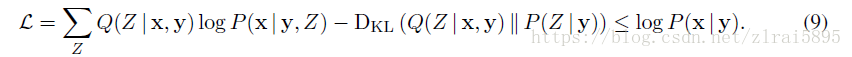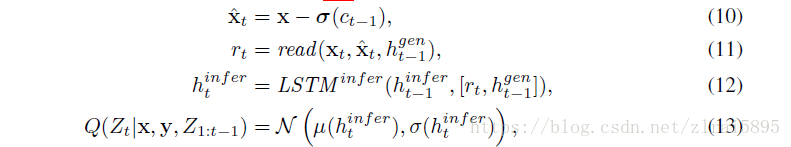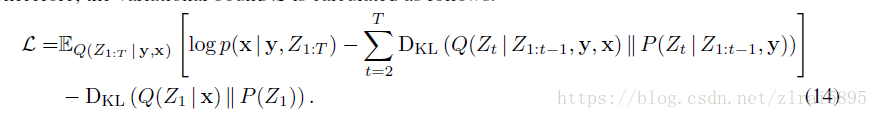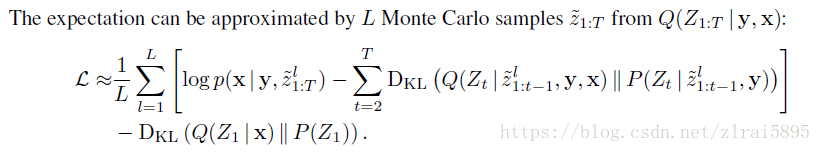介绍文本生成图像的工作.本文要介绍的是发表于 ICLR 2016的论文《GENERATING IMAGES FROM CAPTIONS WITH ATTENTION》 .时间比较早,不同于常见的使用GAN来生成图像,这篇文章使用的方法本质上是一个VAE(变分自动编码器).文章没看太懂...数学推导很高深,但是代码结构很清楚.
论文地址:https://arxiv.org/abs/1511.02793
源码地址:https://github.com/emansim/text2image
一、相关工作
《DRAW: A Recurrent Neural Network For Image Generation》
论文地址:https://arxiv.org/abs/1502.04623
源码地址:https://github.com/ericjang/draw
《GENERATING IMAGES FROM CAPTIONS WITH ATTENTION》对DRAW的结构进行了改进,这里先介绍一下DRAW.
DRAW系统的核心是一对RNN,分别是用于编码图像的编码器和重建图像的解码器.DRAW与其他生成器的不同之处是它不是一次生成图像,而是通过解码器发出的累积修改,迭代地构建场景.
DRAW的基本结构和其他VAE(变分编码器)类似,编码器网络确定潜在变量的分布,潜在变量可以捕获输入数据的信息.解码器网络在潜在变量中接受样本,并使用它们来调整自身在图像上的分布.
但有三个关键的区别:
(1)编码器和解码器都是DRAW中的循环网络,因此在它们之间交换一系列代码样本;编码器对解码器的先前输出有所了解,允许它根据解码器到目前为止的行为定制它发送的变量。
(2)解码器的输出被连续地添加到最终将生成数据的分布中,而不是在单个步骤中发出该分布。
(3)动态更新的关注机制用于限制编码器观察到的输入区域和解码器修改的输出区域。简单来说,网络在每个时间步骤决定“在哪里阅读”和“在哪里写”以及“写什么”。该架构如图2所示,与前馈变分自动编码器一起。
