最近OpenAI出了DALL·E和CLIP,前者还没开源但是后者开源了,所以先看看CLIP。
本篇梳理和记录了一下OpenAI官方博客的内容,细节的内容还需看看原文。很多参考了大佬的CLIP介绍文章,感恩。
CLIP一句话总结:zero-shot做得好,可以自定义任务,而且效率很高。
相关链接:
OpenAI CLIP的博客
CLIP 的 github
零次学习(Zero-Shot Learning)入门
CLIP 的 colab
CLIP 的 paper
OpenAI DALL·E 的博客
(paper和colab github也给出了链接)
现在cv存在的问题:
- 数据集制作成本高
- 模型只会一种任务,成本又大,而且在其他任务做得不好
在benchmarks效果好的任务,在压力测试中表现差(换了个数据集就表现得不好)
因此提出CLIP模型,它可以缓解三个问题:
- Costly datasets:之前大部分模型用的数据集都是人标的,而CLIP的训练数据都是从网上找的,用纯文本作为label,减少了人力成本
- Narrow:根据有标注数据集训练的话输出是有限的,比如数据集只教模型预测猫和狗,那就没法再让模型去预测鸭子,而CLIP在常见图像上就不受限制
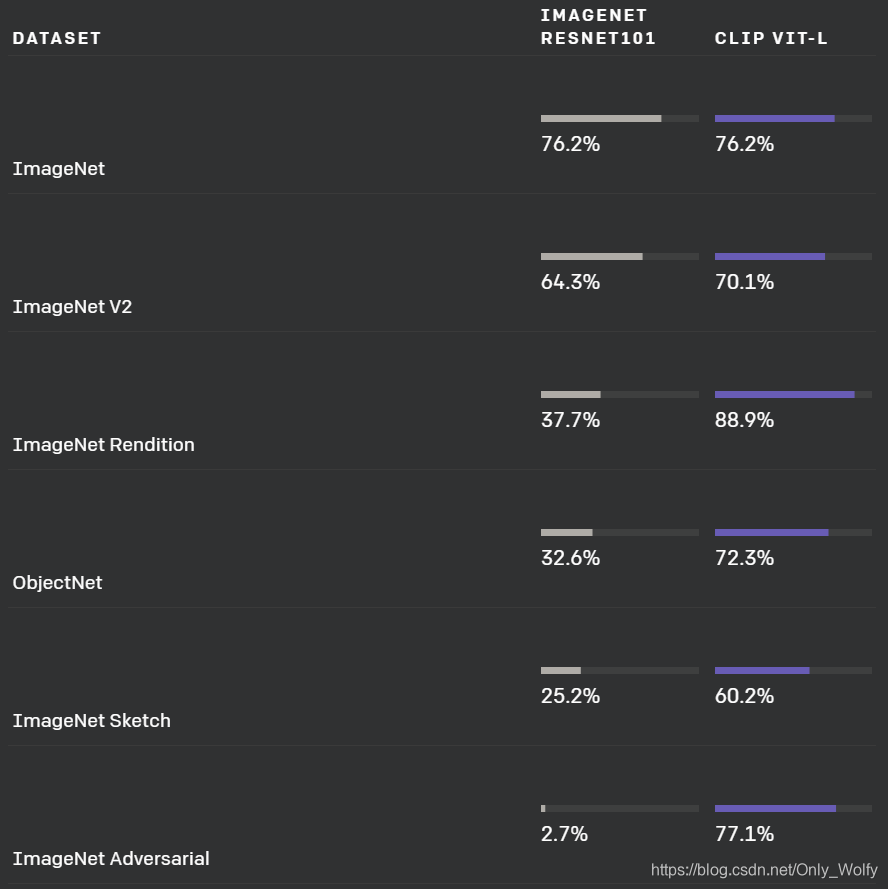
- Poor real-world performance:benchmark和真实情况都是有gap的,在benchmark上表现好不意味着真实情景也好。而CLIP不是从某个特定数据集学出来的,可以缓解这个问题。作者也通过实验证实,如果面向ImageNet学习的话,虽然评估效果会提高,但其他7个数据集上都不太好。
CLIP 优点&特点:
- 总结:zero-shot做得好,经过在400million大的未清洗的数据集上训练,在不同的数据集上表现还可以,可以自定义任务,而且效率很高。
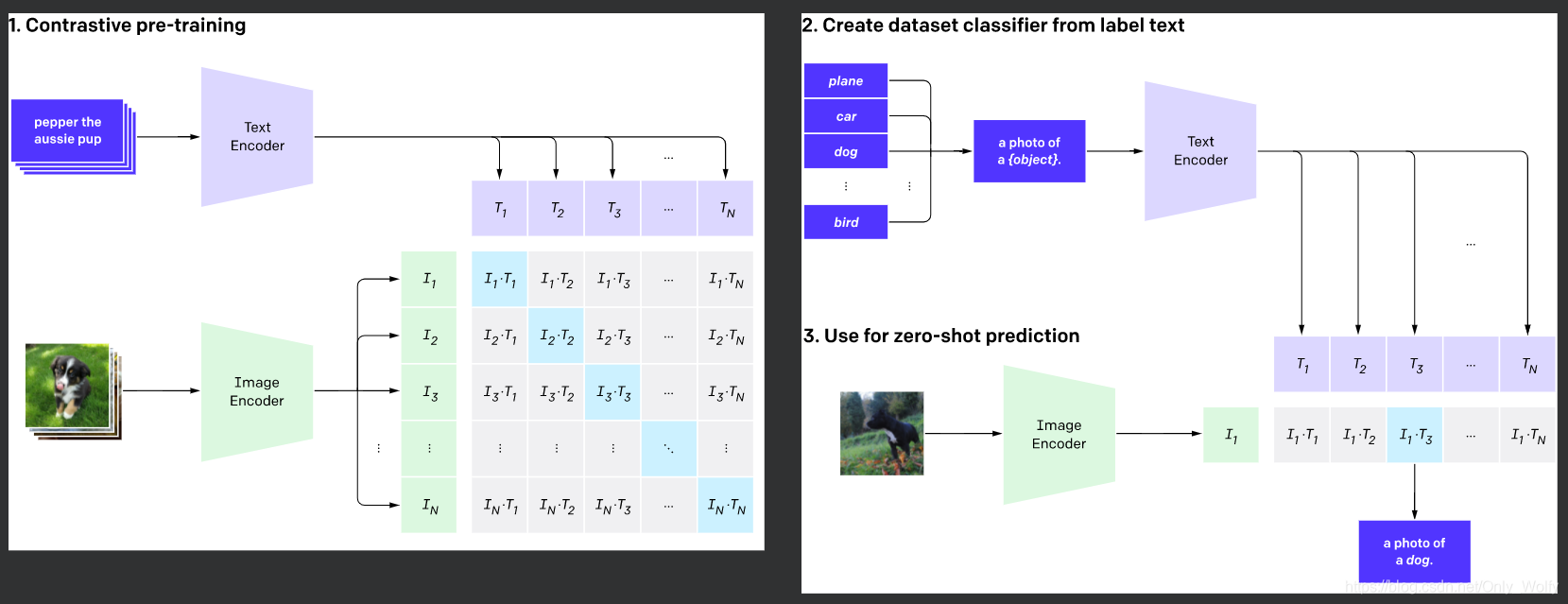
