
arXiv-2016
Keras code:https://github.com/titu1994/Wide-Residual-Networks
文章目录
- 1 Background and Motivation
- 2 Advantages / Contributions
- 3 Method
- 4 Experiments
- 4.1 Datasets
- 4.2 Type of convolutions in a block
- 4.3 Number of convolutions per block
- 4.4 Width of residual blocks
- 4.5 Dropout in residual blocks
- 4.6 ImageNet and COCO experiments
- 4.7 Computational efficiency
- 5 Conclusion(owns)
1 Background and Motivation
ResNet 能训练上千层的网络,然而 each fraction of a percent of improved accuracy costs nearly doubling the number of layers, and so training very deep residual networks has a problem of diminishing feature reuse, which makes these networks very slow to train.
对 residual 的探索主要集中在
- order of activations inside a ResNet block(bottleneck)
- depth of residual networks
作者从 width 角度,开始了他的故事。。。
作者指出了 identity connection 的利与弊,
- 利:train very deep convolution networks
- 弊:as gradient flows through the networks there is nothing to force it to go though residual block weights,哈哈,容易让 residual block 成为混子了!
这一点(弊)不是作者天马星空的,论文《Deep networks with stochastic depth》就 randomly disabling residual blocks during training,the effectiveness of the approach 证实了作者的 hypothesis.
2 Advantages / Contributions
- 提出了 wide residual network,是 residual 在 width 方面探索的结果
- 提出了 a new way of utilizing dropout,insert between convolutional layer 而不是 inner residual block(《Identity Mappings in Deep Residual Networks》论文中是后者,效果不好,如下图所示),
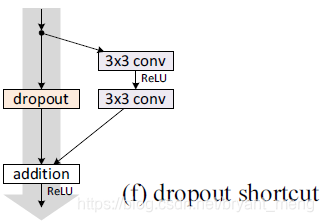
- state-of-the-art results on CIFAR-10, CIFAR-100, SVHN and COCO, 在 ImageNet 上也有 significant improvements!
3 Method
我们先回顾下 resnet 原版的结构(《Deep Residual Learning for Image Recognition》)
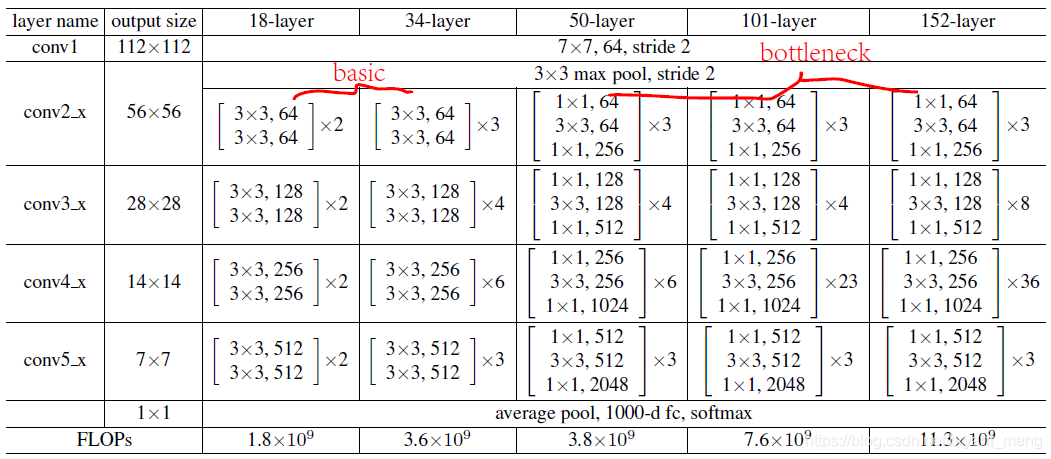
再回顾下 resnet 的 pre-activation 版本(《Identity Mappings in Deep Residual Networks》)

full pre-activation 结果最好,本博客介绍的论文都采用的是 (e)图的结构,也即 BN-ReLU-conv 的顺序
哈哈,马后炮的说(站在2019年下半年来评价2016年的成果),本文是一篇调参的论文,结构上并没有本质的变化,当然也可以说大繁至简哈(其实还是有超级多的收获的)!
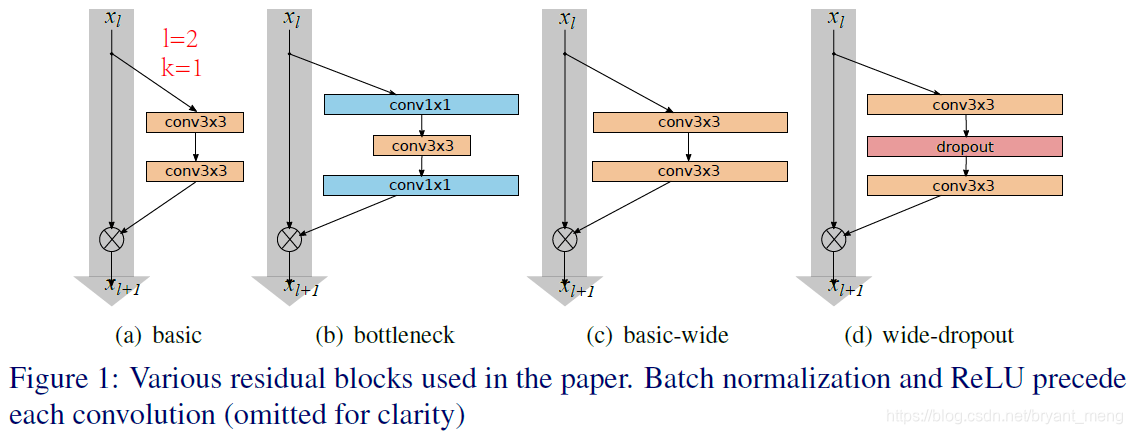
three simple way to increase representational power of residual blocks(上图就是 residual blocks):
- more layers per block——deepening factor
- widen layers by adding more feature planes——widening factor
- increase filter sizes(eg:3×3→5×5)
1)Type of convolutions in residual block
表示 residual block,
is a list with the kernel sizes of the convolutional layers in a block.

2) Number of convolutional layer per residual block
要保证 same parameters,所以 should decrease whenever increases.
3) Width of residual blocks
WRN- - : 是 total depth,widening factor
4) Dropout in residual blocks
wider 后参数更多了,作者 would like to study ways of regularization,采用的是如下形式的 dropout
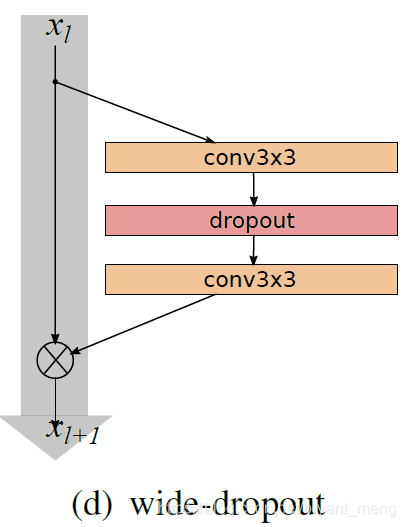
可以 help deal with diminishing feature reuse problem enforcing learning in different residual blocks
对比下《Identity Mappings in Deep Residual Networks》论文中的 dropout 的用法
作者在这里解释了下为什么要在 BN 的时候还用 dropout,反正读下去不是特别有感觉(不是特别赞同!也有观点说 bn 的作用就是 dropout,感兴趣的话可以探讨下这个问题!两者都有 regularization effect,这里抛砖引玉,不再赘述)
Residual networks already have batch normalization that provides a regularization effect, however it requires heavy data augmentation, which we would like to avoid, and it’s not always possible.
4 Experiments
4.1 Datasets
- CIFAR-10
- CIFAR-100
- SVHN
- ImageNet
- COCO
4.2 Type of convolutions in a block
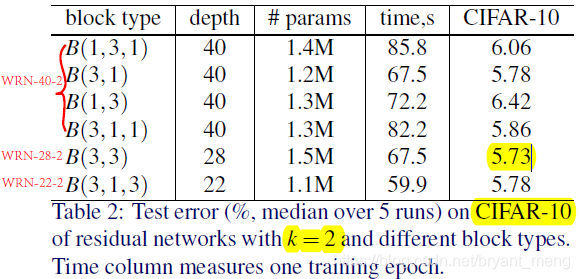
WRN-
-
:
是 total depth,widening factor
精度最高, 和 精度和其相仿,但是 parameters 少很多, 速度最快!作者后面都沿用 的方式!!!
4.3 Number of convolutions per block
deepening factor
(the number of convolutional layers per block)