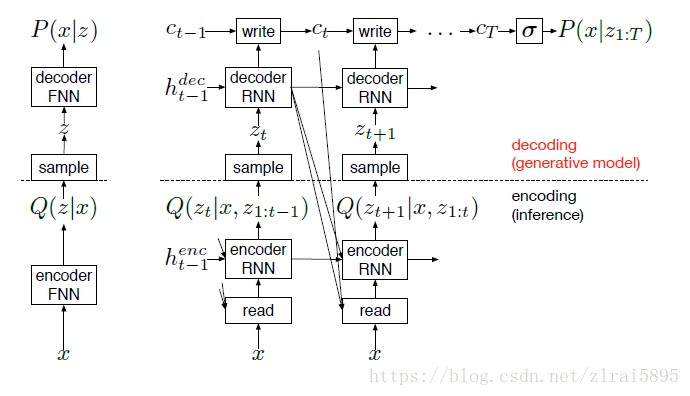
在每一步t,encoder接收image(x)和previous decoder hidden vector
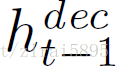
encoder 的输出是
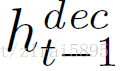
迭代过程如下所示:
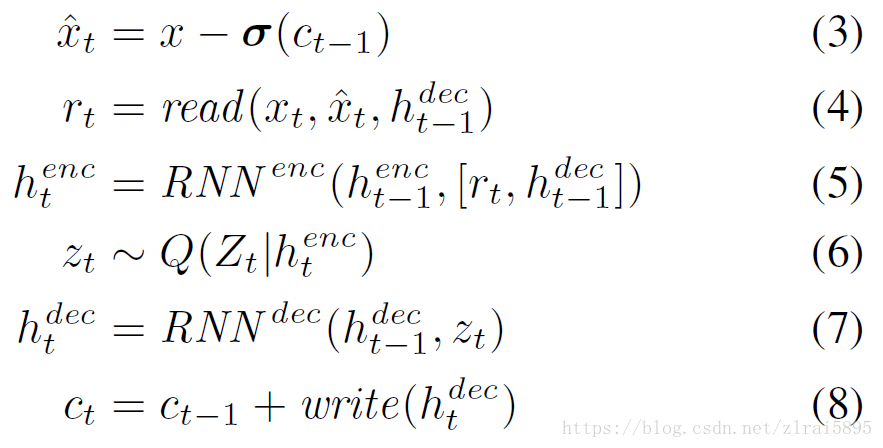
其中read和 write函数:
(1)若不引入attention机制
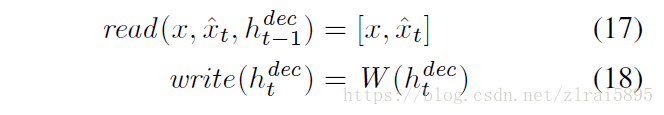
(2)引入attention机制
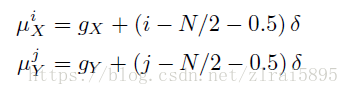
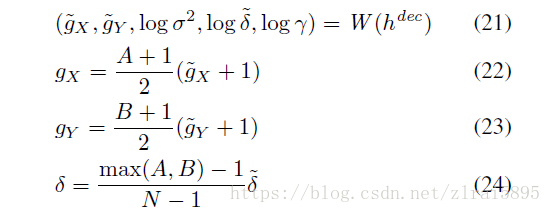
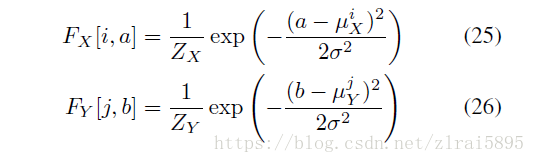
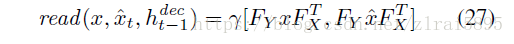
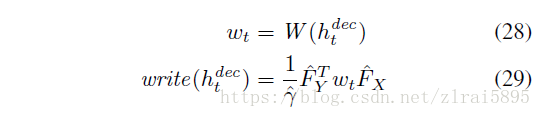
具体含义参考论文(没看懂)
三、数据集
coco数据集
四、模型结构
文章扩展了DRAW,在每一步引入了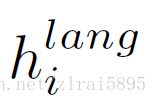
DRAW变为cDRAW,cDRAW是一个stochastic RNN,包含了一些列的z(1,2,3......T),输出是T步的累计。
在cDRAW中,z不再是独立的正态分布,而是依赖前面的LSTM的隐藏态。
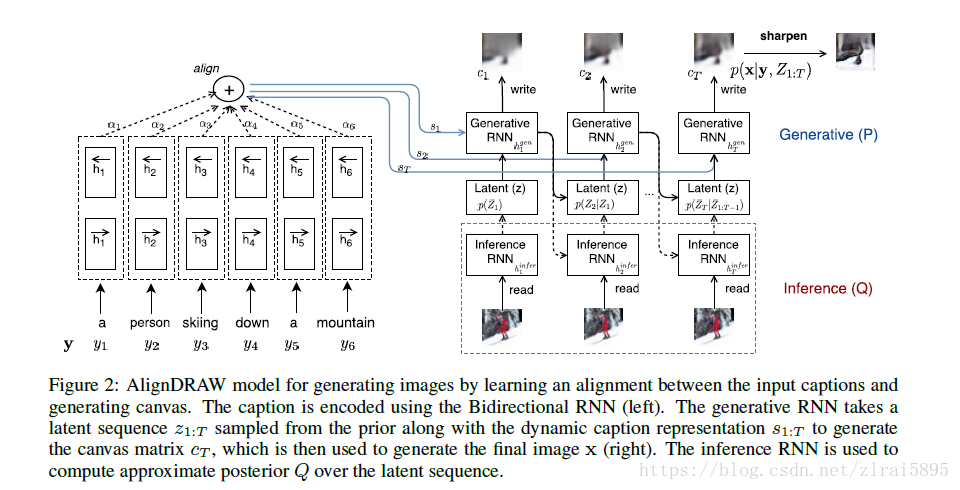

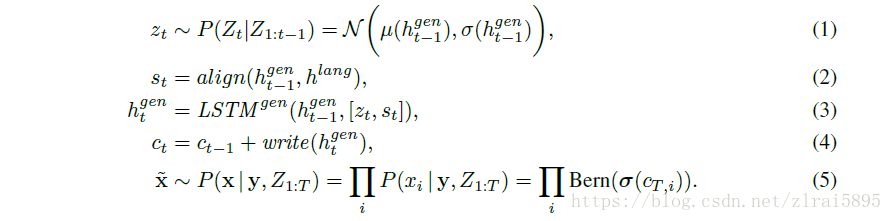
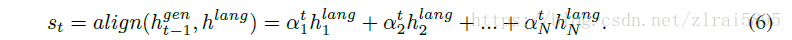
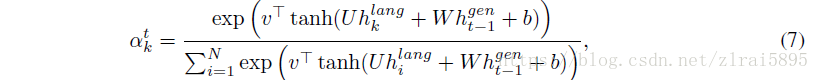
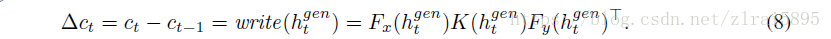
五、损失函数