- OpenAI从网上搜集了400million未清洗的图像-文本pair数据,用对比学习目标进行训练:分别对图像和文本编码,然后两两计算cosine相似度,再针对每个图片的一行或文本的一列进行分类,找出匹配的正例。
- highly efficient 高效:虽然GPT3做zero-shot也很好,但是CLIP吃的资源少,计算量少,训练效率高。最好的一版CLIP只在256个GPU上训练两周就好了,跟目前图像领域的其他大模型都差不多。
两种提效方法:
Contrastive learning Objective:如文章开头的图,比起语言模型那样一个个预测文本描述,对比学习可以提效4到10倍
VisionTransformer:直接把图像分成一个个patch,再过Transformer,比起ResNet编码提效3倍(真·Attention is all you need) - flexible and general 灵活和通用:因为他们直接从自然语言中学习广泛的视觉概念,CLIP明显比现有的ImageNet模型更灵活和通用。我们发现他们能够轻松地完成许多不同的任务。为了验证这一点,我们在超过30个不同的数据集上测量了CLIP的零拍性能,包括任务,如细粒度对象分类、地理定位、视频动作识别和OCR。
CLIP 缺点:
- 虽然CLIP通常在识别普通物体方面表现良好,但在更抽象或更系统的任务上却表现不佳。比如计算图像中物体的数量,以及在更复杂的任务上,比如预测照片中最近的汽车距离有多近。在这两个数据集上,零射剪辑只比随机猜测好一点点。与特定任务模型相比,Zero-shot CLIP在非常细粒度的分类上也很困难,比如区分汽车模型、飞机变体或花卉种类之间的区别。
- 对于未包含在其预训练数据集中的图像,CLIP的泛化效果也很差。例如,尽管CLIP学习了一个有效的OCR系统,但当从MNIST数据集评估手写数字时,zero-shot CLIP仅达到88%的准确率,远低于数据集上99.75%的人的准确率。(其实还行,毕竟不是专门在MNIST上跑的)
以上缺点,感觉投喂更多相应的数据就能解决。不过会增加训练时间。
模型图:
zero-shot 效率高,准确度也高:
