版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014380165/article/details/72553074
YOLO算法有多种实现版本,论文中的作者的实现是在darknet框架下,可以参考链接:点击打开链接,darknet上已经更新到YOLO V2版本了。
这里主要讲Caffe版本的YOLO实现,主要采用yeahkun写的:点击打开链接,基本按照这个git里面的readme进行,但是因为整个流程操作起来步骤较多,所以将自己在调试过程中遇到的小问题记录如下:
大致步骤包括:1、编译。2、下载VOC数据集。3、生成list文件。4、生成LMDB文件。5、训练。6、测试
接下来详细展开
步骤1、下载项目并编译
这里说一下为什么要编译,可能你的电脑本来就已经编译好了CAFFE,其实原因是这样的,作者实现的时候可能自己定义了一些新的东西,比如新的层,所以需要重新将这些源文件编译,而不能直接用你原来电脑上编译好的CAFFE。另外编译也可以先进行,然后再去处理你的数据。
先把原来caffe-yolo-master目录下的Makefile.config.example复制并粘贴一份,并改名Makefile.config
可以在命令行中运行(要在caffe-yolo-master目录下运行):
cp Makefile.config.example Makefile.config
然后输入
make all
我在编译的时候出现如下问题:
错误1:

解决1:看错误是找不到hdf5,所以修改Makefile.config文件,把里面的这两行:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
替换成这两行:
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial/
还出现过类似这样的问题:
错误2:
解决2:
运行:make clean 清除原来的编译
make all 再编译一遍
步骤2、下载VOC数据
然后看yeahkun写的readme,看下图Data preparation。先是数据准备,这里面第二行是要把下载好的VOC地址链接到当前目录,是为了寻找方便,你也可以直接把VOC数据放在这个地方,不管怎么样,前提你得先自己把VOC数据下载好。然后执行get_list.py脚本,目的是从图像生成list,参考下面步骤3。最后是运行convert.sh,是从list生成lmdb文件,参考下面步骤4。总而言之,主要还是要改很多路径。

这是RBG大神的faster-rcnn的git,因为里面也用到VOC数据,原来以为VOC数据是一个文件夹,后来才知道有好几个,从文件名也可以看出来区分不了训练和测试,所以都下下来,然后都解压,因为默认解压后的名字都是VOCdevkit,所以这三个文件夹相互之间会自动融合成一个VOCdevkit文件夹。

这里大概看下VOC2007文件夹下面的内容:

Annotations文件夹里面是.xml文件,放的是对应图片的坐标和尺寸信息。
JOEGImage文件夹里面放的就是图片。
两个Segmentation开头的文件夹是和分割相关的,这里暂时用不到。
ImageSets文件夹里面的内容如下:
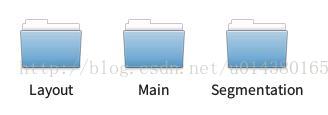
而我们主要用到Main文件夹里面的train.txt和test.txt,这两个txt文件保存的是对应图像的名称。
所以以上详细介绍了用到的数据的情况,是为了如果你要用自己的数据进行训练或测试,也需要把数据处理成这样的格式,这和图像分类不同,毕竟检测的内容多一点。
步骤3、生成list文件
这里因为我只用VOC2007,所以在get_list.py的大循环中只有VOC2007(原来还有VOC2012)
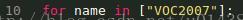
步骤4、生成LMDB文件
由./convert.sh实现,来看看convert.sh都写了什么,如下图。这里主要就是改路径。ROOT_DIR改成你的VOC图片的根目录,比如你的图片路径是a/b/VOCdevkit,那么这个地方就是a/b/。然后LMDB_DIR是你生成的lmdb要放的地方,lmdb这个文件夹没有的话要先新建,要不会报错。

数据准备好了以后,就要开始训练,但是训练之前要先编译CAFFE,然后才能运行nohup ./train.sh &命令(该命令也可以直接换成sh train.sh运行),编译请看步骤1。

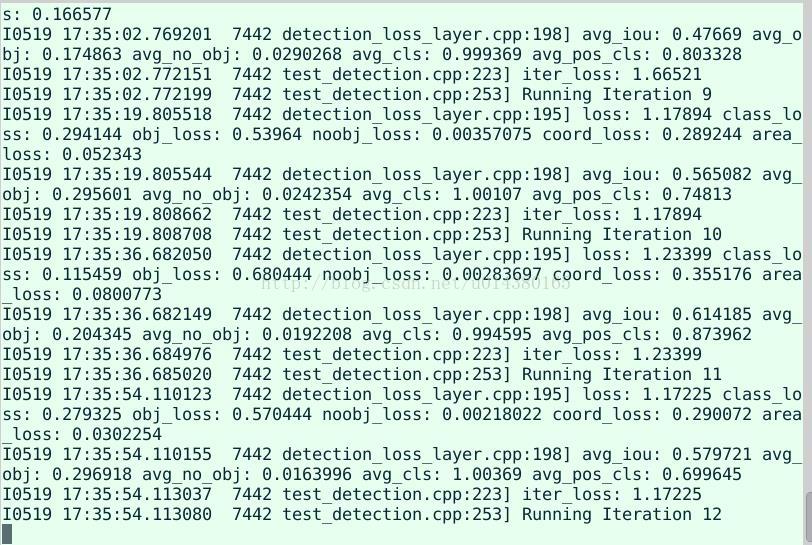
步骤5、训练
然后就能用了,可以运行train.sh,这里面要改的路径就和平时咱用的Caffe差不多,比如solver的路径,网络结构的路径,lmdb数据存放的路径等。另外,还需要从别的地方下载一个已经训练好的googlenet模型,可以从RBG的git上下,链接:点击打开链接,点击readme.md里面的那个链接就可以直接下,名字是bvlc_googlenet.caffemodel。所以训练的时候是在预训练的googlenet模型的基础上fine-tunning的。具体可以看train.sh文件。另外,train的网络基本上和googleNet差不多,主要的不同点在于数据层是作者新定义的,另外作者去掉了最后的dropout和全连接层,改用三个卷积层来实现,还自己定义了一个loss层:detectionloss层。
步骤6、测试
测试基本上和普通的caffe差不多,先从底下这个链接里面把以及训练好的模型下载下来(这个是在VOC上fine-tunning后的结果,注意跟前面那个imageNet模型的区别),然后直接sh test.sh就行,当然前提是你把test.sh里面的lmbd路径,solver路径以及model路径都设置对了才能运行。比较繁琐,但是不难。

正在跑的测试: