简介
github
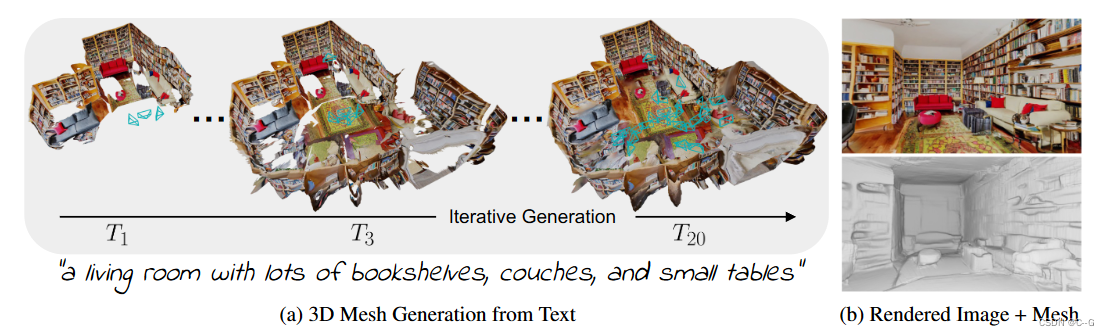
利用预训练的2D文本到图像模型来合成来自不同姿势的一系列图像。为了将这些输出提升为一致的3D场景表示,将单目深度估计与文本条件下的绘画模型结合起来,提出了一个连续的对齐策略,迭代地融合场景帧与现有的几何形状,以创建一个无缝网格
实现流程

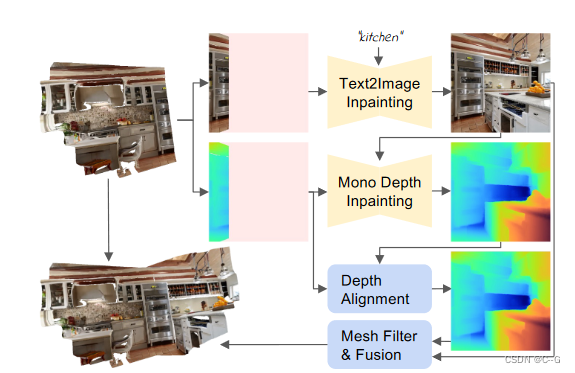
Iterative 3D Scene Generation
随着时间的推移而生成场景表示网格 M = ( V , C , S ) M=(V,C,S) M=(V,C,S),V——顶点,C——顶点颜色,S——面集合,输入的文本prompts { P t } t = 1 T \{P_t\}^T_{t=1} {
Pt}t=1T,相机位姿 { E t } t = 1 T \{ E_t \}^T_{t=1} {
Et}t=1T,遵循渲染-精炼-重复模式,对于第 t 代的每一步,首先从一个新的视点渲染当前场景
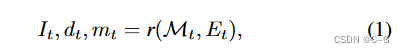
r 是没有阴影的经典栅格化函数, I t I_t It\是渲染的图像, d t d_t dt 是渲染的深度, M t M_t Mt 图像空间掩码标记没有观察到内容的像素
使用文本到图像模型
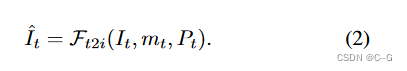
在深度对齐中应用单目深度估计器 F d F_d Fd b来绘制未观察到的深度
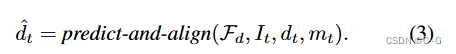
利用融合方案将新内容 { I ^ t , d ^ t , m t } \{ \hat{I}_t,\hat{d}_t,m_t \} {
I^t,d^t,mt} 与现有网格结合起来
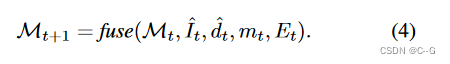
Depth Alignment Step
要正确地结合新旧内容,就必须使新旧内容保持一致。换句话说,场景中类似的区域,如墙壁或家具,应该放置在相似的深度
直接使用预测深度进行反向投影会导致3D几何结构中的硬切割和不连续,因为后续视点之间的深度尺度不一致
应用两阶段的深度对齐方法,使用预训练的深度网络(Irondepth: Iterative refinement of single-view depth using surface normal and its uncertainty),将图像中已知部分的真实深度d作为输入,并将预测结果与之对齐 d ^ p = F d ( I , d ) \hat{d}_p=F_d(I,d) d^p=Fd(I,d)
(Infinite nature: Perpetual view generation of natural scenes from a single image) 优化尺度和位移参数,在最小二乘意义上对齐预测和呈现的差异来改进结果
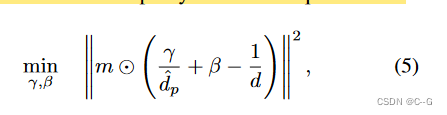
通过 m 屏蔽掉未观察到的像素,提取对齐深度 d ^ = ( y d ^ p + β ) − 1 \hat{d}=(\frac{y}{\hat{d}_p}+\beta)^{-1} d^=(d^py+β)−1,在蒙版边缘应用5 × 5高斯核来平滑 d ^ \hat{d} d^
Mesh Fusion Step
在每一次迭代中插入新的内容 { I ^ t , d ^ t , m t } \{ \hat{I}_t,\hat{d}_t,m_t \} {
I^t,d^t,mt} 到场景中,将图像空间像素反向投影到世界空间点云中
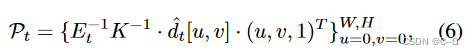
K ∈ R 3 x 3 K \in R^{3 x 3} K∈R3x3 是相机位姿参数,W,H是图像宽高。使用简单的三角测量,将图像中的每四个相邻像素{(u, v), (u+1, v), (u, v+1), (u+1, v+1)}形成两个三角形。
估计的深度是有噪声的,这种简单的三角测量会产生拉伸的3D几何形状。
使用两个过滤器来去除拉伸的面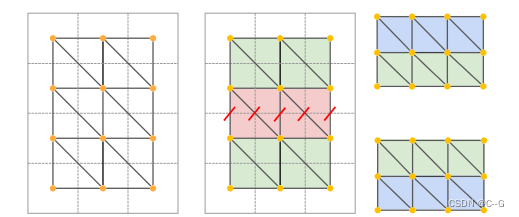
首先,根据边长对面进行过滤。如果任意面边缘的欧几里得距离大于阈值 δ 边缘,则删除该面。其次,根据表面法线与观看方向之间的夹角对面进行过滤
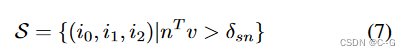
S 是面集合, i 0 , i 1 , i 2 i_0,i_1,i_2 i0,i1,i2 为三角形的顶点指数, δ s n \delta_{sn} δsn为阈值, m ∈ R 3 m \in R^3 m∈R3 是归一化法线, v ∈ R 3 v \in R^3 v∈R3 为世界空间中从相机中心到三角形起始平均像素位置的归一化视角方向,这是避免了从图像中相对较少的像素为网格的大区域创建纹理
最后将新生成的网格补丁和现有的几何形状融合在一起,所有从像素中反向投影到绘制蒙版 m t m_t mt 中的面都与相邻的面缝合在一起,这些面已经是网格的一部分,在 m t m_t mt 的所有边缘上继续三角剖分方案,但使用 m t m_t mt 的现有顶点位置来创建相应的面
Two-Stage Viewpoint Selection
一种两阶段的视点选择策略,该策略从最优位置采样每个下一个摄像机姿态,并随后细化空区域
Generation Stage
如果每个轨迹都从一个具有大多数未观察区域的视点开始,那么生成效果最好。这会生成下一个块的轮廓,同时仍然连接到场景的其余部分
将摄像机位置 T 0 ∈ R 3 T_0∈R^3 T0∈R3 沿注视方向 L ∈ R 3 L∈R^3 L∈R3 进行均匀的平移: T i + 1 = T i − 0.3 L T_{i+1}=T_i−0.3L Ti+1=Ti−0.3L,如果平均渲染深度大于0.1,就停止,或者在10步后丢弃相机,这避免了视图过于接近现有的几何形状
创建封闭的房间布局,通过选择以圆周运动生成下一个块的轨迹,大致以原点为中心。发现,通过相应地设计文本提示,可以阻止文本到图像生成器在不需要的区域生成家具。例如,对于看着地板或天花板的姿势,我们分别选择只包含单词“地板”或“天花板”的文本提示
Completion Stage
由于场景是实时生成的,所以网格中包含了没有被任何相机观察到的孔,通过采样额外的姿势后验完成场景
将场景体素化为密集的均匀单元,在每个单元中随机取样,丢弃那些与现有几何太接近的,为每个单元格选择一个姿态,以查看大多数未观察到的像素,根据所有选择的相机姿势绘制场景
清理绘制蒙版很重要,因为文本到图像生成器可以为大的连接区域生成更好的结果
首先使用经典的绘制算法绘制小的孔,并扩大剩余的孔,移除所有落在扩展区域并且接近渲染深度的面,对场景网格进行泊松曲面重建。这将在完井后关闭任何剩余的井眼,并平滑不连续性。结果是生成的场景的水密网格,可以用经典的栅格化渲染
Result


Limitations
方法允许从任意文本提示生成3D房间几何形状,这些文本提示非常详细并且包含一致的几何形状。然而,方法在某些条件下仍然可能失败。首先,阈值方案可能无法检测到所有拉伸的区域,这可能导致剩余的扭曲。此外,一些孔在第二阶段后可能仍未完全完井,这导致在应用泊松重建后出现过平滑区域。场景表示不分解光线中的材料,光线会在阴影或明亮的灯中烘烤,这是由扩散模型产生的。