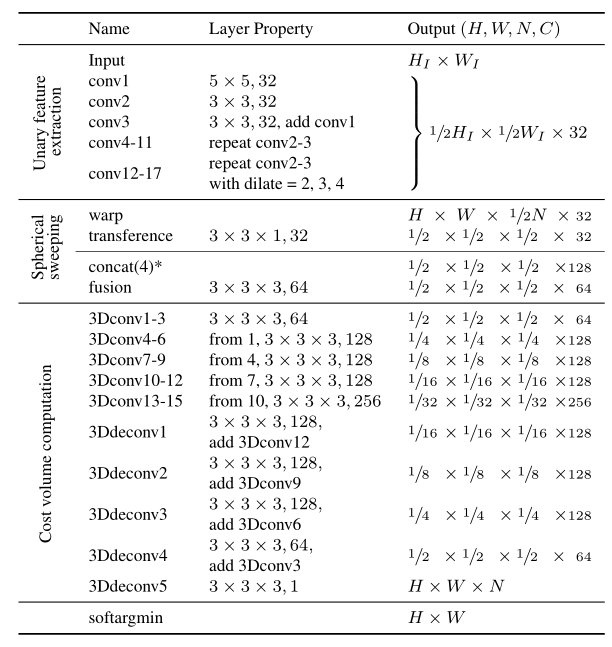
- 首先输入鱼眼灰度图,经过2D CNN 获得原图一半大小的feature map
- 随后feature aligned by spherical sweeping,通过 3 × 3 c o n v 3×3 conv 3×3conv transferred to
spherical feature ,将球面特征映射串联并通过 3 × 3 × 3 c o n v 3×3×3 conv 3×3×3conv融合为cost volume - cost volume再通过 3D encoder-decoder 来 refine 和 regularize
- 最后,应用softargmin获取逆深度:
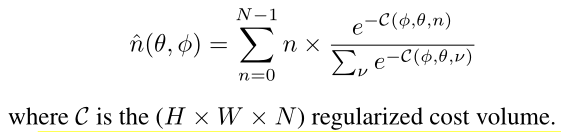
为了以端到端的方式训练网络,使用输入图像和ground truth inverse depth作为输入
loss为预测逆深度和其ground truth的absolute error loss :