WRN-40-2,same parameters(2.2M),3×3 convolution 堆叠
最好,比 , 都好,作者分析 this is probably due to the increased difficulty in optimization as a result of the decreased number of residual connections.也就是,同样的深度,depth = 40,由于 residual block 的深度不一样,所以 identity connection 的数量变少了,作者觉得这样不利于 optimization.
作者后面都沿用 的方式!!!
4.4 Width of residual blocks
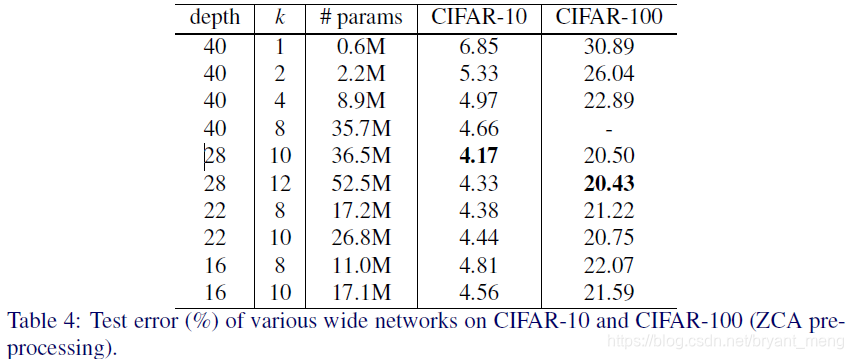
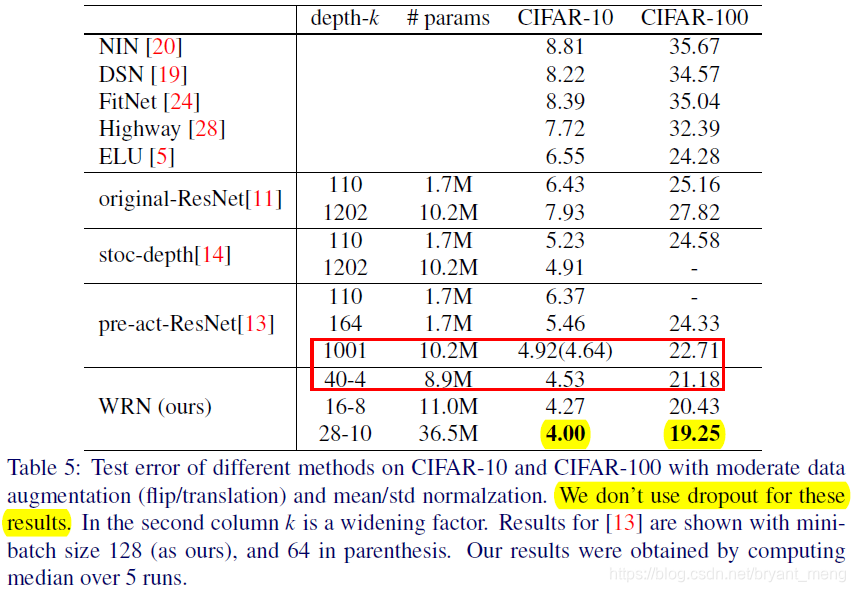
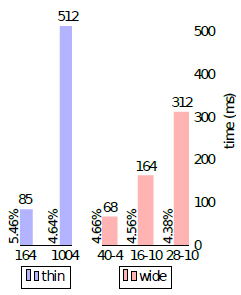
对比红框框当中的两个,WRN-40-4 is faster 8 times faster to train, so evidently depth to width ratio in the original
thin residual networks is far from optimal.

实线 test error,虚线 train error,横坐标 epoch,感觉图例写错了,哈哈,黄色标的部分
4.5 Dropout in residual blocks
0.3 on CIFAR and 0.4 on SVHN
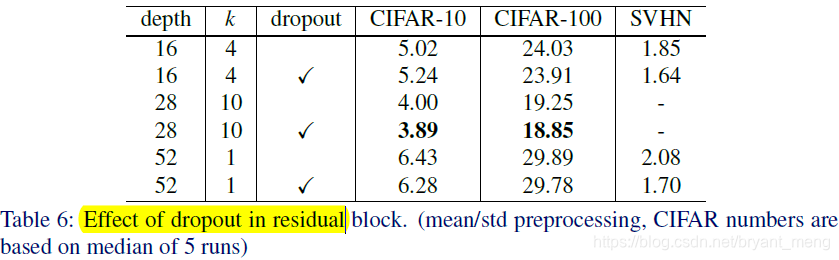
WRN-16-4 下降了,作者 speculate is due to the relatively small number of parameters.
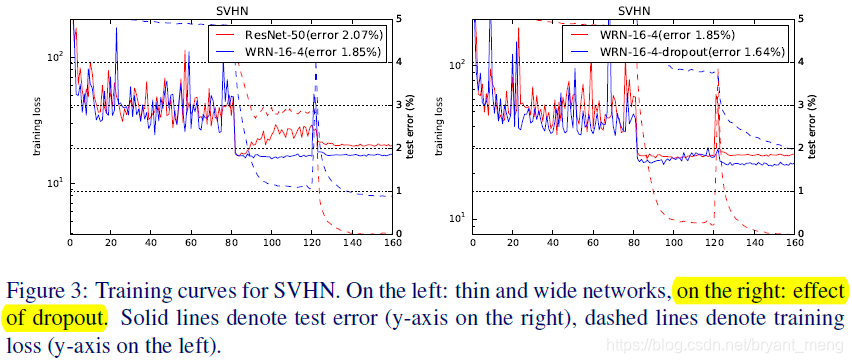
作者发现 train resnet 的时候,train loss 会突然上升,it is caused by weight decay,但是把 weight decay 调小,acc 下降会很多,作者发现 dropout 能解决这个问题!!!对比图3右边红色和蓝色虚线!
作者认为,This is probably due to the fact that we don’t do any data augmentation and batch normalization overfits, so dropout adds a regularization effect. 因为不用 dropout,train loss 会降的特别低!
Overall, despite the arguments of combining with batch normalization, dropout shows itself as an effective techique of regularization of thin(k=1) and wide(k>1) networks.
4.6 ImageNet and COCO experiments
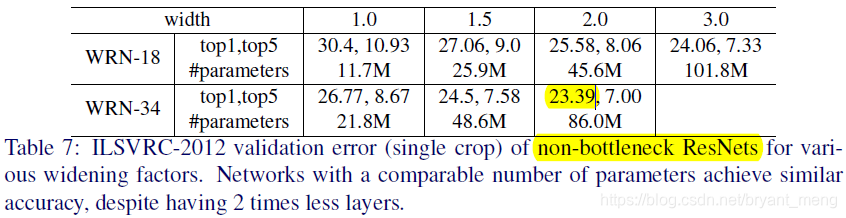

这里 WRN-50-2-bottleneck 难道是把resnet-50 width double了吗?
变成
还是
?
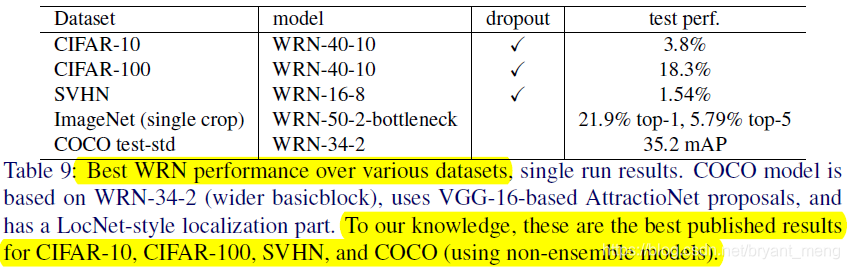
4.7 Computational efficiency

5 Conclusion(owns)
-
diminishing feature reuse problem 被多次提到,也是作者着重要解决的问题,感觉指的是 identity connection 的引入,导致 residual block 可能打酱油的问题!
-
wide residual networks are several times faster to train.
-
作者多次提到了 regularization effect,eg:bn, dropout, width, length 都可以 add regularization effect,前两个好理解,后面两个不好理解耶,有正则化,让网络泛化性能更好?从而表现更好?从这个角度理解?

-
这篇文章仅从 width 下手,《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》这个就从深度、宽度